

Reinforcement Learning For Agents - Part II
A comparison of Agent Lightning, Handit.ai, and a Homegrown tool - AgentEvolve

Last week, I wrote an article exploring code evolution as a Reinforcement Learning technique to improve agents in the modern sense.
The key problem we’re trying to solve for is:
How do you systematically improve an agent’s prompts, tools, flow, and overall end-to-end experience based on real user interactions?
In this study, we examine the same challenge from different points of view. Three different schools of thought emerge around this:
Agent Lightning – An open source server–client traditional RL training fabric for any agent
Handit.ai – An autonomous reliability engineer that continuously monitors, fixes, and ships improvements into production
AgentEvolve – A code evolution CLI framework that applies RL-like loops to incrementally evolve an agent’s prompts, tools, and orchestration code
We’ll dive into the architecture of each, followed by an evaluation of their strengths and weaknesses.
1. Agent Lightning - RL for existing agents without rewriting them
1.1 Philosophy
Most RL frameworks require you to rebuild your agent around a training loop. Agent Lightning flips this: it decouples the agent from the trainer. You run the agent as-is, while a separate Lightning Server coordinates tasks, rewards, and model/prompt updates.
1.2 Core architecture

Server (the training brain)
The Agent Lightning Server is the central coordinator that manages all aspects of the training loop. Its responsibilities include:
Task Queue (
/task) – Holds the training, validation, or test tasks to be assigned to connected clients. These can come from curated datasets, synthetic generators, or live traffic sampling.Resource Registry & Versioning (
/resources) – Stores and versions all the “policy artifacts” an agent needs to run, such as prompt templates, model endpoint URLs, and decoding parameters. Every training round publishes a new version so clients are always in sync.Rollout Ingestion (
/rollout) – Collects full execution traces from clients, including the state → action → reward sequences that RL algorithms rely on.Optional RL Trainer (VERL, APO, or custom) – Runs inside the server or as a connected component, taking the collected rollouts and updating the resources (e.g., refining prompts or tuning parameters) to improve performance.
Client (the execution arm)
The Agent Lightning Client acts as the runner for your existing agent:
Polling for Work – Periodically fetches the next task from
/taskand retrieves the corresponding resource version from/resources.Executing the Agent – Runs your existing agent logic (LangGraph, CrewAI, AutoGen, or custom code) using the provided prompts and parameters.
Logging Results – Computes a reward (scalar or per-step), records traces, and sends the complete rollout back to the server for training.
This design means you don’t have to rebuild your agent from scratch - you simply wrap it in a thin client layer.
1.3 Dataflow
[Server] — enqueue tasks + version resources
[Client] — poll → execute agent → compute reward → POST rollout
[Server] — aggregate rollouts → train → publish new resource versionsServer queues up tasks and publishes the current resource version.
Client polls for a task, fetches the latest resources, and runs the agent.
Client computes the reward, packages the trajectory, and POSTs the rollout back.
Server aggregates rollouts, runs the trainer to improve the policy, and publishes a new resource version.
1.4 Strengths
Applies true RL methods - not just prompt tweaking or heuristic scoring - which is rare in the agent improvement space.
Minimal code changes – Just subclass
LitAgentand connect it to the client interface.Supports complex workflows – Works equally well for single-agent, multi-agent, and tool-heavy execution graphs.
Consistent configuration – Resource versioning ensures all clients use the exact same prompts, parameters, and models during training.
Flexible optimization methods – Swap in RL algorithms, prompt optimizers, or hybrids without touching your agent logic.
1.5 Weaknesses
High integration overhead. You must define a dataset or a task generator, wire up a reward function, adapt your agent to run under Lightning’s resource contracts, and ensure the client can produce valid rollouts. None of these are trivial, especially if you’re starting with an existing codebase.
Dataset creation is on you. The framework does not provide pre-built domain datasets or generators. You must curate and load your own - and structure them in a way that Lightning can consume. This is a significant upfront cost before you can even begin training.
Reward engineering is a full project. Because Lightning aims for generality, it offers no turnkey reward functions; you must write your own, calibrate them, and handle edge cases like partial credit or noisy judge-LLMs. This is work that can easily overshadow the “plug-and-play” promise.
Steep ramp-up. The examples in the repo are non-trivial (Spider SQL, AutoGen agents) and assume comfort with RL environments and distributed client-server setups. For a newcomer to RL, this is not a weekend integration.
2. Handit.ai - Continuous production-time reliability loop
2.1 Philosophy
Training is one thing - but production is where agents fail. Handit’s design assumption:
“Your agent will break in prod; the system should detect, fix, and ship improvements autonomously.”
2.2 Core architecture

Tracing SDKs (Python/JS)
Handit provides lightweight SDKs for both Python and JavaScript that let you instrument agents with minimal intrusion:
Agent-level wrappers (
start_agent_tracing) capture the full lifecycle of an agent run.Node-level decorators (
@trace_agent_node) instrument individual tools or LLM calls, recording detailed execution data.These hooks automatically capture inputs/outputs, latencies, errors, and evaluator scores for every traced step.Evaluation layer
Built-in and custom “LLM as judge” evaluators
Scores production traces for factuality, schema compliance, latency, etc.
Evaluation Layer
Once traces are captured, they pass through a flexible evaluation system:
Built-in evaluators and custom “LLM as judge” modules can be applied to measure quality.
Metrics can include factual accuracy, schema compliance, response latency, and any domain-specific rules you define.
Optimization Engine
The evaluation results feed into an automated optimization pipeline:
For underperforming components, Handit generates multiple improved prompt or workflow variants.
Variants are tested via background A/B experiments - mirrored traffic ensures no risk to live users.
When a candidate outperforms the baseline, Handit automatically promotes it by creating a GitHub pull request with both the change and its supporting performance data.
2.3 Strengths
Deep observability without code rewrites - tracing hooks are drop-in.
Safe experimentation - background A/B testing ensures no degradation in user experience.
Tight CI/CD integration - PRs include code/prompt diffs alongside performance deltas for faster review and deployment.
2.4 Weaknesses
Not production-ready out of the box - the Python quickstart required manual configuration and guesswork.
Documentation lags the implementation - examples, CLI outputs, and SDK behavior don’t always match, indicating a lack of polish and testing.
Immature execution - while concepts like background A/B and GitHub-native prompt updates are compelling, the gap between vision and functional workflow is noticeable.
High potential, unfinished product - with stability and documentation improvements, Handit could be a strong differentiator for production-time optimization, but at present it requires patience, workarounds, and likely close contact with the development team to get working.
3. AgentEvolve - Code-level RL for prompts, tools, and flows
3.1 Philosophy
Reinforcement learning for agents isn’t about tuning model weights - it’s about improving the code that drives agent behavior. AgentEvolve approaches this as a code evolution problem. It’s a CLI- and decorator-based framework designed to:
Identify and extract key agent components (prompts, tools, flow nodes) into isolated “evolution targets.”
Generate synthetic evaluation datasets and reward functions tailored to those targets.
Evolve each target iteratively using OpenEvolve or similar LLM-based code evolution systems.
The goal: make targeted, measurable improvements to individual components so the overall agent improves without risky, wholesale rewrites.
3.2 Core architecture
Target extraction
Tag any function, prompt, or tool with the
@evolvedecorator.Run
agent_evolve extract_targetsto pull those components and their dependencies into a staging directory for isolated evolution.
Evaluator generation
Use
agent_evolve generate_evaluatorsto create domain-specific reward functions.Generated evaluators often need some manual tuning to ensure accuracy and relevance.
Test data synthesis
Run
agent_evolve generate_training_data --num-samples Nto generate synthetic evaluation inputs via an LLM.Produces a ready-to-use synthetic dataset for benchmarking candidate evolutions.
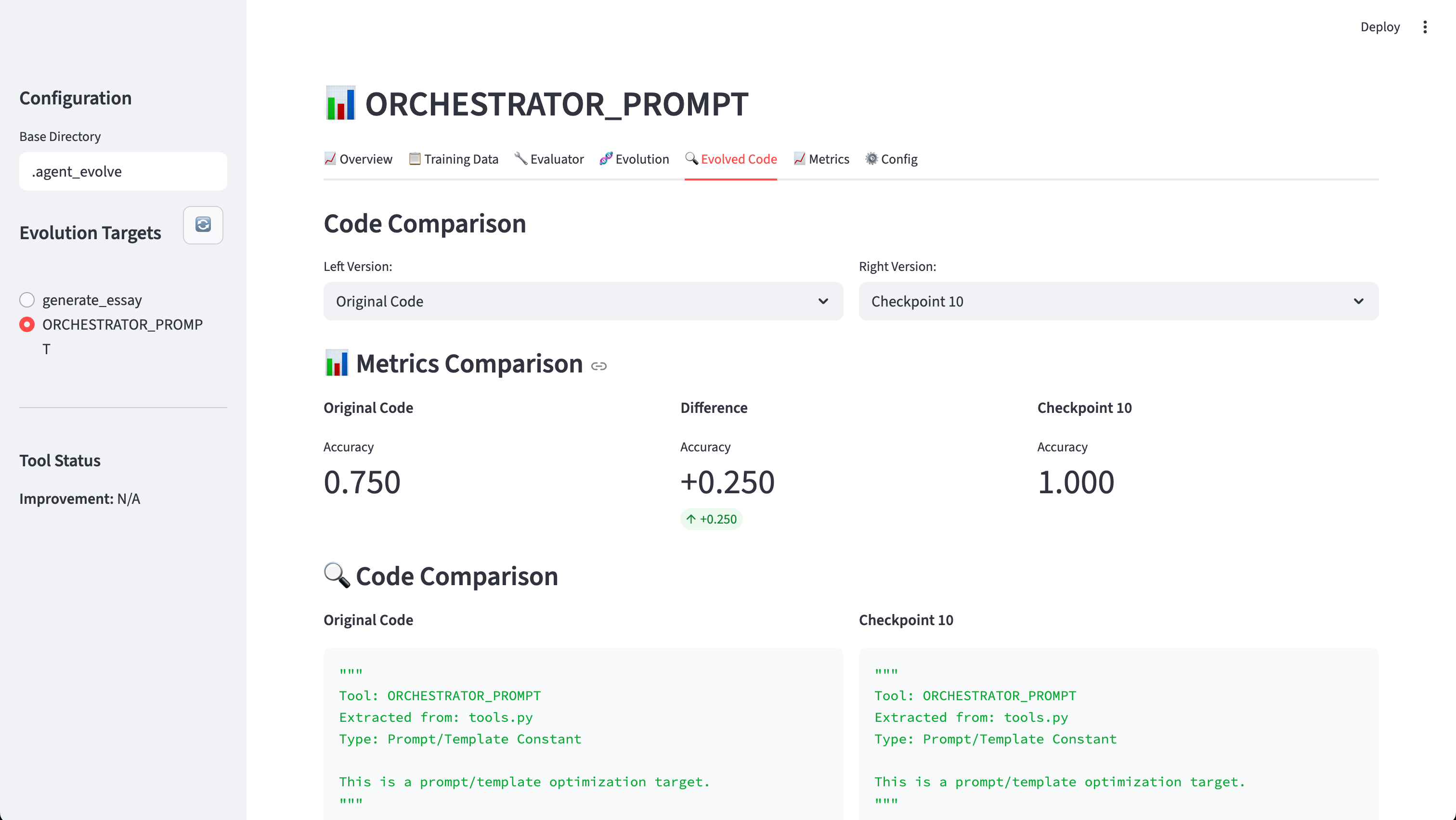
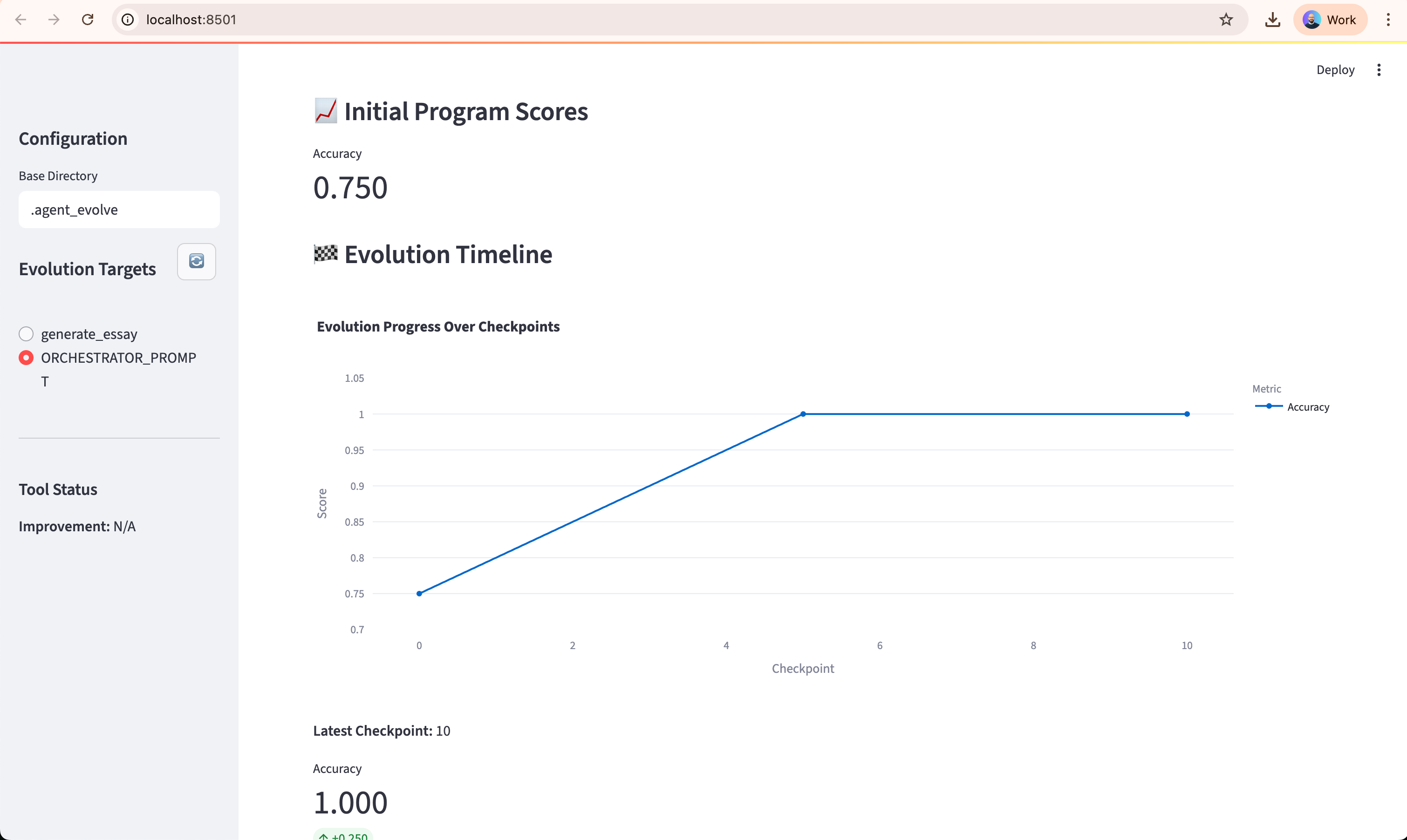
Evolution loop
Execute
agent_evolve run_openevolve --target Xto run multiple generations of code evolution.The system scores each generation, tracks progress, and selects the highest-performing variant.
Produces an evolved code diff and accompanying evolution score history for review.
RLHF Concept
Streams real user–agent conversations into a SQLite database.
Repurposes these as labeled preference data to fine-tune evaluators, making them more representative of real-world usage.
3.3 Strengths
Improves agents at the component code level rather than only at the prompt text level.
Can evolve prompts, tool wrappers, and orchestration logic independently without disrupting the entire system.
Includes a Streamlit dashboard to visualize evolution candidates, training data, and performance metrics over time.
3.4 Weaknesses
Very raw and rough. As of now, this is more a developer’s workbench than a production-ready library. Many breaking points remain unaddressed.
Two weeks of focused work wasn’t enough to get it into a state where someone else could pick it up and use it without direct guidance.
Currently a wrapper around OpenEvolve with convenience utilities - synthetic data generation, evaluator generation, staging/evolution commands - but these are early-stage and brittle.
Evaluator quality is inconsistent. The generated evaluators vary from passable to outright unhelpful; manual tuning is often required, which undermines automation.
Needs several rounds of refinement before it can be used OOTB by other developers. The CLI exists, but workflows aren’t frictionless, and error handling is minimal.
Framework Comparison
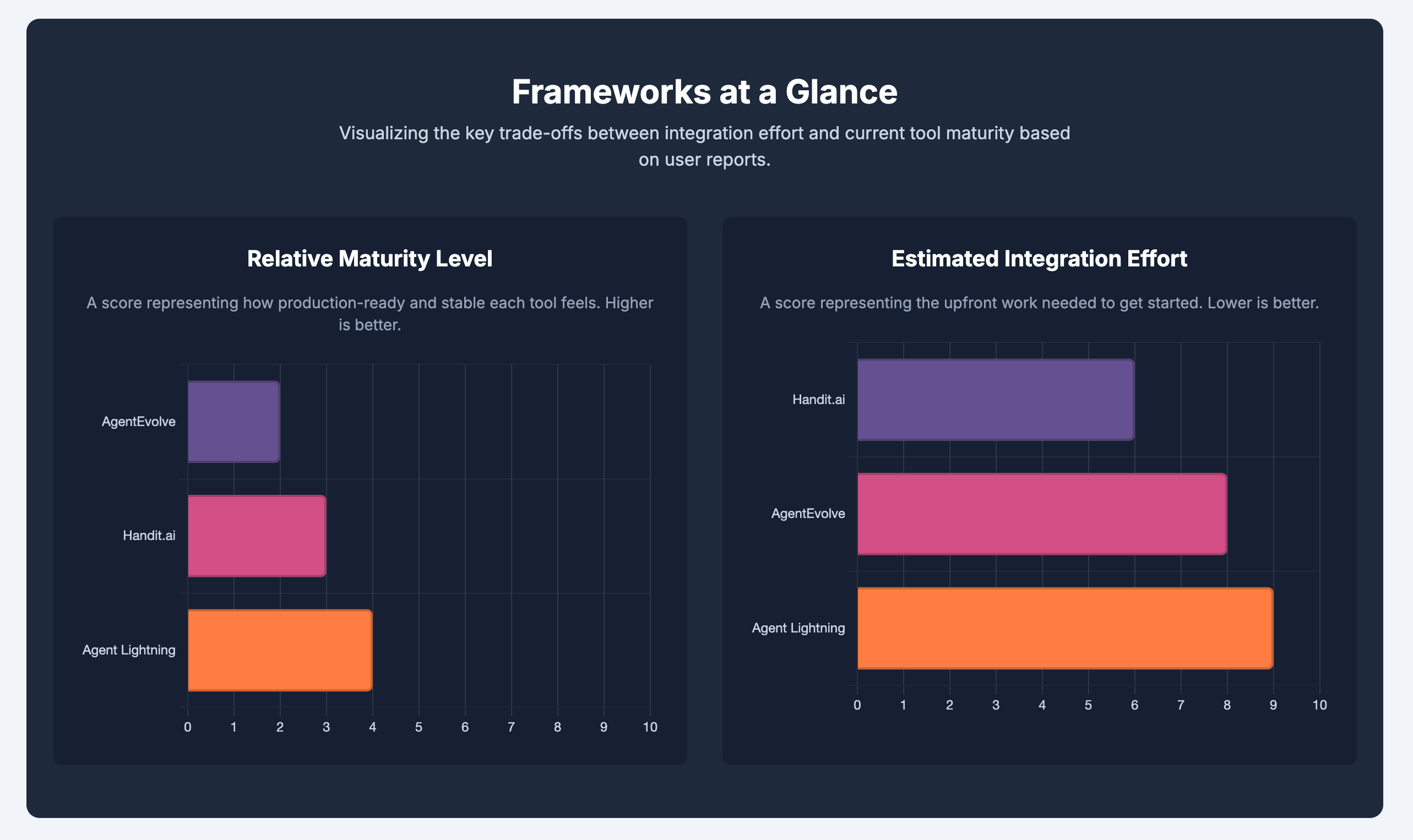
All three are very early, and rather immature. None of them give a feeling of “automation”.
Agent Lightning brings traditional reinforcement learning into agent optimization, offering decoupled training and centralized resource control, but demands significant setup, dataset creation, and reward engineering expertise.
Handit.ai positions itself as a production-first reliability loop, with background A/B testing and GitHub-native deployments, yet suffers from out-of-date documentation and an immature developer experience.
AgentEvolve targets code-level evolution of prompts, tools, and flows, offering flexibility and an RLHF integration path, though it’s still early-stage, brittle, and not ready for out-of-the-box use.

Final Takeaways
There’s a glaring gap in this space, and none of the three tools come close to fully solving it.
Integration burden is high. Whether it’s RL-based (Lightning) or code-evolution-based (AgentEvolve), you’re looking at significant glue code, dataset prep, and environment config before you see results.
Observability and improvement aren’t tightly coupled yet. Handit hints at this by feeding evaluator results into prompt updates, but no tool in this group cleanly unifies telemetry, automated evaluation, and autonomous updates in a way that works reliably out of the box.
Clear whitespace exists for a deep, integrated solution that can:
Plug into existing agents without heavy refactor,
Capture and evaluate interactions,
Learn from them automatically,
Deploy safe, tested updates without human babysitting.
For anyone building in this space, the ideal solution should combine the following capabilities:
Tracing and automated training data capture directly from real user interactions
Automatic synthesis of additional training data to expand coverage
Reflective evaluation and refinement of the training dataset over time
Automated, reliable reward function (evaluator) generation
Framework-agnostic flexibility to work seamlessly across different agent architectures
Sharp write-up from Praveen. My takeaway: the market’s still missing an integrated “observe → learn → deploy” autopilot. That’s our north star.
So my question is if you had to ship one tomorrow, which camp would you bet on? RL trainer (Agent Lightning), prod reliability (Handit), or code evolution (AgentEvolve)?
Why?
Feels like we’re on the cusp of true out-of-the-box, on-device ML for every laptop. The sticking point, as Praveen notes, is integration.
Could our Center of Excellence build a plug-in bootstrapper that recommends a reference architecture and then auto-provisions the stack - tracing, evaluators/rewards, datasets, and configs - so one can drop it into any system and have it wire itself to our patterns with little to no input?
In other words: one adds the tool, it understands the structures and priorities we’ve outlined, and it integrates the target system into the codebase end-to-end.
That would directly address the gap you highlight around “plug in, capture/evaluate, learn, and safely ship updates.”