

Multi-Agent Deep Research Architecture
Leveraging a Knowledge Base for Continuous, Iterative Discovery

Introduction
In "Comparative Analysis of Deep Research Tools," I noted that these AI assistants excel at autonomously diving into vast amounts of information – but they typically deliver a one-off report, leaving no persistent record of their findings for follow-up research. Recognizing this shortcoming, this proposed set of architectures introduces a multi-agent system that continuously builds and refines a knowledge base over successive research iterations. By integrating specialized agents for planning, parallel search, summarization, and higher-order reasoning – and crucially, linking these processes through a persistent Knowledge Base –this design enables the system to accumulate insights over time. Inspired by innovations from projects like Agent Laboratory and Google’s AI Co-Scientist, these approaches promise not only deeper, more dynamic research but also the capacity to support follow-up investigations and long-term knowledge management.
High-Level System Overview

Key Principles & Goals:
Parallel Tree Search: Break down complex research topics into smaller subtopics that can be pursued in parallel.
Cycling Summarization & Reasoning: After each research pass, results are summarized and reasoned upon to refine the search strategy.
Higher-Order Reasoning with Deep Models: Employ advanced reasoning models (e.g., DeepSeek R1, OpenAI o3) to perform analysis, synthesis, and evaluation.
Multi-Agent Collaboration: Orchestrate specialized agents (for search, summarization, validation, etc.) to achieve deeper research results.
Iterative Feedback Loops: Continuously refine the research direction and scope based on emergent insights and identified knowledge gaps.
Principles
Modular Architecture with Specialized Components
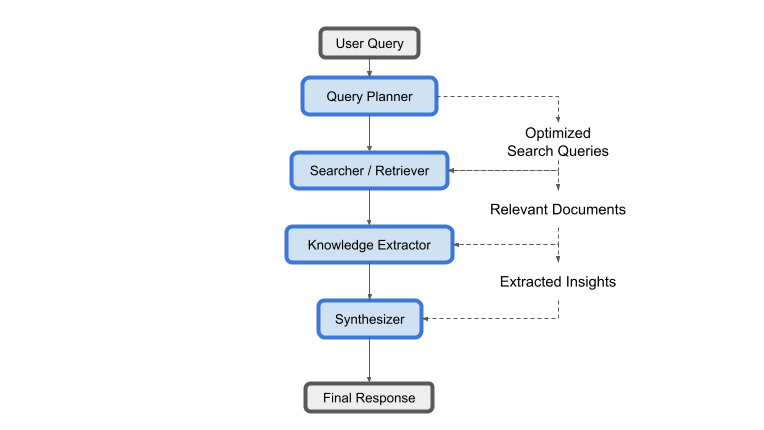
One approach to building a custom agent is to break the task into specialized modules rather than relying on one monolithic agent to do everything. For example, you could have a dedicated “Query Planner” module that analyzes the user’s question and generates an optimal set of search queries (perhaps using a lightweight model or rules engine for speed). Then a “Searcher/Retriever” module actually fetches results for those queries (using APIs, accessing not only web search but also specific databases as needed). Next, a “Knowledge Extractor” module could parse and extract key facts or answers from each retrieved document – this could be an NLP pipeline or an LLM prompt that just focuses on pulling relevant snippets. Finally, a “Synthesizer” module (likely a strong LLM) would take the collected information and compose the final answer or report. This kind of pipeline (planner → retriever → extractor → synthesizer) is somewhat analogous to how a human research team might operate, or how some question-answering systems in academia are built. The advantage is that each component can be optimized or swapped out independently. For instance, the retriever could use a vector database to find information if one has been built up, or the extractor could use regex for specific data and an LLM for more nuanced text. By separating these concerns, we may improve efficiency – e.g., run multiple retrievals in parallel, or use smaller models for some parts and reserve the big model only for the final synthesis. This differs from current end-to-end agents (which mostly use one LLM to handle all decisions and synthesis) and could overcome some limitations like long latencies and context limits.
Hierarchical or Tree-of-Thought Processes

Another innovative workflow is to use a hierarchical reasoning approach. Instead of a linear loop, the agent could recursively break down the problem into a tree of sub-problems (a methodology sometimes called “Tree of Thoughts”). For instance, the top-level question is split into sub-questions A, B, C. Then each of those might be further split, and leaf nodes (specific factual questions) are answered by searching. The intermediate nodes then synthesize their children’s answers, and finally the root compiles everything. This approach could be implemented with multiple agent instances or a single agent that knows how to recurse. The benefit is potentially a more thorough exploration of the question space: it encourages the agent to explicitly consider different aspects in parallel rather than sequentially (similar to parallel modules above, but organized as a hierarchy of reasoning). It could also allow depth-first search on particularly challenging sub-questions without forgetting the others. Some research has indicated Tree-of-Thought frameworks can improve problem-solving by enabling backtracking and exploration of alternative paths. A custom agent using this might, for example, try two or three different search strategies in parallel branches and then choose the branch that yielded the best info. Current tools don’t really do that – they follow one line of reasoning. Introducing a controlled divergence and convergence (like hypothesis generation and elimination) could make an agent more robust, albeit at the cost of more computation.
To accelerate the process, a custom agent could launch multiple search queries in parallel (especially if we expect many subtopics). Using asynchronous I/O or multi-threading, it could retrieve results for 5 different queries nearly simultaneously, then process them. Several deep research agents right now are largely sequential (which is partly why they take minutes). If parallelism is leveraged, one could cut down the time significantly.
Incorporating Domain Knowledge and Heuristics
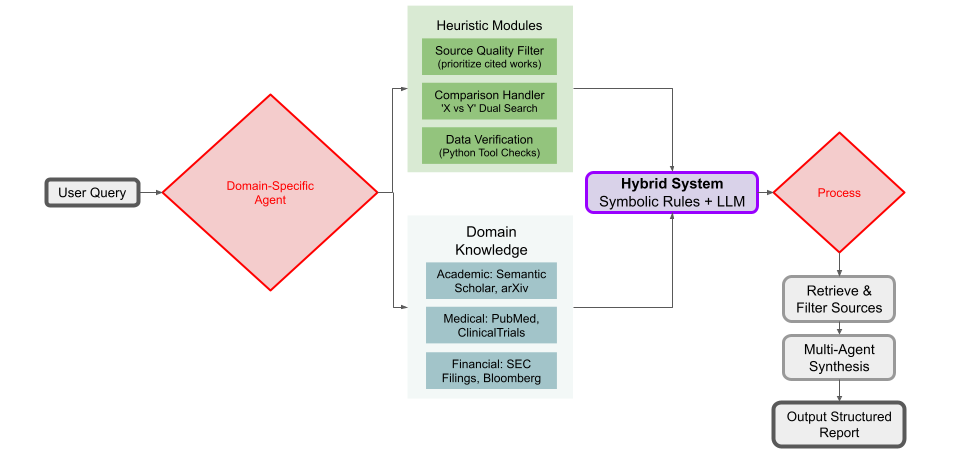
A custom deep research agent could be tailored with domain-specific knowledge or rules to improve performance in certain areas. For example, if you are building an agent to do academic research, you might integrate it with scholarly databases (Semantic Scholar, arXiv API) and include a heuristic to prioritize peer-reviewed papers or highly cited works as sources. The agent could have a built-in notion of source quality – perhaps a module that evaluates if a website is likely authoritative (e.g., .gov, .edu domains, known news outlets, etc.) and filters results accordingly to reduce junk. Another heuristic: if the question asks for a comparison (like “X vs Y”), the agent might automatically ensure it searches for both X and Y explicitly and looks for sources that mention both. These domain or task-specific tweaks can make an agent’s research process smarter. In the current general agents, the LLM sort of learns some of these patterns, but encoding a few as explicit rules might speed up convergence and reduce errors. A custom architecture could allow plugging in such logic (like a rule-based system working alongside the LLM). Think of it as a hybrid AI: symbolic rules + neural reasoning. For instance, one could enforce a rule “when question is about statistics, retrieve data from official statistics site or dataset and have the Python tool verify calculations” – this ensures higher accuracy on numerical answers. As deep research agents become more common, we might see specialized agents (like a “financial research agent”, “medical research agent”) that have these sorts of custom workflows and knowledge bases integrated.
Multi-Agent Collaboration and Role Assignment

Taking inspiration from human teams, a custom system could implement multiple agents with distinct roles that collaborate on research and synthesis. For example:
A “Researcher” agent whose job is to find as much relevant information as possible. This agent could combine the previous concepts of tree of thought reasoning and domain-specific agents.
An “Analyst” agent that takes the raw info and tries to organize it, perhaps identifying key points, contradictions, or insights. This agent could ask the Researcher for clarifications if needed (“Did you find data on X aspect? If not, search that.”).
A “Writer” agent that focuses on composing the final report in a coherent narrative, once it has the structured notes from the Analyst.
Optionally, a “Critic” agent that reads the final draft and cross-checks claims or looks for holes in the reasoning, prompting revisions.
These agents could communicate in a shared memory or through a supervising process. This approach falls under the category of multi-agent systems, where each agent might even have a different prompt persona or even different model (the researcher could be a fast model, the writer a high-quality model). The challenge is orchestrating the communication so it doesn’t become chaotic or inefficient. Frameworks like Microsoft’s Autogen, or Langroid, or CrewAI can facilitate structured multi-agent conversations. A possible workflow: the Researcher agent dumps all found info into a shared document; the Analyst agent reads it and creates an outline; the Writer agent fills out the outline. This could be more efficient than a single agent doing everything sequentially, and it mirrors the way complex reports are often produced by teams. The outcome might be more reliable too, since each agent double-checks or supplements the others.
Enhanced Information Processing Techniques

We can draw from information retrieval and knowledge management research to bolster a deep research agent. One idea is to use a Knowledge Graph: as the agent finds facts, it could add them as nodes/edges in a graph database to represent entities and relationships. This graph can then be used to identify connections or missing pieces. For example, if the question is about comparing companies, the graph might link companies to products, revenue, etc., and the agent can see which nodes are missing and query for those specifically. This structured representation could guide the research process more systematically than just free-form text memory. Another technique is embedding-based retrieval: the agent could vectorize the query and use an embedding database of web pages (if available) to find relevant pages without a keyword search, which sometimes surfaces different insights. One could also pre-index a lot of high-quality content (Wikipedia, textbooks, etc.) in an embedding space and have the agent query that first for quick answers, resorting to live web search for newer or niche info. Essentially, combining retrieval augmentation with the agent loop. Current agents mostly rely on live search each time; a custom one could have a two-tier retrieval (first check an internal knowledge base, then external web). This would reduce search API calls and possibly improve reliability (since the internal knowledge base might have vetted info).
Improved Stopping Criteria and Confidence Estimation
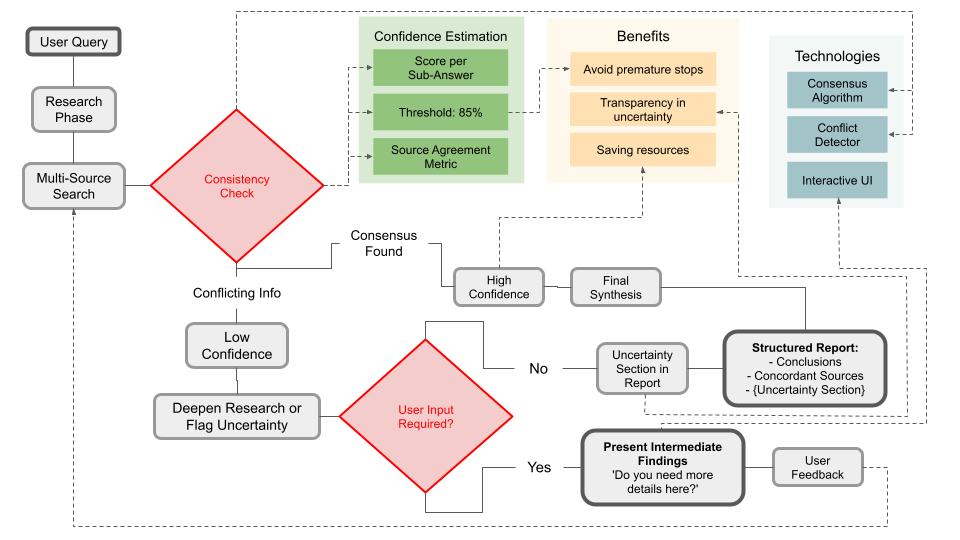
One workflow improvement beyond existing agents is smarter stopping criteria. Currently, an agent might stop after X steps or when it guesses it has answered the question. A custom agent could use a more explicit signal, such as: check if the same answer/consensus appears in multiple independent sources – if yes, high confidence, stop; if conflicting information is found, continue digging or flag uncertainty. It could also present intermediate findings to the user and ask if more detail is needed in any area, effectively doing an interactive refinement. Incorporating a confidence score for each sub-answer could help the agent decide when to end the research phase and move to writing. This would prevent cases where the agent stops too early or goes on too long. It also could output an “uncertainty” section in the report if it finds contradictory sources, which would be a sophisticated feature not yet in current tools (currently they tend to either pick one side or average out).
Leverage of User Feedback and Preferences

A custom agent can also be designed to learn from the user over time. For instance, if a user is using it in a specific domain regularly, the agent could remember which sources the user trusts (maybe the user always clicks certain links from the report or gives a thumbs-up when certain journals are cited). The agent could then prioritize those in the future – a form of personalization. This could be done via a user profile or fine-tuning on the user’s feedback. Additionally, a user might prefer a certain style of answer (more technical, more high-level, etc.). Current deep research outputs are somewhat generic in style; a custom one could allow a style parameter or detect the expertise level of the user and adjust the detail accordingly. Workflows that include a “draft review” by the user mid-process could also be considered: e.g., after gathering info, the agent could present an outline to the user like “Here’s what I’m thinking of covering, any adjustments?” This kind of interactive workflow (a bit more conversational) could yield a more user-aligned result. While it slows down the autonomy, it might be valuable for scenarios where the user’s insight can guide the AI away from blind alleys.
Core Components & Layers
Orchestration & Coordination Layer
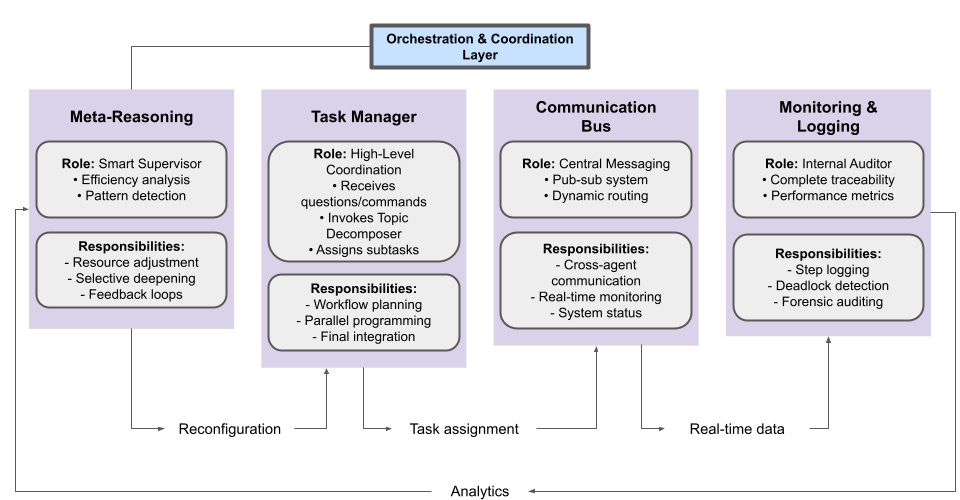
Task Manager
Role: Receives the high-level research question or goal.
Responsibilities:
Invokes the Topic Decomposer Agent to split the question into subtopics.
Assigns each subtopic to appropriate Search or Reasoning agents.
Oversees workflow progression (initiation, parallel subtask scheduling, final integration).
Communication Bus
Role: Central or decentralized message-passing mechanism (e.g., a pub-sub system).
Responsibilities:
Ensures all agents can send/receive updates.
Provides real-time monitoring of agent outputs and internal states.
Monitoring & Logging
Role: Continuously monitors agent performance, data flow, resource usage, and ensures no deadlocks occur.
Responsibilities:
Logs intermediate steps, agent decisions, and final results for audit trails.
Tracks performance metrics (e.g., time to gather data, quality of results).
Meta-Reasoning / Feedback Control
Role: Observes the entire research process to detect inefficiencies, repeated errors, or important leads.
Responsibilities:
Adjusts resource allocation based on subtopic complexity or discovered importance.
Triggers deeper search loops for high-value or contentious subtopics.
Research Planning & Topic Decomposition

Topic Decomposer Agent
Inputs: The overarching research topic (e.g., “Feasibility of fusion energy commercialization by 2040”).
Role: Uses advanced reasoning (DeepSeek R1 or a distilled variant) to build a hierarchical tree of subtopics.
Outputs:
A structured breakdown (e.g., “materials science,” “economics,” “regulatory environment,” etc.).
Potential dependencies or pre-requisites across subtopics.
Preliminary prioritization or resource estimates.
Initial Planning Module
Role: Takes the decomposition tree and sets milestones, schedules, and agent assignments.
Responsibilities:
Determines search depth, which data sources are appropriate, and relevant domain experts or specialized reasoning models.
Establishes how often iterative feedback cycles should occur.
Parallel Search & Data Retrieval Layer

Subtopic Search Agents
Role: Focus on specific subtopics (e.g., one agent focuses on “tokamak design,” another on “regulatory hurdles,” etc.).
Responsibilities:
Query relevant databases, archives, APIs, websites, or internal repositories.
Return structured or unstructured data (papers, articles, dataset links) to the Data Aggregation module.
Adapt search strategies over time (e.g., refined queries after receiving summarization outputs).
Data Aggregation Service
Role: Collects raw data results from each Subtopic Search Agent.
Responsibilities:
Deduplicates and normalizes data.
Organizes results by subtopic, date, and source.
Stores them in a staging area for subsequent Summarization & Reasoning.
Summarization & Higher-Order Reasoning

Summarization Agents
Role: Transform raw data into concise, human-readable summaries, highlighting critical points.
Responsibilities:
Execute summarization tasks (e.g., bullet-point extractions, highlight major claims).
Tag key findings, uncertainties, or knowledge gaps.
Higher-Order Reasoning Agents (using DeepSeek R1 or its distilled variants)
Sub-Components:
Synthesis Module
Definition: Synthesis is the process of combining information from multiple sources to form new, cohesive insights or hypotheses.
Example Implementation: Gather bullet points about new superconducting materials from “materials science” with cost analysis from “economic viability” to conclude possible synergy or trade-offs.
Analysis Module
Definition: Analysis involves dissecting findings to understand their structure, validity, and implications.
Example Implementation: Evaluate the methodology of each cited study, check for contradictory data, or detect patterns across subtopics.
Evaluation Module
Definition: Evaluation is the critical assessment of synthesized insights for reliability, relevance, and completeness.
Example Implementation: Score each claim based on source credibility (e.g., peer-reviewed studies vs. blog posts) and consistency with other data.
Feedback & Iterative Refinement

Feedback Loop
Role: Determines whether additional searches are needed, or if new subtopics should be spawned.
Responsibilities:
Checks if certain subtopics lack sufficient data (gaps).
Identifies contradictory findings that require conflict resolution.
Suggests adjusting subtopic priority if new insights indicate more or less relevance.
Validation & Debate Agents
Validation Agent: Applies quality and relevance checks (similar to QA).
Debate Agent: When contradictory or contentious findings appear, it “hosts” an internal debate, referencing source credibility and logic.
Role: Assigns weight to each argument based on evidence, possibly discarding weak or unsubstantiated claims.
Implementation Detail: Could use chain-of-thought style reasoning or argumentation frameworks to compare claims.
Knowledge Base / Repository
Knowledge Graph (KG):
Use Case: Stores relationships between subtopics (nodes) and evidence (edges). Over time, can show how new data might alter the KG.
Implementation Detail: Graph DB (e.g., Neo4j, NebulaGraph).
Repository:
Stores raw data, agent-generated summaries, final reasoned outputs, and versioned historical results for re-use.
An object store (e.g., cloud bucket storage) for raw data or large PDF documents
A document DB (e.g. MongoDB, Google Firestore) for JSON documents.
Contextual Memory:
Serves as short-term memory for the current research cycle, storing ephemeral states for fast retrieval.
Detailed Workflow Stages
Stage 1: Initial Planning & Topic Decomposition

Input Research Topic
The user or a system interface supplies the primary question/goal (e.g., “Assess the feasibility of fusion energy commercialization by 2040.”).
Decomposition
The Topic Decomposer Agent employs advanced reasoning to generate a hierarchical tree of subtopics.
Identifies dependencies and potential directions for deeper exploration.
Task Assignment
The Orchestrator uses the decomposition tree to spawn specialized Search Agents for each subtopic.
Planning Milestones
The Initial Planning Module sets iteration cycles, resource budgets (e.g., how many calls to advanced models), and concurrency limits.
Stage 2: Parallel Search & Data Collection

Subtopic Searches
Each Subtopic Search Agent queries relevant resources in parallel.
They can adapt queries dynamically if partial summaries show new keywords or leads.
Data Aggregation
The Data Aggregation Service collects incoming data, merges duplicates, and organizes them for Summarization Agents.
Initial Summaries (optional quick pass)
Agents may perform quick “mini-summaries” to confirm data relevance before full Summarization.
Stage 3: Summarization & Reasoning

Summarization Cycle
Summarization Agents distill large collections of raw data into structured overviews.
Outputs might be short bullet points, highlight maps, or structured JSON.
Synthesis, Analysis, and Evaluation
Higher-Order Reasoning Agents (DeepSeek R1 & variants) integrate the summarized information across subtopics.
Synthesis: Identify novel links, formulate new hypotheses.
Analysis: Dissect the logical consistency and validity of information.
Evaluation: Determine confidence levels, check source reliability, and filter out noise.
Insight Generation
The reasoning process might reveal knowledge gaps (e.g., missing data on regulatory precedents) or highlight critical breakthroughs (e.g., new materials that can reduce reactor costs).
Stage 4: Feedback & Iterative Refinement

Result Integration
The Orchestrator collects insights from all subtopics.
Cross-checks them for conflicts or unanswered questions.
Feedback Loop
If the system detects insufficient data or contradictory findings, it triggers additional search or updated topic decomposition.
Validation Agent can also use thresholds (like coverage of certain critical domains) to decide if more iteration is needed.
Debate & Conflict Resolution
The Debate Agent surfaces disputes for deeper reasoning.
Contradictory data sets or conflicting analyses are systematically compared, using argumentation logic or confidence metrics.
Re-Iteration
If the topic is still not “saturated” in terms of data or if new subtopics have emerged, the system re-enters Stage 2 or 3 as needed.
Completion & Final Synthesis
When no critical gaps remain (based on halting criteria or user satisfaction), the final integrated research output is produced.
Design Considerations & Enhancements

Output Formats
Human-Readable Reports: Final Google Docs, PDF, or HTML documents summarizing key findings and references.
Structured Data Exports: JSON/CSV for tables, knowledge graphs, citations, and top-level bullet points.
Interactive Dashboards: Real-time progress viewing and “drill-down” capabilities in the knowledge graph.
Persistence & Versioning
Historical Research States: Each iteration’s data, summaries, and reasoned outputs are stored with timestamps and version IDs.
Incremental Knowledge Graph Updates: Each iteration updates or extends the KG with newly found relationships or revised node properties.
Agent Checkpointing: Agents can save intermediate states (e.g., partial transformations of data or partial debate results) for replay or auditing.
Scalability
Horizontal Scaling: If a subtopic spawns many branches, new search agents can be instantiated.
Agent Pooling: Maintain pools of specialized Summarization and Reasoning agents to handle surges in parallel tasks.
Evaluation Metrics
Depth of Exploration: How thoroughly each subtopic is covered.
Consensus Strength: Degree of agreement among sources or reasoned outputs.
Source Diversity: Number of unique, high-quality sources.
Novelty: Whether new or innovative hypotheses are being generated.
Security & Ethics
For sensitive research areas, consider an Ethical Review Agent or a Human-in-the-Loop for final decisions.
Respect data privacy and ensure compliance with data access policies.
Adaptive Learning
Agents can learn from each iteration (feedback on previous queries, summarizations, or error corrections) to improve future performance.
Meta-Reasoning Agent
Continuously monitors the entire pipeline for bottlenecks (e.g., slow or unproductive searches).
Adjusts concurrency or triggers advanced reasoning only when needed to save resources.
Example Use Case Walkthrough

Research Query: “Assess the feasibility of commercial nuclear fusion by 2040.”
User Input: Research goal is entered via the UI layer, specifying the timeline and scope.
Decomposition:
Topic Decomposer Agent: Splits into subtopics:
Tokamak or stellarator designs
Material constraints (e.g., superconductors, plasma-facing materials)
Regulatory and public policy environment
Economic viability and market analysis
Parallel Search:
Subtopic Search Agents:
A “Design Search Agent” queries academic databases on tokamak design.
A “Materials Search Agent” focuses on new superconducting technologies.
A “Policy Search Agent” searches government sites for legislative updates.
An “Economics Search Agent” pulls data on cost models from financial reports.
Summarization & Reasoning:
Summaries reveal a new approach to “high-temperature superconductors” that might drastically reduce costs.
Reasoning Agents identify a conflict: Some sources claim the technology is still decades away from mass production.
Debate & Validation:
Debate Agent weighs the evidence. It finds that multiple credible scientific papers support near-term breakthroughs, whereas skepticism is from older or less peer-reviewed sources.
Validation Agent confirms that more recent data has stronger credibility, adjusting confidence scores.
Feedback Loop:
The system sees a gap in public perception data, so it spawns a new subtopic search specifically for “public opinion on nuclear energy.”
Final Synthesis:
Once a consensus is reached, a unified report is generated. It includes material breakthroughs, timelines for regulatory approvals, and an economic outlook.
The knowledge graph is updated to reflect relationships between superconducting materials, cost, and commercial feasibility.
Putting It All Together
This multi-agent architecture harnesses advanced reasoning models, leverages parallel searches, and iteratively refines its strategy. By combining topic decomposition, agent-based parallelism, summarization, higher-order reasoning, and conflict resolution, the system can drive in-depth and scalable research processes.
This design enables a powerful, modular platform capable of exploring complex research questions from multiple angles, continuously improving its understanding, and integrating findings into a coherent, accessible knowledge base.
The parallel tree search and specialised agent roles section is where this gets properly interesting. The problem I keep running into with multi-agent setups like this is that the moment you spawn parallel searcher agents, you're burning through rate limits at 3-4x the normal speed. One orchestrator coordinating a searcher, analyser, and writer agent? That's three concurrent model calls per iteration.
I've been routing requests through API proxies that offer concurrent request slots at flat rates. Wrote up the cost maths here https://reading.sh/how-to-get-3x-claude-rate-limits-for-30-a-month-1d3fdb8658df and the concurrency model turned out to be the piece that made multi-agent research viable for me.
Have you built any of these architectures out in practice, or is this more of a theoretical framework for now?
Agent teams force you to think about information architecture. How do agents share context? How do they resolve conflicts? What happens when they disagree? These questions are harder than training the agents themselves.