

Reinforcement Learning Techniques to Optimize Agents
Can RL loops continuously refine prompts, tools, and agentic pipelines?

Every startup and org today is likely building an agent. And it’s become remarkably easy to build them with off the shelf tools:
Building agents - Langgraph, Crew, Autogen
Observation & Evaluation - Langsmith, Langfuse, Opik
However, while tools exist for building and monitoring agents, there is a lack of widely adopted frameworks for systematically improving them based on user interactions.
Key problem: How do you continuously improve an agent’s prompts, tools, flow, and end-to-end experience based on user interactions?
I’ve split my experimentation on this into two parts. This article is part-1, in which I cover:
Basics principles of reinforcement learning (RL)
How RL is used is used in training LLMs
A concept for applying RL to improve agents
A teaser of the framework I’m building for this, including illustrative code snippets
In the second part, I plan to publish the prototype of the framework as a python library, along with an analysis of a little-known, but promising tool in this space - Handit.ai.
Reinforcement Learning Basics
When trying to address the key problem that I stated above - the first candidate solution that comes to mind is Reinforcement Learning.
For readers that are unfamiliar with the term:
Reinforcement learning (RL) is a branch of machine learning in which an agent learns to make decisions by interacting with an environment, receiving feedback in the form of rewards or penalties, and adjusting its actions to maximize cumulative reward over time
Here - in the generic sense - an agent is a decision-making entity that interacts with the environment.
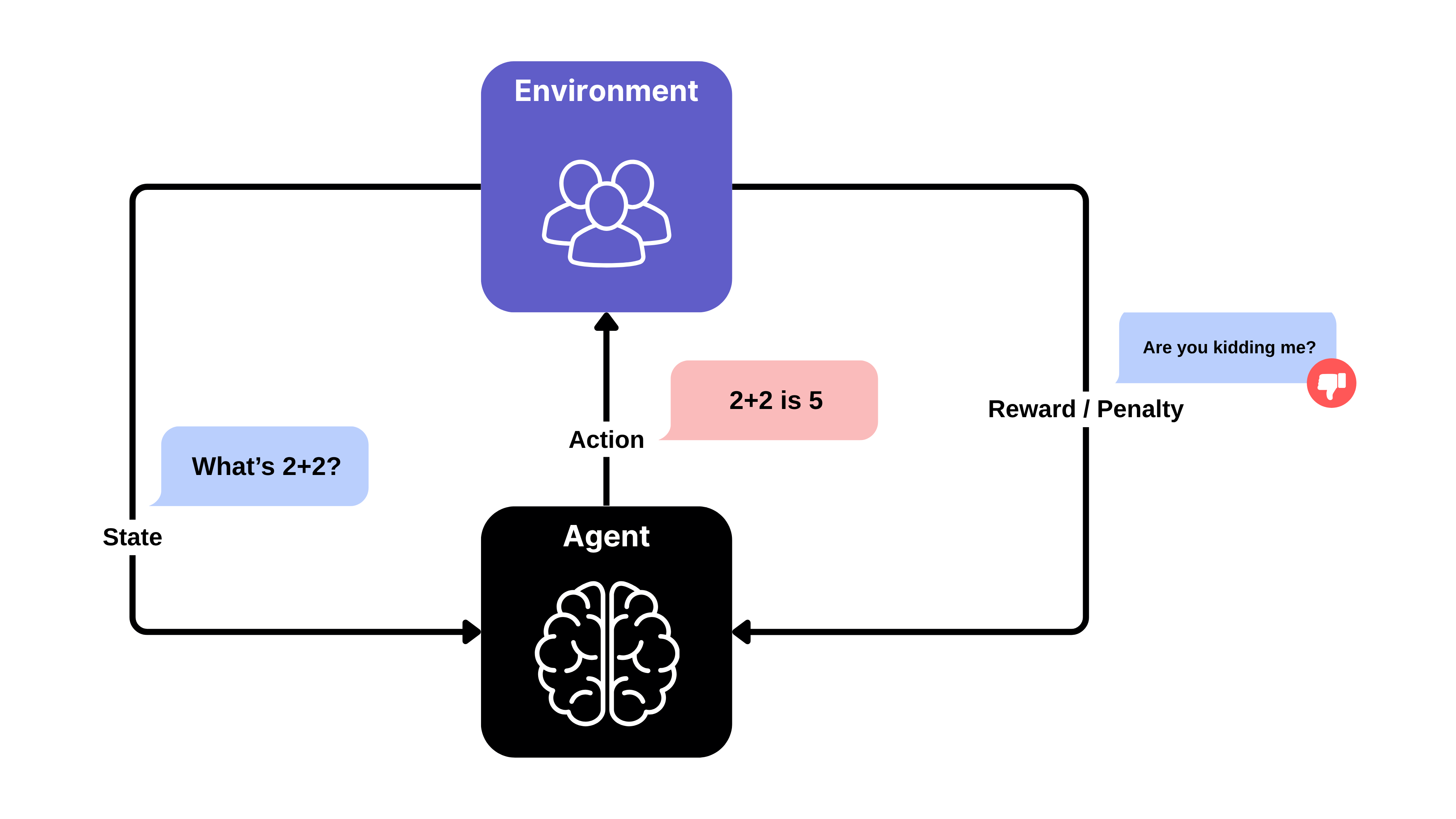
In our case, if the agent were a chatbot:
Environment: The environment would be the conversation itself, including the user who interacts with the chatbot, and the rules or context in which the dialogue happens.
State: The state is the current context of the conversation -this could include the most recent user message, previous exchanges (conversation history), user metadata, and any inferred intent or sentiment.
Action: The action is the response or message that the chatbot generates and sends back to the user.
Reward: The reward is feedback that measures how well the chatbot’s response achieved the desired outcome. In practice, this could be explicit (e.g., user thumbs-up, rating) or implicit (e.g., continued conversation, clicks, task completion, sentiment of user’s next message).
RL in Training LLMs
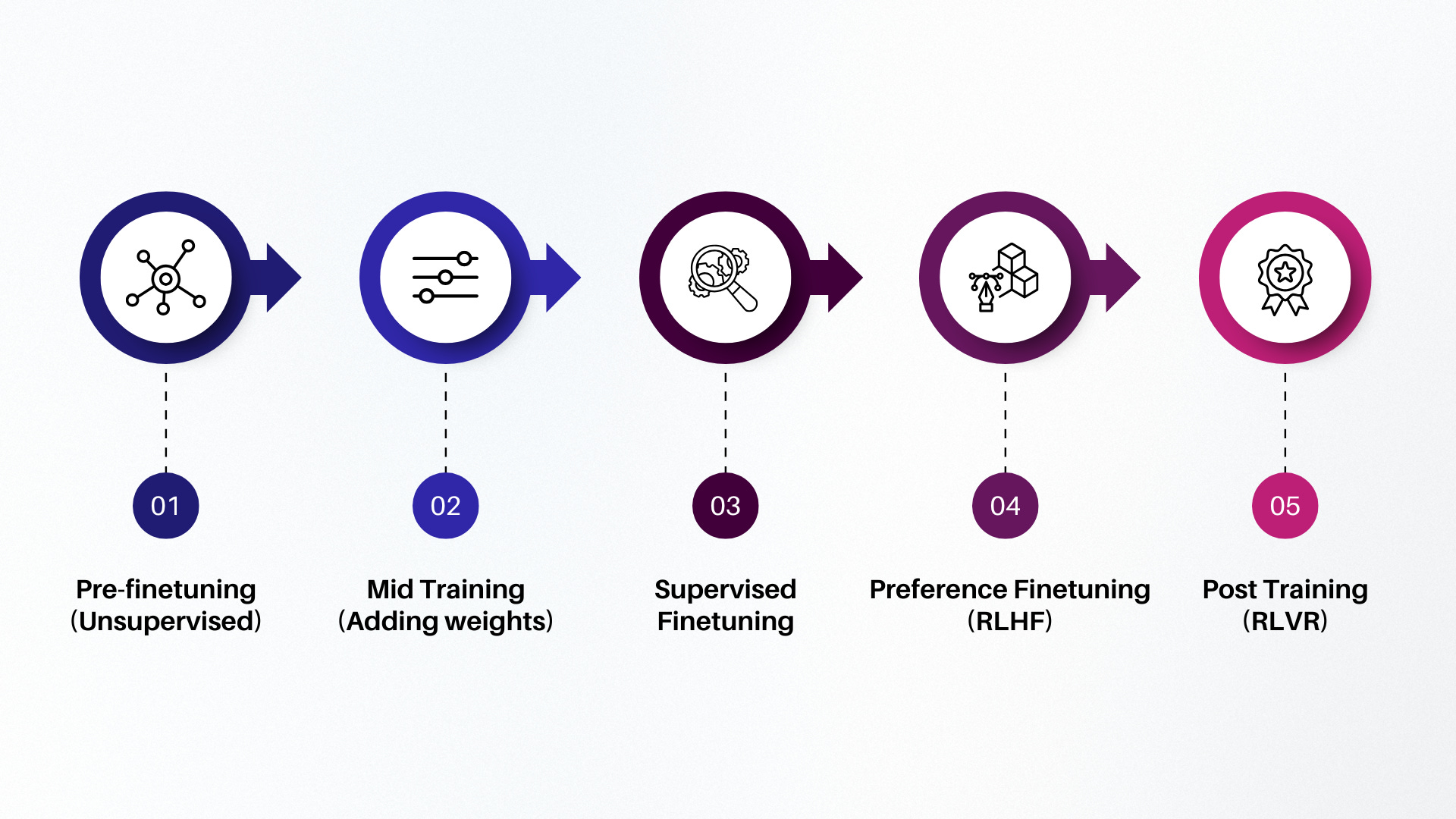
LLMs undergo a multi‑stage training process, typically including:
Pre‑Finetuning: Train on massive, diverse datasets to build broad language understanding.
Mid Training: Adjust via checkpointing, data curation, and scaling refinements.
Supervised Finetuning: Teach task‑specific behavior using labeled human‑curated examples.
Preference Finetuning (RLHF): Tune model weights with human preferences using reinforcement learning from human feedback.
Post‑Training RLVR: Further refine with reward models (e.g., rule‑ or value‑based) to reduce hallucinations and enforce safety.
The key challenge in reinforcement learning is to have a solid training dataset (user preference data) and an accurate reward model.
RL Techniques for Optimizing Agents
What we commonly refer to as “agent” today, is essentially a piece of software that is capable of (largely) autonomously taking an action or sequence of actions.
Present day agents, while commonly dependent on LLMs for their AI features, are architecturally different from language models or ML models.
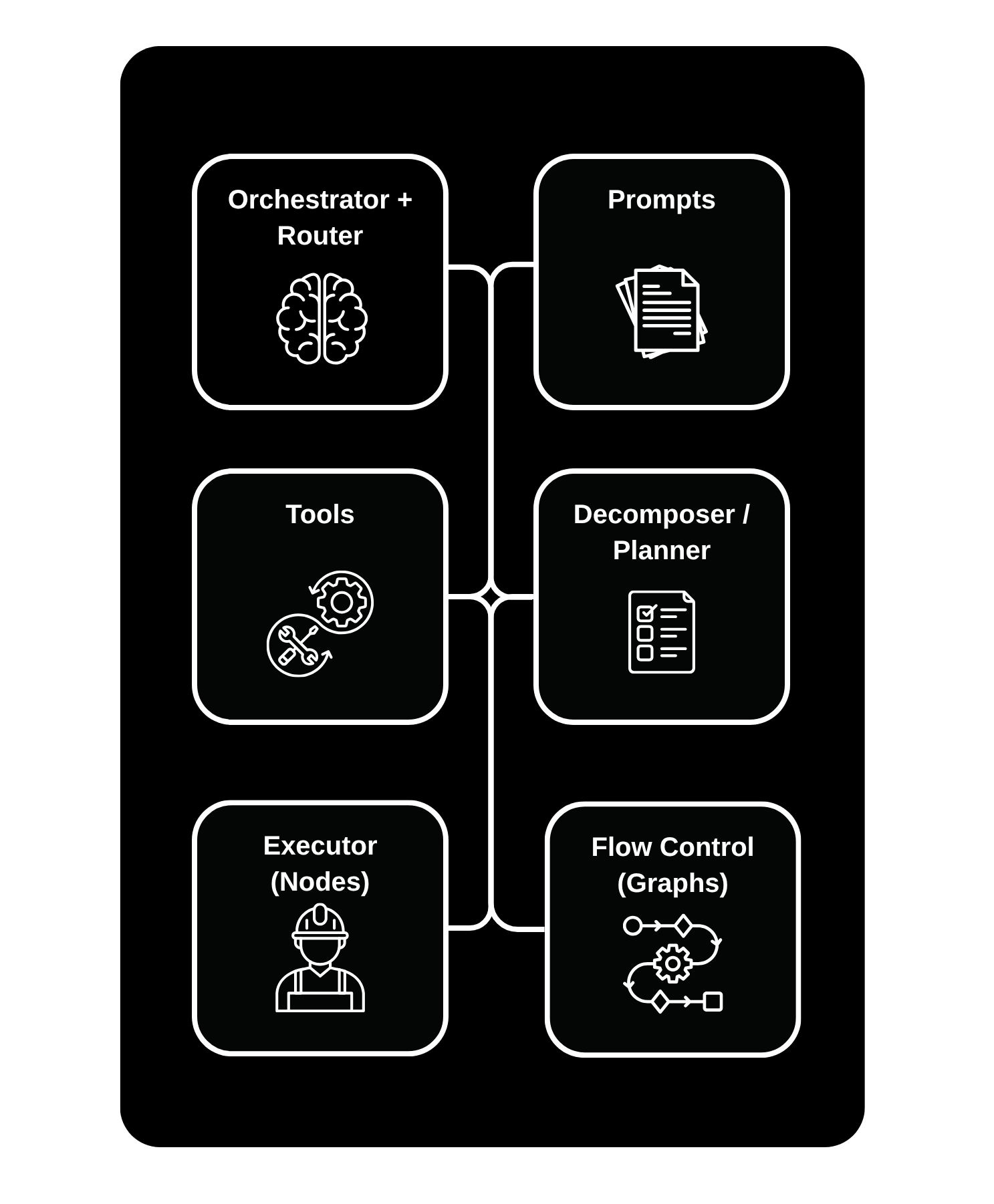
A typical agent has the following components:
Orchestrator / Router - Directs queries to the right components, models, or workflows.
Decomposer / Planner
Breaks complex tasks into smaller steps and organizes the execution plan.Prompts - Provide structured instructions or context to guide the model’s responses and behavior.
Tools - Utility functions, APIs, or utilities the agent can call to extend its capabilities beyond text generation.
Executors - Carries out the planned steps, executing actions, queries, or calculations.
Flow Control (Graphs) - Manages logic and dependencies between tasks, ensuring correct sequencing and conditional branching.
The key distinction between RL for agents and RL for LLMs or ML models is that with an agent, you’re not merely tuning weights. You’re actually trying to improve the source code.
This makes it a completely different problem to tackle, where the traditional RL frameworks don’t fit. The concept works, but the method has to be different.
Last week, I was looking into code evolution techniques with OpenEvolve, and it felt like a solid candidate to consider for the agent improvement use case.
Code Evolution Based “Agent RL” Setup
OpenEvolve works in a very RL’esque manner:
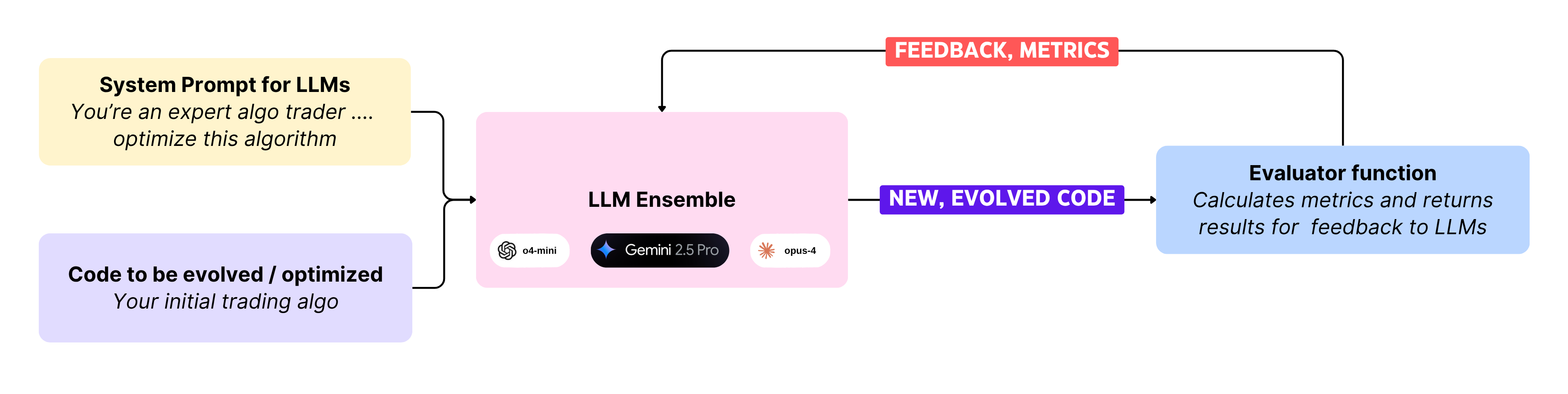
You have the code that you want to improve or optimize - your prompts, tools, orchestrator nodes, etc.
Write a system prompt for the LLMs, providing context, objectives, and instructions.
Configure an ensemble of LLMs that you will use - including, but not limited to OpenAI, Gemini, Claude, and Qwen models.
An evaluator function (reward model) that grades all evolutions of the algorithm. This should provide key metrics that need to be maximized - You essentially maximize the reward metrics and minimize the penalty metrics.
The one constraint? OpenEvolve doesn’t work on entire codebases. It works on one function or file at a time
One thing is clear: an agent is as good as the sum of it’s pieces, and so if one were to individually optimize the prompts, the tools, and so on, one would eventually arrive at a better end-to-end experience.
The challenge then became how to create a generic system that could improve the entire agent, or at least the key parts of it that needed improvement.
Enter the agent-evolve toolbelt, a custom cli tool that I’m developing to solve for typical agent evolution use cases.
Agent-Evolve
The framework automates a few key aspects:
Auto-extracts prompts and code to be improved into a staging area for evolution
Generates synthetic datasets for evaluation
Generates use-case specific evaluators (reward functions) for each evolution target
Executes the evolution
Upcoming: RLHF-style optimization - Uses input-output message data to augment evaluation datasets, which are then fed as training data to the reward function when evolving the code
Evolution candidate extraction
Using a custom @evolve() decorator, you can tag any prompt or tool in your codebase as a candidate for improvement.
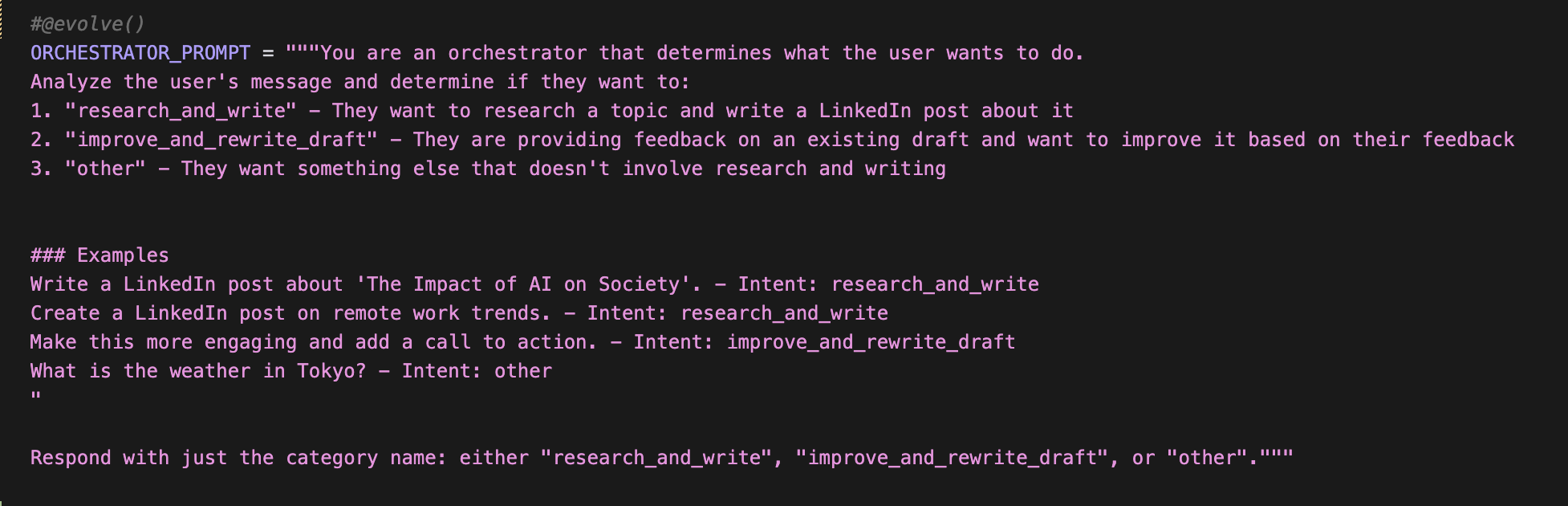
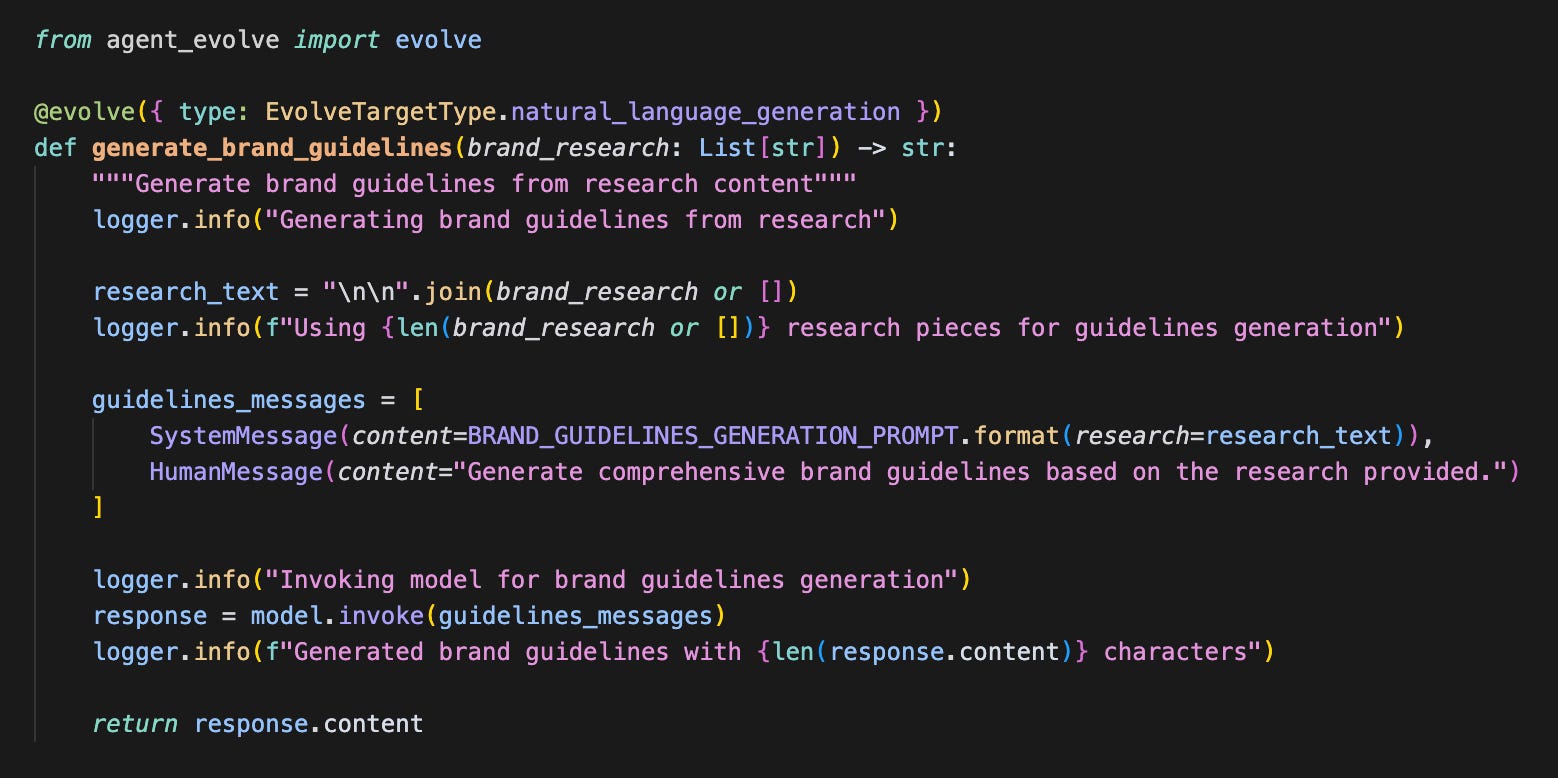
Once you’ve decorated all the candidates for evolution in your codebase, run agent_evolve extract_targets to stage all the code with it’s dependencies for analysis. This not only stages the code to be evolved, but also it’s dependency tree, so that it can run in isolation.
Test Data Synthesis
Once the evolution targets are all extracted to the staging directory, the next step is to generate synthetic training data. This is LLM driven, and depends on Open AI, but can easily be adapted to an alternative provider.
agent_evolve generate_training_data —num-samples 30
Generating Evaluators
The evaluators, in combination with the training data are a critical piece of this setup. AgentEvolve generates evaluator code based on the evolution target.
agent_evolve generate_evaluators
A key point to note is that while some evaluators work great, other ones are average, and so for optimal outcomes, it’s best to inspect and manually work on the evaluator itself.
Start the Evolution
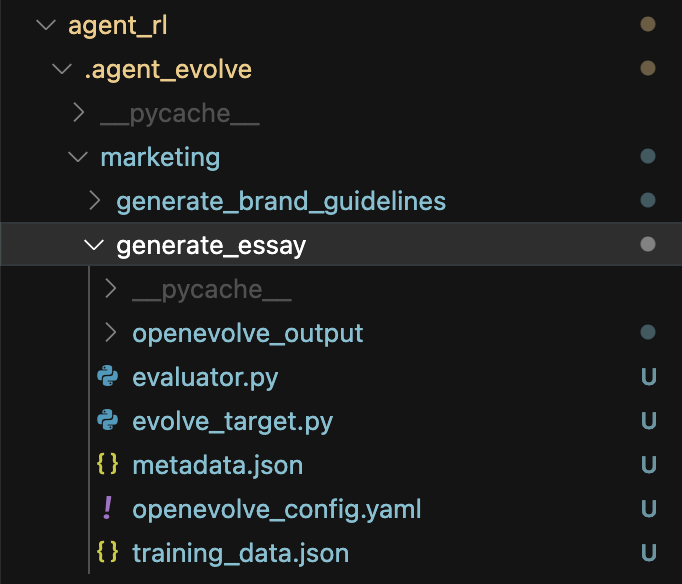
At this stage, you should have the evolve_target, the evaluator, the training_data, and the open_evolve config.yaml.
We’re now ready to begin the evolution using openevolve.
agent_evolve run_openevolve —target generate_essay
This will start off the open evolve evolution, and end with an evolved version of your target code that maximizes the reward function.
RLHF Setup - Work In Progress
To create a more “real data” driven learning, I created a custom decorator that can be used to stream all human and AI messages to a separate PSQL database.
The goal is to then repurpose this data into a second training dataset for the reward function.
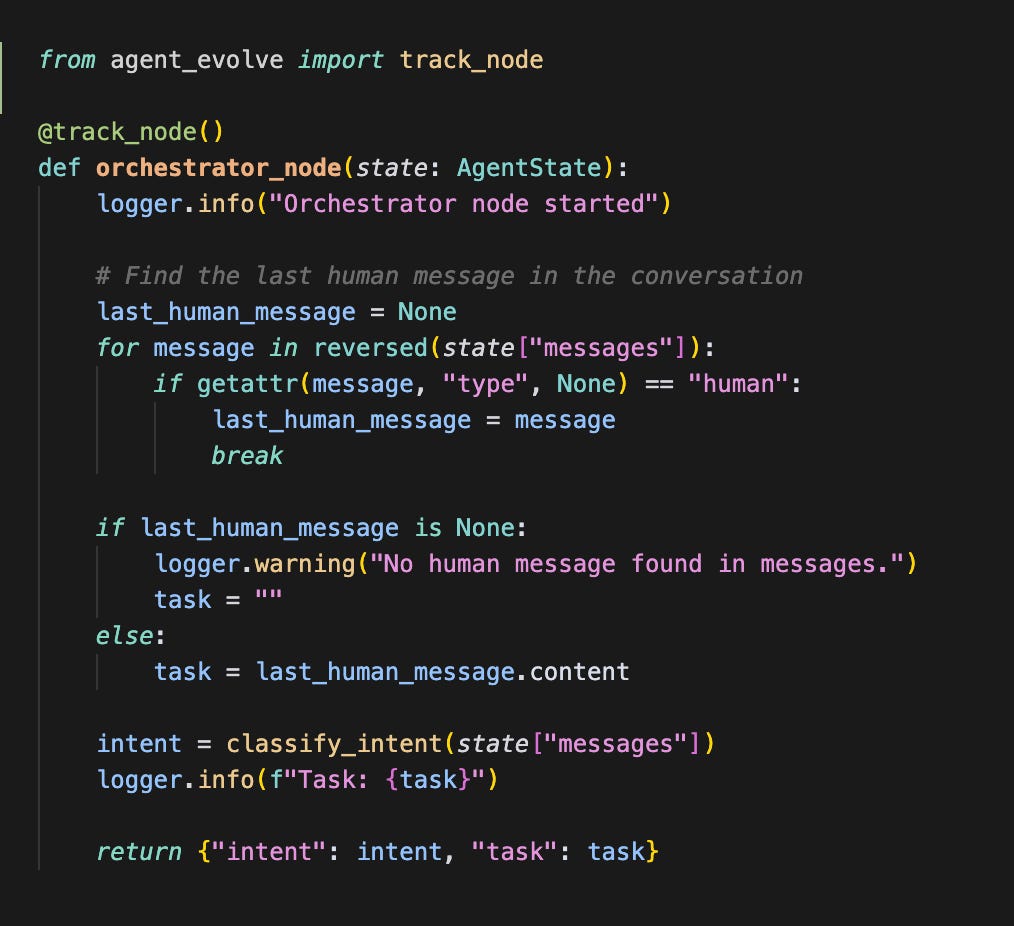
This results in a table with a message log and an operation log of every interaction with the agent.
Next Steps
I’ve been working on AgentEvolve for under a week, and accordingly, there’s a significant degree of brittleness and feature limitation. Over the coming days, I intend to:
Wire up the human feedback loop to the training data
Bootstrap a minimal UI to compare evolved vs original code with diffs
Patch the breaking points, complete and publish the cli tool
Publish some measurable performance metrics on end-to-end agent behavior
If you’re building an agent - I’d value your comments on the premise, the setup, and the value of such a tool. I’m also looking for your suggestions on what could make it better.
1. Are there standard rules you apply to ensure your evolutions are configured precisely as desired?
2. Also, do you keep improving your @evolve with every article, am I correct thinking this version incorporates all the best from the previous one + the new stuff? (Really asking for a friend, who keeps feeding your code to their Claude Code to keep evolving their every demo)