

Auto-Improve Bitcoin Algo Trading Strategies with LLMs
How to Build & Auto-Refine Algorithms Using Multi-Model LLM Loops

Building effective algorithmic and quantitative trading strategies is a deeply iterative process. Arriving at a viable algorithm for trading requires an evolution of code and parameters through tens of thousands of iterations.
I came across two promising tools while researching automated generation for coding use cases such as SQL fine tuning, and ETL optimization:
Google Deepmind’s AlphaEvolve - A Gemini-powered coding agent for iteratively designing advanced algorithms, announced in Jun 2025.
OpenEvolve - An open-source implementation of AlphaEvolve
While experimenting with these, the (novice) quantitative trader in me connected the dots and asked the question - Can we actually evolve trading algorithms iteratively using such tools?
Yes. I was able to evolve a naive algorithm from a negative -2.06 sharpe to a +3.99 sharpe
Now does that mean I can go live with that algorithm on the market and begin to make money tomorrow? No. But it shows very significant potential.
I’m breaking down this article into two sections:
For the strictly trading oriented folks - How I used OpenEvolve to refine and improve a naive Bitcoin trading algorithm.
For the more engineering oriented folks - How OpenEvolve works under the hood - architecture, features, and code. Other use cases such as SQL tuning.
Evolving a Trading Algorithm
The typical process for building a viable trading algorithm looks something like this:
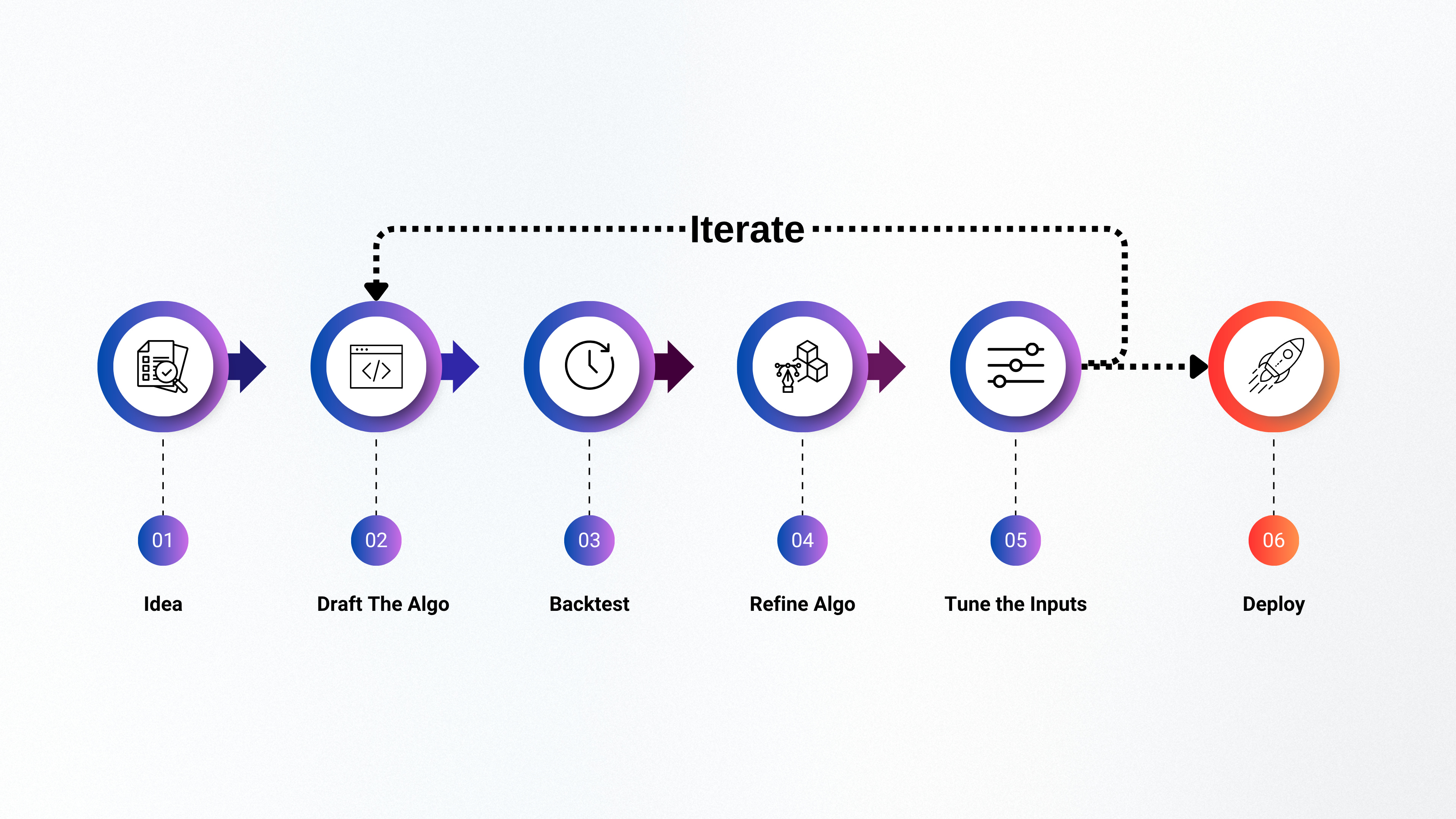
Idea - Every trader has an idea they want to explore and try on the markets
Draft the algo - Write the algorithm in code, oftentimes in python.
Backtest - Test this algorithm against historic data to validate its efficacy
Refine the algo - Make improvements to the algorithm based on backtest results
Parameter tuning - Tune the input parameters of your algorithm for better results
Iterate - Incorporate refined algorithm and parameters in the code
Deploy - Finally deploy the algorithm to the markets when you’re happy with the backtest results. The process doesn’t end here → you continue to refine and iterate.
Section 1: Using OpenEvolve To Auto-Refine Trading Algos
Evolving a trading algorithm is cumbersome. Not only does it require significant brainwork, it also requires heavy duty grunt work.
Sometimes you make tweaks to the logic. Other times, you throw away your entire premise, and start from scratch.
In both cases - the cognitive load is high, and the effort is rather mind numbing - making this a great candidate for automation.
OpenEvolve is an open source code evolution/optimization tool based on 📄Google Deepmind’s proprietary AlphaEvolve paper, and built for such use cases.
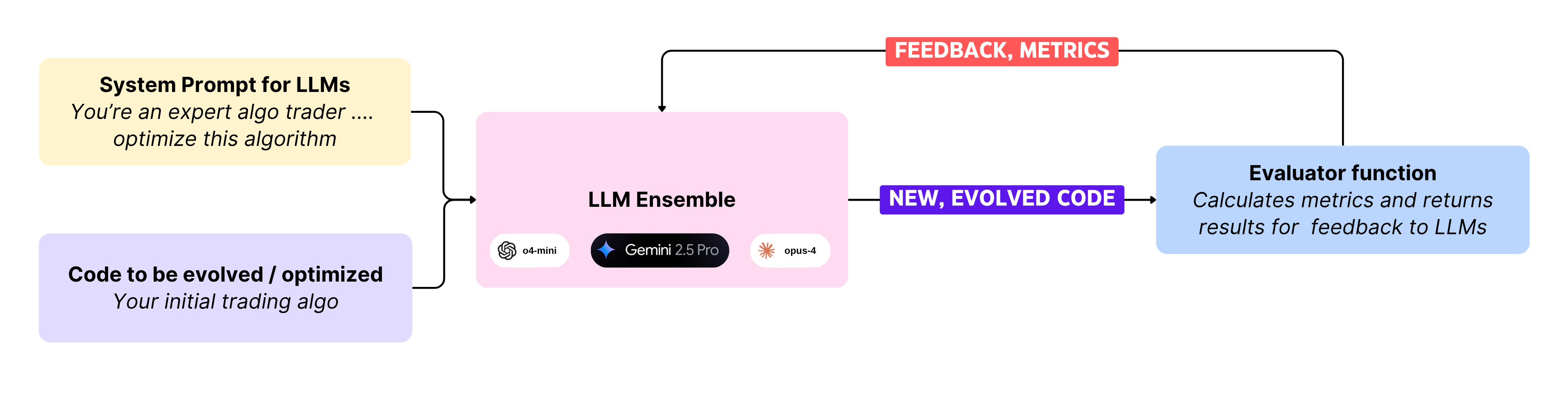
To run OpenEvolve, you require the following components.
The code that you want to improve or optimize - your BTC trading algorithm.
The system prompt for the LLMs, providing context, objectives, and instructions.
A set of LLMs that you will use - including, but not limited to OpenAI, Gemini, Claude, and Qwen models. You may use one to many, each assigned a weight.
An evaluator function that grades all evolutions of the algorithm. This is your actual backtest, and should provide key metrics such as:
Sharpe ratio
Annualized returns
Max drawdown
…
Initial Algorithm: Negative -2.06 sharpe
I generated the initial algo completely with Chat GPT. It performs a momentum-based trading signal generation for Bitcoin using a few technical indicators:
Computes MACD, RSI, ATR, and 200-day SMA indicators using the
talibrary.Identifies potential trade entries by detecting bullish/bearish MACD crossovers, confirming trend with RSI and SMA conditions.
Calculate stop-loss and take-profit levels based on ATR, returning "long" or "short" signals when criteria are met.
# Get the OHLC data from Yahoo Finance
import yfinance as yf
# ta library for indicators
from ta.trend import MACD
from ta.momentum import RSIIndicator
from ta.volatility import AverageTrueRange
# Calculate indicators
def add_indicators (df):
print("df.head()")
print(df.head())
macd_ind = MACD(close=df["Close"])
df["macd"] = macd_ind.macd()
df["macd_signal"] = macd_ind.macd_signal()
df["rsi"] = RSIIndicator(close=df["Close"]).rsi()
df["atr"] = AverageTrueRange(high=df["High"],
low=df["Low"], close=df["Close"]).average_true_range()
df["sma200"] = df["Close"].rolling(window=200).mean()
print("df.head()")
print(df.head(300))
return df
# Generate Entry/Exit signals
def generate_signal(df, i):
"""Returns ('long' | 'short' | None, stop_loss, take_profit)"""
row = df.iloc[i]
prev = df.iloc[i - 1]
# Long setup
if (
prev["macd"] < prev["macd_signal"]
and row["macd"] > row["macd_signal"]
and 50 < row["rsi"] < 70
and row["Close"] > row["sma200"]
):
sl = row["Close"] - 1.5 * row["atr"]
tp = row["Close"] + 3 * row["atr"]
return "long", sl, tp
# Short setup
elif (
prev["macd"] > prev["macd_signal"]
and row["macd"] < row["macd_signal"]
and 30 < row["rsi"] < 50 and row["Close"] < row["sma200"]
):
sl = row["Close"] + 1.5 * row["atr"]
tp = row["Close"] - 3 * row["atr"]
return "short", sl, tp
return None, None, NoneEvaluator: Runs Backtests & Calculates Metrics
The evaluator function runs the actual backtests, and calculates metrics that indicate how well the algorithm performs. For this experiment, I used only a couple of key metrics - Sharpe ratio, annualized return, and max drawdown. In a more rigorous use case, one could optimize for a larger number of metrics.
All of the backtests were run from Jan 2021 - June 2025 on BTCUSD daily candles
The key metrics returned by the evaluator look something like this:
def evaluate(program_path: str) -> Dict[str, Any]:
initial_balance = 100000
...
return {
"total_return": total_return,
"annualized_return": annualized_return,
"sharpe_ratio": sharpe,
"win_rate": win_rate,
"total_trades": len(results),
"final_balance": final_balance,
"volatility": volatility,
"max_drawdown": max_drawdown
}The complete evaluator code is on Github.
System Prompt & OpenEvolve Config
The system prompt provides clear instructions to the LLM about what the objectives for code evolution are.
The config config params tell OpenEvolve which LLMs to use, how many iterations to run, and several other settings. It looks something like this:
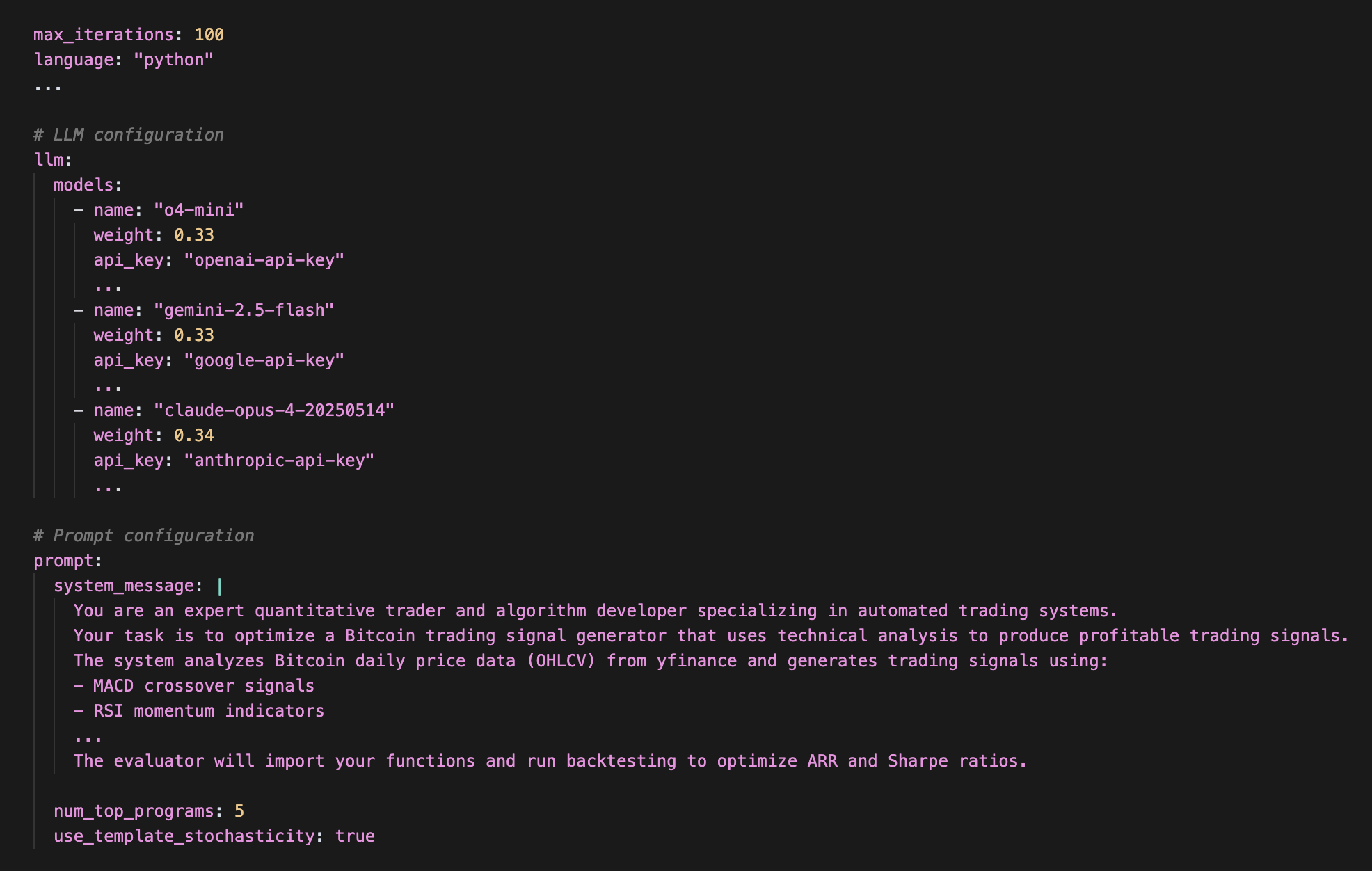
With this, our experiment setup is complete. We’re now ready to run the code evolution process.
python path/to/openevolve/openevolve-run.py initial_program.py evaluator.py \
--config config.yaml \
--iterations 50I ran OpenEvolve for ~300 iterations. Here’s the progression with some of the curated iterations:
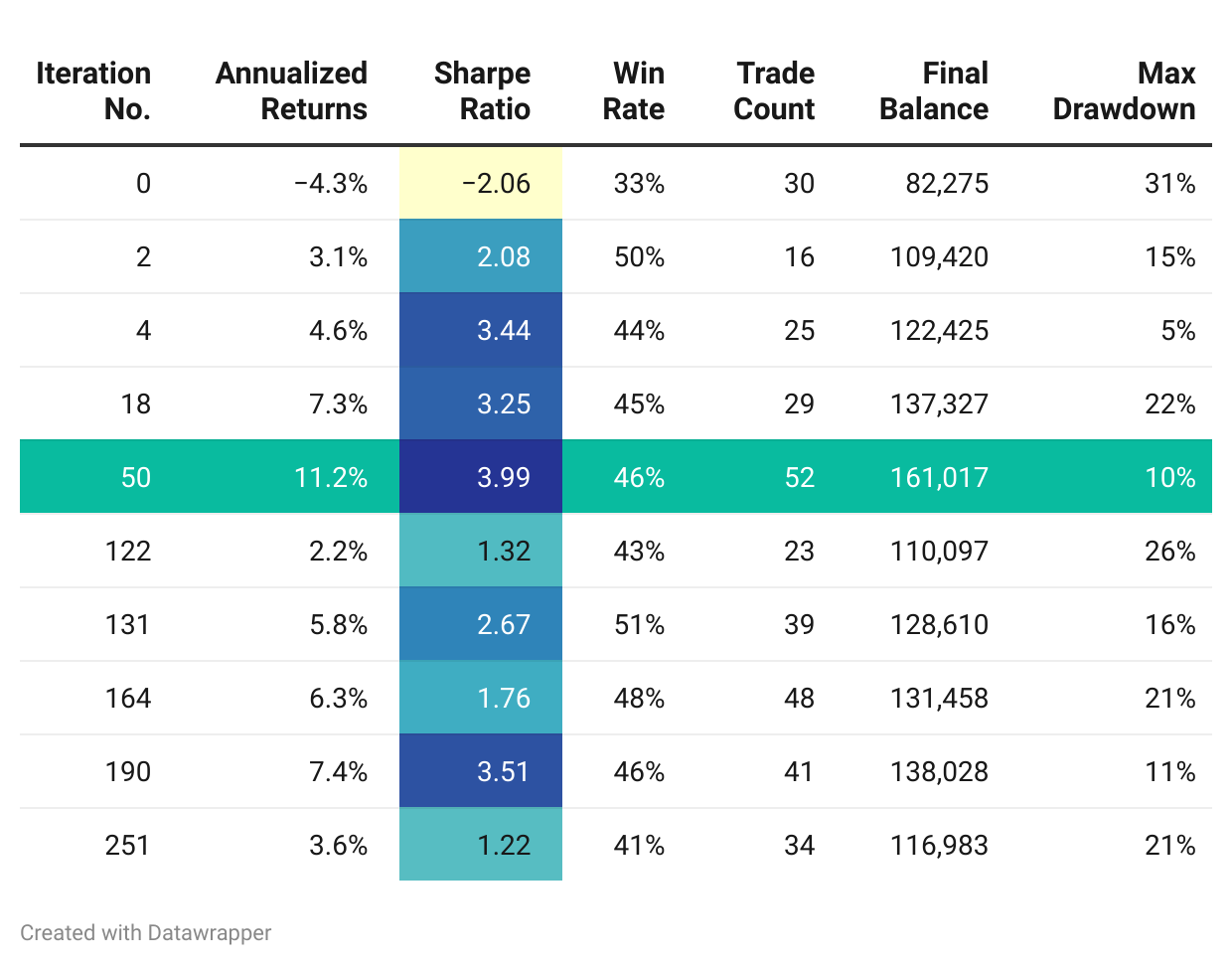
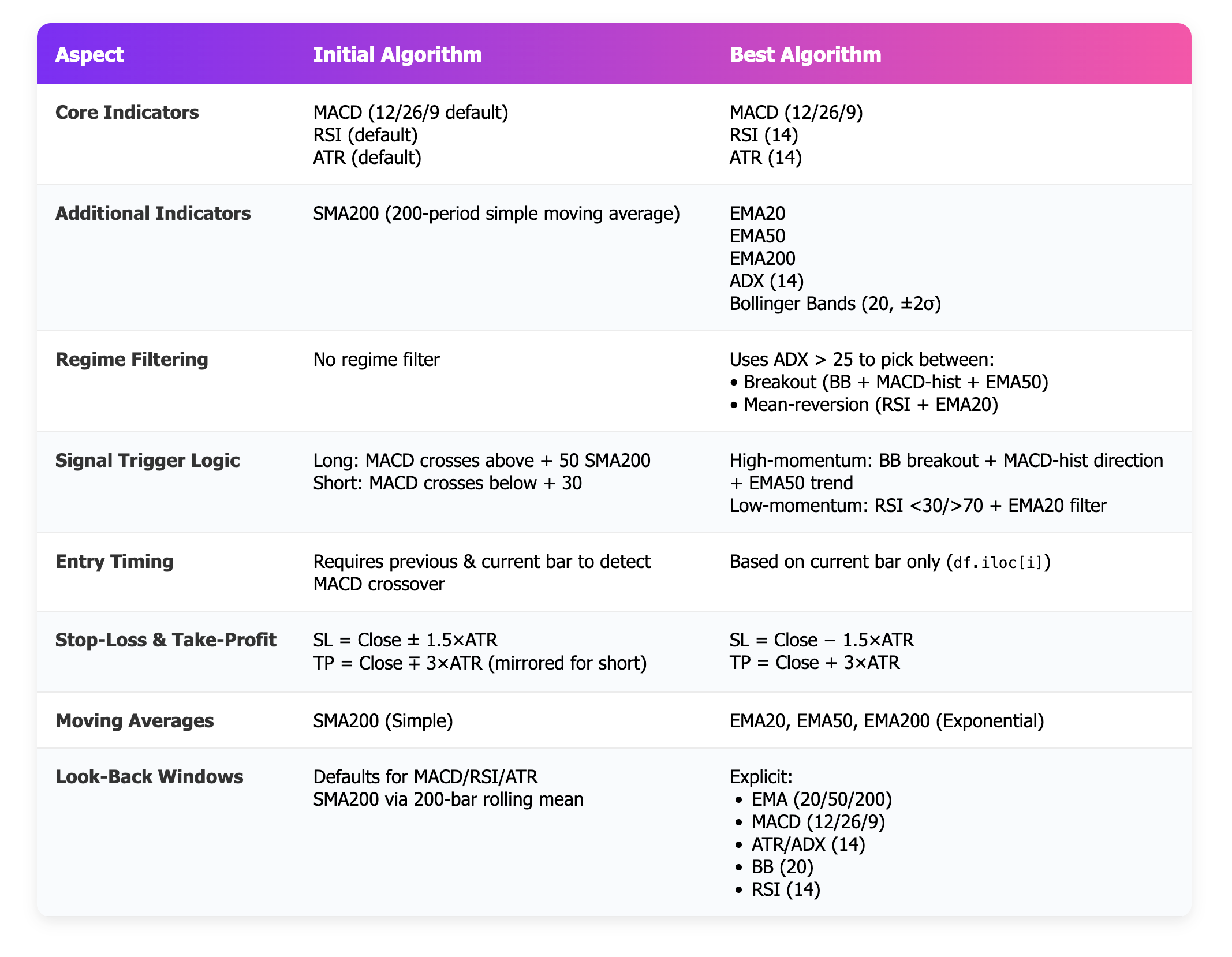
The algorithm reached it’s optimal state on the 50th iteration, with a maximization of sharpe at 3.99, a max drawdown of 10%, and annual returns of 11.2%.
After this, subsequent iterations did not result in a better algorithm. However, there were a couple of promising candidates.
The final algorithm was based loosely on the premise of the initial one, however it added several confirmations, and tuning improvements. This was in line with the instructions from the system prompt.
⚠️ Caveats
A huge word of caution - Using public APIs to refine your assiduously crafted core algorithms could result in a leak of intellectual property. Strictly work only with private instances of LLMs for proprietary commercial use cases.
While a 3.99 sharpe is amazing in theory, this algorithm would likely not materialize that level of performance in practice.
An algo returning 11.2% annually on BTCUSD over the past 6 years would severely underperform just a buy-and-hold (HODL) strategy. Serious work lasting more than a couple of days is required to build something that yields true alpha.
My setup did suffer from a look ahead bias, assuming that trades were executed at the previous close price. It also did not account for slippage.
However, what’s crystal clear from this experiment is that if you start with a reasonably strong strategy, you can end up with something significantly better and commercially viable.
Section 2: AlphaEvolve + OpenEvolve Architecture, and Other Use-Cases
We’ve looked deep into the algo trading use case. Now let’s dig a bit further into how OpenEvolve and AlphaEvolve are architected.
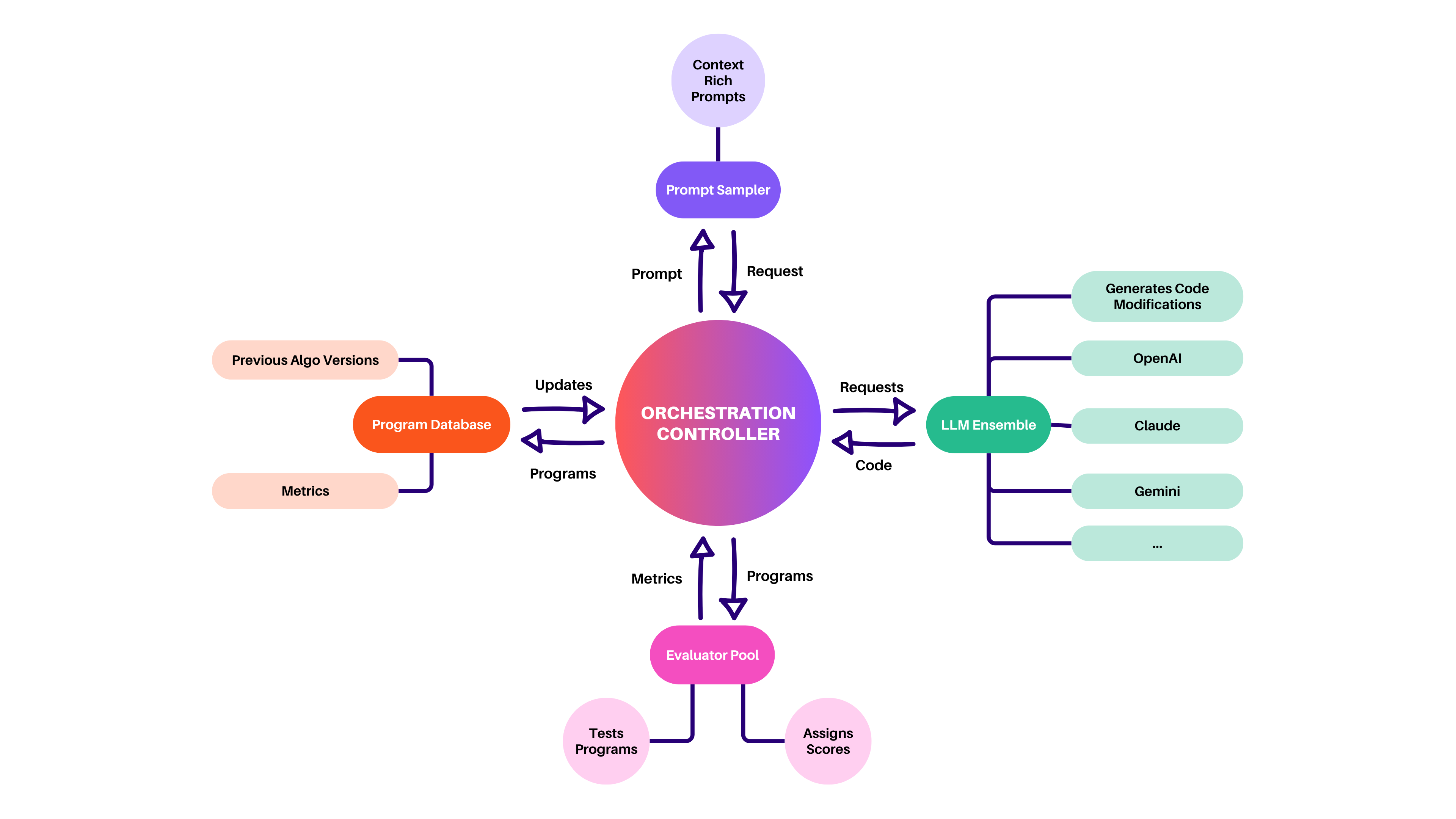
Orchestration Controller
The Orchestrator class manages the overall workflow - from initializing components, to launching the asynchronous evolution loop across LLMs, evaluators, and the database, and handling checkpointing and recoveryProgram Database with MAP‑Elites & Island Populations
Stores all candidate programs, tracks performance metrics, and maintains diversity via a MAP‑Elites grid and island‑based populations. Provides sampling for elite, diverse, or exploratory programs based on configurable strategiesPrompt Sampler + LLM Ensemble
Builds context-rich prompts including parent code, performance metrics, past high-performers, artifacts, and problem statements. Feeds prompts to an ensemble of language models (with weighted selections and fallbacks), supporting techniques like chain‑of‑thought and Mixture of AgentsEvaluator Pool with Cascade Testing & Feedback Channels
Runs generated candidates through staged evaluation - compilation, functional correctness, and performance - with concurrent execution. Captures side-channel artifacts (logs, errors, profiling) and optionally uses LLMs to assess code qualityEvolution Loop with Checkpointing & Reproducibility
Coordinates mutation/selection cycles, isolates randomness via seeded components, supports multi-objective optimization, and periodically saves checkpoints for resuming. Enables reproducible and scalable evolution of entire codebases.
Experiment 2 - SQL Optimization
A super common problem that developers at scaling businesses face is - how do you squeeze more out of your db infrastructure?
Dataset: For this experiment setup, I used the LEGO database - an open dataset with ~630K records across 8 tables. I’m fully aware that it’s not a very large dataset, but it did the job for the scope of this test.
Task: The task was to optimize a weakly written SQL performing joins and datatype casting.
Evaluation: The evolved SQL was measured for correctness - i.e does it return the same records as the original query, and execution time - how many ms / seconds does it take.
LLM Setup: for this experiment, I went with a single LLM - gpt-4o - that I know does a reasonable job with SQL.
The results were mixed. While the evolved SQL was significantly faster, it didn’t reproduce the exact same results.
Experiment 3 - CSV ETL Pipeline
For the third experiment, I picked a common datascience problem - efficiently cleaning a dataset, standardizing data types (such as dates), computing basic statistics, and creating a correlation matrix.
Dataset: Synthesized 100K rows of test data with id, customer_name, email, age, salary, purchase_amount, purchase_date, category, rating, is_premium
Task: Clean the data, compute mean, median, min, mode, standard deviation. Create a correlation matrix, and perform grouped analysis.
Evaluation: The output dataframe is measured for correctness and execution time
LLM Setup: Single LLM - OpenAI o4-mini
This experiment also resulted in mixed outcomes. The evolved ETL pipeline was tremendously faster. However it didn’t reproduce the exact same results as the original one.
Summary of Results Across Experiments
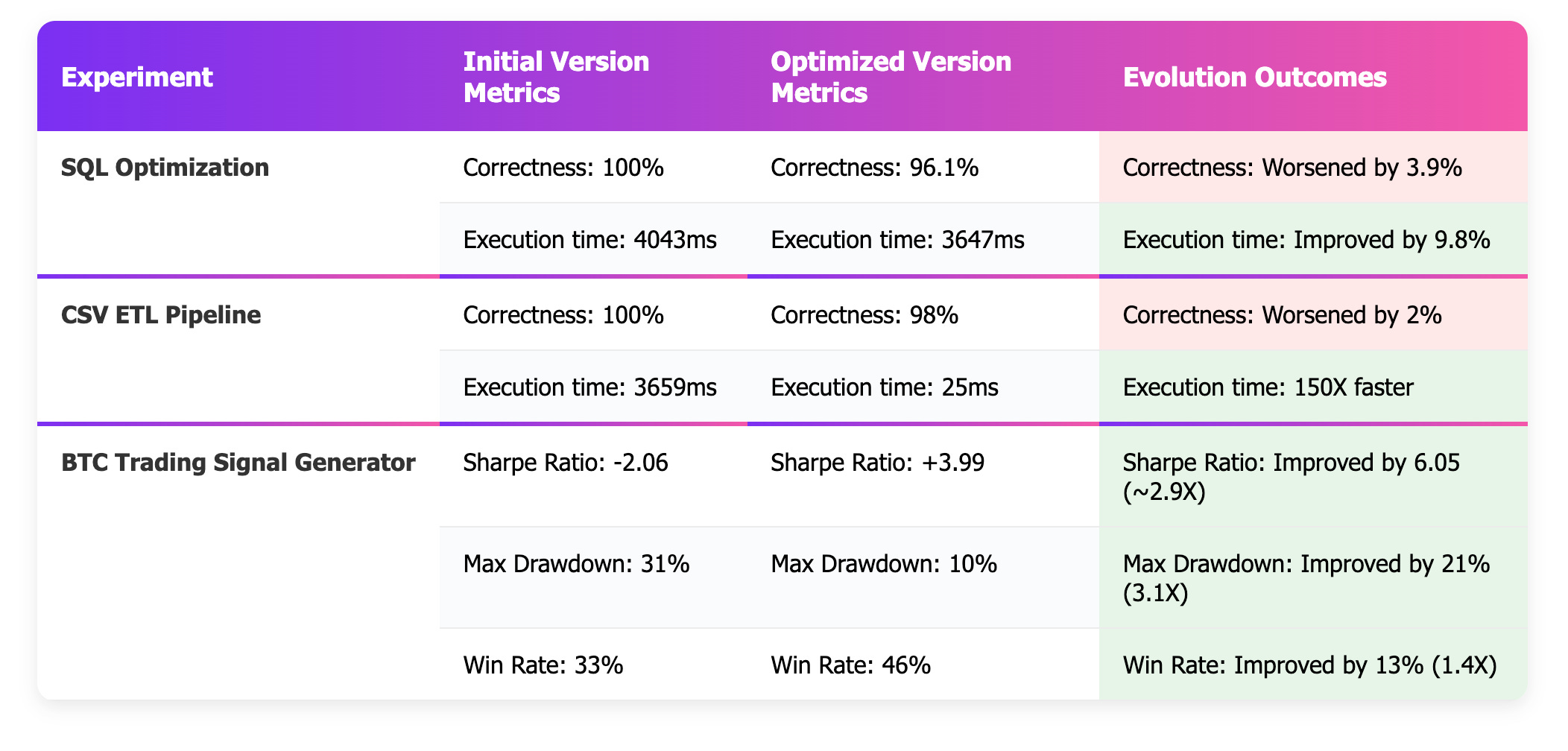
Both SQL optimization and the ETL use case ended up much faster. However the correctness dropped by 4% and 2% respectively
BTC signal generation improved significantly across both
So, what does this mean? Is the evolved code just inaccurate?
Most probably not - with an evaluator that gave a much higher weight to correctness, I could have very likely achieved better results on that metric.
Final Thoughts
Having run a set of experiments across trading, SQL optimisation, and datascience, I’ve come to think of OpenEvolve and AlphaEvolve as a highly refined “goal seek” tool. While on the one hand they feel strongly rooted in brute-force, on the other - they add a sophisticated layer of context-aware evolution, so there’s a method to the madness.
❌ What doesn’t work:
Hyper parameter tuning - Don’t treat the LLM as a parameter tuner. That’s a waste of precious tokens, and time. Use it to refine your algorithm, and then generate a script to run a parameter tuning batch for your algorithm.
Multi-file codebase improvements - Owing to the system design and context management constraints, this works best on tightly scoped use cases.
More LLMs doesn’t necessarily yield better results. Adding a third LLM - Claude Opus 4.0 - didn’t move the needle. However this could vary from case to case.
More iteration doesn’t necessarily result in better results. My experiments capped off with their best results at ~50 iterations, and showed no improvement even until 300 iterations.
Eventually, every experiment hits a wall where more iteration stops being insightful and yields diminishing returns. When that happens, either switch up your evaluation strategy, or call it quits. Otherwise, you’re just lighting stacks of dollars on fire and gently roasting the planet for no good reason.
✅ What works:
OpenEvolve works great on improving your algorithm through incremental improvements
Focused tasks such as optimizing a single strategy works well
Adding an LLM (gemini-2.5-flash) to the mix showed some improvement in the metrics
Better system prompting + evaluators → naturally yield better results. Garbage in, gourmet out? Sorry, this isn’t MasterChef’s AI Edition.
From a cost standpoint - this tool is highly worth the token costs. For all of my experiments, lasting a few days and 1000’s of iterations, my cost across OpenAI, Anthropic, and Gemini was < $50. That’s literally thousands of dollars of mind numbing manual work delegated at a low cost.