

Comparative Analysis of Deep Research Tools
Proprietary and Open-Source Solutions

Introduction
Deep research tools are a new class of AI assistants designed to autonomously perform in-depth information gathering and analysis. Unlike a standard search or chatbot, these tools plan multi-step research strategies, browse the web or documents, and synthesize findings into comprehensive reports with source citations. Both tech giants and open-source communities have introduced solutions in late 2024 and early 2025 – notably all branding this feature as “Deep Research.” This analysis compares proprietary solutions (Google’s Gemini Deep Research, OpenAI’s ChatGPT Deep Research, Perplexity AI Deep Research, and xAI’s Grok 3 DeepSearch) against prominent open-source projects (e.g. Ollama Deep Researcher, Open Deep Research, GPT-Researcher, Jina AI’s DeepResearch, and others). We evaluate them across key dimensions: capabilities, performance, technical approach, community reception, strengths/weaknesses, and emerging trends.
Capabilities
Core Features & Functionality: All these tools aim to automate complex research tasks by iteratively searching and reading information and then producing a synthesized summary or report. They effectively conduct a mini literature review: generating search queries, retrieving relevant content, analyzing it, and compiling results. For example, Google’s Gemini Deep Research acts as a personal AI research assistant that can “explore complex topics on your behalf” and produce an easy-to-read report with key findings and links to original sources. After a user poses a question, Gemini formulates a multi-step research plan (which the user can revise or approve) and then browses the web like a human – searching, finding information, and launching new searches based on what it learns, repeating this process multiple times. This culminates in a structured report (exportable to Google Docs) with the supporting sources cited. OpenAI’s Deep Research is similar in concept: it is an agentic mode in ChatGPT that autonomously searches the web, analyzes data (including the ability to use tools like Python code if needed), and returns a detailed report. It uses the advanced GPT-4 “o3” model, and OpenAI describes it as combining web browsing, data analysis, and reasoning to produce comprehensive, well-documented reports. Notably, OpenAI’s solution is multi-modal – it can analyze not just text from websites but also user-provided files or images. It’s optimized for handling diverse inputs (e.g. PDFs, spreadsheets) and can even utilize code execution for data visualization or calculations in the research process.
Supported Research Methodologies: These AI agents excel at literature review and argument synthesis. They can gather information from many articles and websites and then synthesize the findings, often presenting pros/cons or comparisons of viewpoints. For instance, OpenAI’s Deep Research will generate an objective set of sub-questions, use a crawler agent to gather information for each, and then summarize and source-track each resource. It finally filters and aggregates all this into a cohesive report. The outputs typically include structured sections, and many can format references or bibliography. A user observed that ChatGPT’s Deep Research follows the brief and uses a lot of high-quality sources, and it can even format references in styles like APA or MLA if requested. The tools thus mimic an academic research workflow: refining the query, diving deeper based on findings, and citing evidence. Some tools even attempt rudimentary citation tracing – for example, an AI researcher might follow a reference link found in a webpage if it appears relevant, effectively tracing citations, though this behavior may depend on the agent’s prompts rather than a guaranteed feature.
Degree of Automation: All solutions provide a high degree of automation in knowledge extraction. Once the query is given, the AI takes over the heavy lifting. Perplexity’s Deep Research explicitly frames itself as doing in 2–4 minutes what would take a human many hours. It performs dozens of searches and reads hundreds of sources without further user intervention. Similarly, Google’s Gemini, under user supervision at the plan stage, will then continuously refine its analysis over a few minutes, needing no additional prompts from the user. OpenAI’s version can even ask the user clarifying questions at the start if the query is ambiguous (e.g. it might ask to narrow the scope or context), after which it proceeds autonomously. The output is typically a detailed written report. OpenAI’s reports are especially lengthy – often thousands of words (one example was 12,000 words with ~21 sources)– whereas Google’s and Perplexity’s are more concise summaries of key findings. Perplexity’s output format is a well-structured report with inline citations, and it even can include related media (images, videos) in the answer page. In fact, Perplexity will show relevant images or even AI-generated visuals alongside the textual analysis to enrich the report. Most of the proprietary tools focus on textual analysis of web content, but OpenAI and some open-source ones extend to analyzing local documents provided by the user, enabling custom data to be included in the research.
Tool-Specific Highlights: Each tool has some unique capabilities:
Gemini Deep Research (Google) – Emphasizes an agent-based approach with Google’s search expertise and a huge context window (Gemini offers a 1 million token context to incorporate lots of information). It produces a neatly organized report of findings and is integrated into Google’s ecosystem (e.g., easy export to Google Docs). It currently supports text-based queries (English only at launch) and web content analysis.
OpenAI ChatGPT Deep Research – Leverages the strongest GPT-4 model, allowing it to handle very complex queries and multi-modal input (text, images, PDFs, etc.). It can use Python code internally to analyze data, making it capable of things like data analysis or visualization during research. The output is an in-depth report that can include embedded charts or tables if the code tool is used (e.g., to plot data). It also transparently shows its step-by-step reasoning process to the user during execution, which helps users understand how the AI is proceeding.
Perplexity AI Deep Research – Focuses on speed and structured answers. It produces comparatively concise but well-structured summaries with each factual claim cited inline. Under the hood it tends to retrieve a large number of sources – testers found it pulled significantly more sources than OpenAI or Google for the same query (e.g. 57 sources vs ~20) – and it prioritizes reliable domains (Perplexity often cites academic papers, government or official sites for factual questions). It also integrates live data: because it’s built on a real-time search, it can incorporate very up-to-date information (news, financial data, etc.) better than others. Perplexity also mentions using a coding step – it combines web search, reasoning, and coding to iteratively refine analysis. For example, for a financial analysis query, it might fetch data and run a small calculation or generate a chart via code before presenting the answer.
Grok 3 DeepSearch (xAI) – Designed as a “reasoning agent” within Elon Musk’s Grok chatbot. Grok’s DeepSearch is positioned as a lightning-fast truth-seeking agent that scours the “entire corpus of human knowledge”. It is optimized to handle real-time queries (including news or social media via X/Twitter) – one showcase example was asking how people on X are reacting to a current event, indicating it can pull in social media or trending content. Its end product is a concise yet comprehensive summary of the findings. Unlike others, Grok’s agent currently emphasizes brevity in the final report (keeping it concise). It is also integrated with tool use like code interpreters for reasoning tasks, similar to OpenAI.
Open-Source Projects’ Capabilities: The open-source deep research agents mirror many of the above features, sometimes with even more flexibility:
Ollama Deep Researcher (by LangChain team) is a fully local web research and report-writing assistant. It can use any locally hosted LLM via Ollama, meaning you can run it offline with models like Llama 2 or DeepSeek. The agent generates search queries, gathers web results (using DuckDuckGo or other engines), summarizes the content, identifies knowledge gaps, and iteratively searches again to fill those gaps. The number of search/summarize cycles is user-configurable. In the end it provides a markdown report with all sources referenced. This effectively performs automated literature review in a privacy-preserving way (no data leaves your machine except the queries to the search engine). The trade-off is that its quality depends on the strength of the local model – one can choose smaller or larger models; larger ones yield better synthesis but need more compute.
HuggingFace’s Open Deep Research project used a “CodeAgent” approach. In this design, the LLM actually writes code (in a mini domain-specific language or Python) to perform actions, rather than just producing textual directives. The advantage is that code can represent complex sequences and parallelism more concisely. For example, the agent could generate a script that says: “search for X, search for Y in parallel, then wait, then read both results”. This is more efficient than a purely text prompt approach which would do these sequentially. The code-agent approach also benefits from the model’s training on programming, which can produce more structured, error-free plans compared to free-form text planning. In HuggingFace’s prototype, they leveraged tools from Microsoft’s “Magentic-One” agent (an earlier research project) such as a web browser and file reader, and had the LLM orchestrate them via code. The results showed improved performance on benchmarks (they managed to exceed previous open-agent scores on GAIA).
Open Deep Research (Nick Scamara’s project) is an open-source clone of OpenAI’s tool, using available components. It uses Firecrawl (an open web crawling service) to perform searches and extract web page text, and then passes that to an LLM for reasoning. This results in a similar multi-step deep dive, but using open APIs. It’s implemented as a web app (Next.js + Vercel AI SDK) for a user-friendly interface. It essentially demonstrates that with the right pipeline (search + scrape + GPT-4 via API), one can approximate the proprietary tools.
GPT-Researcher (Assaf Elovic’s project) is one of the most feature-rich open offerings. It is an autonomous agent that can research both the web and local files, then generate a long report with citations. Notably, GPT-Researcher includes smart image scraping – it will fetch relevant images from web sources and can filter them, potentially embedding image references in the report. It also emphasizes producing extensive reports (over 2,000 words) and can aggregate information from 20+ sources for truly comprehensive coverage. It has a memory mechanism to maintain context across steps and avoid repetition. There is a front-end (both a simple HTML/JS UI and a more advanced React interface) for ease of use. In effect, GPT-Researcher aims to match or exceed ChatGPT’s Deep Research in thoroughness. Its use of the OpenAI API (or other LLM APIs) can be configured by the user, and it can export the final report to formats like PDF or Word for convenience.
Jina AI’s DeepResearch – This project focuses on iterative Q&A rather than report generation. It will “keep searching, reading webpages, and reasoning until an answer is found (or token budget is hit)”. Jina explicitly states they do not optimize for long-form reports – instead, the goal is quick, concise answers for complex queries. It’s essentially an agent to get a correct answer with citations, making it akin to an enhanced search engine. Under the hood, it uses Jina’s own “Reader” service to fetch page content and an LLM (you can plug in OpenAI GPT-4, Gemini 2.0, or even a local model) to do reasoning. The output is an answer with references (provided as footnote-style citations). This approach is ideal when the user wants a single well-supported answer rather than a full essay.
OpenDeepResearcher (Michael Shumer) is implemented as a research notebook/Colab notebook. It continuously searches Google (via SerpAPI) and uses an LLM (Claude Instant via OpenRouter by default) to decide when the research is “done” – i.e., when no further queries are needed – then outputs a final report. It features asynchronous processing (fetching and reading multiple search results in parallel) for efficiency.
DeepResearch by dzhng, aims to be a minimal deep research agent combining search, scraping, and an LLM in a simple loop – demonstrating that even a relatively small amount of code can implement this behavior (its goal is “the simplest implementation of a deep research agent”). The rapid emergence of these projects (some were developed within 24–48 hours of OpenAI’s announcement) shows the core capability – an agentic search+summarize loop – is straightforward to recreate with open tools. The open-source agents are highly customizable (developers can tweak how many search iterations, which search engine or model to use, etc.), which means their capabilities can be tailored to specific use cases (for example, focusing only on scholarly papers, or integrating an internal document database alongside web search).
All the tools – proprietary and open – can automate iterative web research and synthesis. They differ in the breadth vs depth of output (concise answer versus exhaustive report), the types of inputs they handle (text vs. multi-modal), and any extra touches (formatting, images, etc.). But fundamentally, their capability is to significantly save researchers time by doing the heavy reading and note-taking for you, delivering a distilled knowledge product in the end.
Performance
Processing Speed: There is a notable trade-off between depth of research and speed. Among proprietary tools, Perplexity’s Deep Research is the fastest, often completing its multi-step analysis in about 2–4 minutes per query. It’s optimized to perform many searches in parallel and condense results quickly. In fact, most research tasks finish in less than 3 minutes on Perplexity, and the team is working to make it even faster. Google’s Gemini Deep Research is also relatively quick given its concise output – typically taking under 15 minutes for a full session. OpenAI’s Deep Research is the slowest of the three major services, often needing 5–30 minutes per querydepending on complexity. Users have observed that it can spend a long time (sometimes ~8–10 minutes) iterating through searches and analysis for a complex topic. This is partly because it aims for a very thorough report. OpenAI even warns that a Deep Research query may run for an extended period in the background. Grok 3’s DeepSearch emphasizes “lightning-fast” operation, but concrete timing data isn’t widely published yet. Given Grok’s use of optimized models and possibly narrower answers, we can infer it strives to answer within a few minutes as well.
The open-source tools’ performance can vary widely based on the infrastructure: if using a local LLM without powerful GPUs, they will be slower (and might even take hours for big reports if a small model is used). However, many open projects incorporate concurrency to speed things up. GPT-Researcher, for instance, can launch multiple search queries and page fetches concurrently, which helps reduce total time. Some projects using GPT-4 via API will naturally be limited by API speed and token limits (and GPT-4 is relatively slow), whereas others might use a faster-but-less-accurate model to gain speed. In practice, community tests show open solutions can produce results in the order of minutes as well. The Jina DeepResearch API, for example, is tuned for responsiveness, as it’s meant to be queried like a realtime service (with cloud infrastructure and a 1M token context allotment for the Jina backend).
Depth of Reasoning and Inference: In terms of reasoning quality and depth, OpenAI’s agent currently leads. On benchmark evaluations, OpenAI Deep Research (with GPT-4) scored highest. It achieved 26.6% accuracy on “Humanity’s Last Exam” (HLE), a notoriously difficult test of expert-level questions across many domains. This outperformed Perplexity’s agent (21.1%) and Google’s older attempt (“Gemini Thinking” mode scored ~6.2% on the same benchmark). This suggests that OpenAI’s underlying model can tackle more complex, high-level questions and perform multi-step reasoning more effectively. OpenAI’s agent also excelled in the GAIA benchmark for general problem-solving: it reached ~72.6% average accuracy, whereas previous top models were around 63%. These benchmarks indicate strong inference abilities – e.g., solving tasks that require connecting disparate pieces of information or using tools within the reasoning chain. Users have anecdotally found that ChatGPT’s Deep Research gives very detailed explanations and can handle nuanced questions that require understanding subtle context or combining facts. One early user described a Deep Research output as “weaving together difficult and contradictory concepts, finding novel connections, and citing only high-quality sources”, reflecting a high level of reasoning and synthesis.
Perplexity’s Deep Research, while slightly behind OpenAI in raw reasoning power, is still very strong in accuracy. It was reported to achieve 93.9% accuracy on the SimpleQA test (a benchmark for basic factual correctness), outperforming most other models on that metric. This suggests that for straightforward factual queries, Perplexity is extremely reliable. Its slightly lower performance on HLE implies it may not delve quite as deeply on very complex, multi-hop questions (perhaps due to a smaller underlying model or shorter analysis). Google’s Deep Research is currently assessed to be behind these two in reasoning depth – the evidence being its poorer showing on benchmarks like HLE. The Google agent tends to rely heavily on top search results (which can bias it toward popular or SEO-optimized content), and it may not be as good at reasoning through conflicting information without user guidance.
Relevance and Quality of Retrieved Sources: All tools aim to retrieve relevant, high-quality sources, but their success varies. Perplexity AI often surfaces academic and official sources, as noted – in a comparison, Perplexity’s output cited significantly more government websites and official documents, whereas Google’s cited more news articles and OpenAI’s had a mix including blogs. This indicates Perplexity’s search strategy is tuned to find authoritative sources (likely due to its legacy as a citation-focused engine). Google Deep Research can leverage Google’s powerful search algorithms, but it has a tendency to pick sources that rank high on Google – which can introduce SEO-driven bias. In practice, reviewers found Google’s agent would sometimes cite less scholarly sources or even tangential webpages if they happened to match keywords. The Helicone AI blog noted that Google’s Deep Research is “prone to SEO‑bias and less reliable citations”. Users have also reported cases where Gemini’s citations didn’t directly support the claims made (possibly referencing the wrong section of a page). OpenAI’s Deep Research generally provided good sources, including peer-reviewed papers when appropriate, but it has been caught hallucinating sources at times – i.e. inventing a reference that looks real but isn’t. Because the reports are long, a made-up citation can be buried in there. OpenAI’s own evals acknowledge fabrication of sources or misinterpretation of data as a limitation. That said, when it cites real sources, they are often quite relevant and specific (thanks to the model’s ability to parse content).
In open-source agents, source quality depends on the search API used. Those using SerpAPI Google search will inherit similar results to Google’s tool. Projects using Bing or other APIs might get a different mix. Notably, GPT-Researcher claims to aggregate 20+ sources for objective conclusions, and it uses a filtering step to remove duplicates and presumably low-quality links. It also “source-tracks” each snippet of information, so the final report can list which sources back each point. This approach tends to maintain high relevance (and makes it clear if only one source is supporting a claim, versus multiple). Jina’s DeepSearch is focused on finding the correct answer, so it likely uses a reranker or reader model to ensure the sources it stops on indeed contain the answer. Jina’s output provides citations in footnote format, which implies it is extracting specific facts and linking them to the reference. In terms of quality, the open solutions can be configured to target certain domains (for instance, one could instruct an agent to focus on scholar.google.com results if academic quality is needed). Overall, Perplexity appears to have a slight edge in consistently retrieving trustworthy sources by default, whereas OpenAI’s strength is in synthesizing from many sources even if a few might be imperfect, and Google’s strength is in broad coverage (finding a wide range of info quickly, albeit needing caution in trustworthiness).
Synthesis and Summarization Ability: All tools are capable of summarizing complex information, but OpenAI’s and Open-source GPT-based solutions tend to produce the most detailed narratives. OpenAI’s Deep Research was designed to “extract and condense complex concepts effectively” – detailed summarization is listed as a key strength. Users have praised how it can connect concepts and even provide insightful comparisons. For instance, Ethan Mollick’s commentary (as cited in Leon Furze’s review) noted the output “found novel connections…cited only high-quality sources, and was full of accurate quotations”. This indicates a very high level of synthesis where the AI isn’t just copying text but truly writing an integrated analysis. However, a limitation noted for these AI is the lack of truly original insight – they excel at combining known information but generally do not generate new hypotheses or deeply interpret on a level beyond their training. So, while the summary is coherent and often structured like an expert’s writing, it won’t necessarily produce a groundbreaking conclusion that wasn’t already implicit in the sources.
Perplexity’s summaries are shorter by design – aiming to directly answer the question and provide key points. They are structured and concise. This often means less prose and more bullet-point style or enumerated facts. That makes them very digestible, though sometimes “shallower” in the sense that they might not explore tangential aspects. Google’s reports are in between: more concise than OpenAI, but typically the Gemini agent will list key findings for each subtopic in a readable manner. One could say Google’s synthesis is more outline-like, whereas OpenAI’s is essay-like, and Perplexity’s is summary-like. Open-source agents vary: GPT-Researcher explicitly tries to produce long-form text (2000+ words), likely with headings and paragraph breakdowns. Others like Jina’s produce one or two paragraphs answer. Notably, all tools strive to maintain coherence across the report – thanks to large context windows (OpenAI and Google use up to hundreds of thousands or even a million tokens of context, and some open-source use streaming or external memory to hold many sources). The result is that the final report usually reads well, without obvious jumps or contradictions. However, small inconsistencies can creep in. OpenAI’s agent sometimes contradicts itself if different sources said different things (e.g., it might include two opposing stats unwittingly). This happens if the model doesn’t reconcile conflicts properly. Google’s agent might not catch subtle nuances, and Perplexity’s brevity might gloss over exceptions. In general, though, users find the summaries extremely helpful as a starting point – often “a step up from GPT-4’s normal response” in terms of detail and accuracy.
Error Rates and Reliability: In terms of factual reliability, Perplexity and Google have an advantage of directly quoting or linking sources for each statement, which makes it easier to verify each part of the summary. OpenAI’s long report format can bury an error. All three proprietary solutions still carry a risk of hallucination or error. OpenAI’s has been noted to sometimes “misinterpret data or provide outdated info”, and if an error occurs early in the reasoning chain it might propagate into the final report. The tools do not have true “common sense” verification; they trust the sources (and their own understanding). So one must still critically review the output. The performance takeaway: OpenAI’s Deep Research provides the deepest analysis but at the cost of speed and with some consistency issues, Perplexity offers high accuracy and speed in a somewhat lighter package, and Google’s is efficient and user-friendly but can be less reliable if not monitored. The open-source tools can approach OpenAI’s depth if using GPT-4, or trade off some accuracy for full control (e.g., using Claude or local models). Many open-source users run these agents with GPT-4 via API to get similar performance to OpenAI’s official offering, and some report very good results – though they may lack the fine-tuning OpenAI applied to minimize certain errors.
Technical Approach
Underlying Models and Architecture: Proprietary services each use their own large language models (LLMs) and sometimes custom-tuned versions for the Deep Research task. OpenAI Deep Research is powered by a specialized version of GPT-4 (referred to as “o3” in some sources), which is fine-tuned for long-context reasoning and tool use. This model is an improved ChatGPT with presumably a larger context window (reports suggest 128k token support for some Deep Research queries) and optimized for multi-step answers. Google’s Gemini Deep Research runs on the Gemini family of models (Gemini 1.5 Advanced at launch, and likely moving to Gemini 2.0). It couples that with Google’s search infrastructure. Notably, Google mentioned a “new agentic system” directing the Gemini model– likely this is a framework that plans steps and feeds the model information, similar to a ReAct chain. Perplexity’s Deep Research likely uses a combination of in-house LLMs. Perplexity has not fully disclosed its model, but the benchmark data suggests it might not be as large as GPT-4, yet it performs well due to efficient retrieval and possibly some fine-tuning. (Perplexity historically used a fine-tuned 13B model for their assistant; they may have upgraded or ensemble models for Deep Research to boost performance, given the high accuracy on SimpleQA). xAI’s Grok 3 uses the Grok model, which is a new LLM trained by xAI. Grok 3 claims strong performance on academic benchmarks (e.g., near GPT-4 level on some tasks). They actually have two modes: a standard mode and a “reasoning” mode. The DeepSearch agent presumably uses the reasoning-optimized Grok 3 model, which is designed to handle tool use and multi-turn reasoning.
The agent architectures share similarities. Most follow a paradigm of: Plan → Search → Read → Synthesize (repeat as needed). OpenAI’s system uses an internal agentic framework (not publicly described in detail) that guides the model’s actions step-by-step. It’s essentially the model conversing with an internal “orchestrator” that tells it when to use the browse tool, etc. Google’s Gemini Deep Research explicitly asks the user to approve a research plan– that indicates the system formulates a sequence of sub-queries first. After approval, it likely executes those one by one (or in parallel). That is slightly different: Google front-loads the planning phase with human input, whereas OpenAI/Perplexity do it behind the scenes. Perplexity’s agent is described as iteratively searching and refining with integrated “coding.” It likely uses a chain where the model can call either a search API or a code interpreter. For example, if Perplexity’s model thinks it needs to calculate something (say, summarizing statistics from sources), it can execute code to do so. This is analogous to OpenAI’s Code Interpreter tool, but here it’s part of the research agent’s loop. Grok’s DeepSearch is similarly integrated with tool use (internet and code) as noted. xAI described that their models learn to query for missing context, adjust approach, and improve reasoning based on feedback– suggesting a reinforcement learning or iterative prompting setup guiding the agent’s architecture.
Proprietary vs Open LLMs: Proprietary tools use proprietary LLMs (GPT-4, Gemini, Grok). The open-source tools can use open LLMs or API-based LLMs interchangeably. For example, Ollama Deep Researcher can plug in any model you have in Ollama – from LLaMA-2 variants to specialized ones like DeepSeek R1 (an open model tuned for multi-step reasoning). Many open projects default to using the OpenAI API (GPT-4) because of its quality, but they allow swapping in others like Anthropic’s Claude or local HuggingFace models. OpenDeepResearcher uses OpenRouter to be model-agnostic (OpenRouter is a proxy that can route to different models, defaulting to Claude-3.5 for speed). Jina’s DeepSearch even supports a local mode – by setting LLM_PROVIDER=local and providing a local model, one could run without external LLMs. However, the performance will vary; smaller open models (6B-13B parameter range) might struggle with the complex reasoning and large context, so some open-source devs are working on tuning models specifically for this task (the DeepSeek R1 model is one example of an open model optimized for multi-hop search tasks). Indeed, DeepSeek R1 is cited as a model in this space, though it scores lower than proprietary ones on benchmarks (around 9% on HLE). The use of large context windows is also part of the technical approach: OpenAI and Google have 100k+ token contexts, and open projects use techniques like iterative summarization or retrieval to simulate large context. Some open models (like Mistral or Claude Instant) can handle 100k context via external memory too.
Information Retrieval Methods: All these agents rely on web search for information retrieval, but the methods differ:
Google uses the live Google Search engine (with all its ranking algorithms). This is a high recall method (finds a lot) but can include noise.
Perplexity likely uses its own search index/API (possibly Bing or a hybrid). It specifically mentions advanced web search combined with reasoning. It might lean on a custom index for certain trusted sites.
OpenAI’s agent uses the Bing API for web browsing (ChatGPT’s browsing beta was Bing-based). However, it might also accept file uploads, which is a form of retrieval (from user-provided data). Additionally, OpenAI’s approach with a code interpreter could retrieve information from data files.
Hybrid retrieval: Some open-source tools integrate vector database retrieval for specific corpora. For instance, if you point GPT-Researcher at a set of local PDFs, it could vector-index them and query them as needed in addition to web search. The standard pipeline though is keyword search + scrape. A few open projects use Browser automation (e.g., using Playwright or similar) to handle dynamic content, and one (GPT-Researcher) explicitly notes JavaScript-enabled web scraping to handle sites that require JS to render. This is a technical differentiator: proprietary tools likely have internal capability to handle most sites (Google’s uses Google’s cache or direct crawl, OpenAI’s browser agent can click through pages, etc.), but some sites might block bots. The open agents that use their own scrapers sometimes hit paywalls or Cloudflare blocks – thus requiring API-based extraction (Jina’s solution is to use their jina.ai/reader service to reliably get page text). Nickscamara’s Open Deep Research relies on Firecrawl (which extracts structured data from webpages) – this is an interesting approach as Firecrawl may summarize or clean the page content before it even reaches the LLM. That can save token space and possibly improve signal-to-noise.
Integration & Extensibility: Proprietary offerings currently have limited integration options. OpenAI and Google have not yet exposed Deep Research via API (these features are only in their chat interfaces, not for programmatic use). Perplexity’s is accessible on their website and soon apps, but again no developer API (though the service itself is free to use through their UI). In contrast, open-source tools are designed for integration. GPT-Researcher can be installed as a Python package (pip install gpt-researcher) and used as a library – one can instantiate a GPTResearcher object and call conduct_research() and write_report() in code. This makes it easy to plug into other applications or workflows. Jina provides an official DeepSearch API endpoint that is OpenAI-compatible. That means a developer can use it like calling the OpenAI API, but get the DeepSearch functionality (the model is called jina-deepsearch-v1 and it handles the tool use internally). Such efforts hint at emerging standardization of interfaces – e.g., using special tokens or messages to indicate when the model is “thinking” vs providing the final answer.
For user-facing integration, Google’s solution ties into Google Docs (exporting) and will come to Workspace accounts, which could make it a handy tool for students and analysts to directly populate documents. OpenAI might integrate theirs with forthcoming features like “Operator” (the mention of integrating with Operator suggests a future where the agent can take actions beyond writing – Operator is OpenAI’s plan for agents that can act in the world). On the open side, many projects have Gradio or web UIs (to make them easy to run locally with a GUI). Some even support plugins – for example, GPT-Researcher has a plugin system to incorporate different search engines or output formats. The architecture of most open implementations is modular, meaning one can swap out components (search, LLM, data storage). This modularity is a deliberate technical choice to allow experimentation on each part of the deep research pipeline.
The technical approaches are convergent in using an agent loop with LLM + search tool, but they differ in model choice (proprietary vs open), context handling, and integration. Proprietary models currently hold an edge in raw capability, but open frameworks are catching up by allowing those same proprietary models to be used within open agents (when one uses GPT-4 API in an open project) and by fine-tuning open models for the task. We’re also seeing the beginnings of standards – such as OpenAI-compatible APIs for agent services (Jina) and common formats for outputs (citations in markdown footnotes, etc.) – that could make these tools interoperable in larger ecosystems.
Community Reception & Adoption
User Feedback and Reviews: The introduction of Deep Research features has generated a lot of buzz in online communities. Early user feedback often praises the concept but points out practical limitations. For OpenAI’s Deep Research, many users (especially researchers and professionals) were excited by its potential. On the OpenAI forum and subreddit, users shared examples of Deep Research producing very detailed analyses that would have taken them days to assemble. However, some also cautioned that it can overlook certain sources (e.g., not having access to paywalled academic papers was mentioned as a shortcoming) and that it occasionally included an irrelevant reference. There were also reports of hallucinated references, which made a few users skeptical – as one blog humorously noted, a limitation is that it may “fabricate sources…and cite incorrect facts — which will be hidden in a lengthy report!”. This underlines a trust issue: while most of the content is great, any mistakes require careful proofreading to catch.
For Google’s Gemini Deep Research, user reception has been mixed. On one hand, it’s far more accessible (only $20/month via Google One or Workspace, versus OpenAI’s $200/month Pro tier), so more users could try it. Casual users appreciated how it saves time and finds info you might not have found otherwise. The integration with Google search meant it was good at finding recent news and web articles. On the other hand, tech-savvy users on forums pointed out the “SEO bias” – if a topic’s top Google results are low-quality content, Gemini might end up summarizing that. Some reported that Gemini’s answers, while generally solid, weren’t as deep as they expected for truly complex topics. It might stop after summarizing 10–15 sources which cover the basics, whereas they wanted more analysis. Also, since it doesn’t show the step-by-step process to the user (it only shows the final plan and final report), a few people felt it was a bit of a black box. Nonetheless, in communities like Reddit’s r/Google and r/AI, people have been experimenting with it (for example, grad students testing it on research for their thesis) and often say it’s “impressive for a first version” but “not ready to be trusted blindly.” There have been some early bugs – e.g., instances of the Gemini Deep Research returning an error (“Something went wrong”) for certain queries, which Google is likely addressing as it’s rolled out.
Perplexity AI’s Deep Research has garnered positive reception for its free availability and speed. Many users on the r/Perplexity subreddit expressed excitement that a free (5 queries/day) tool could do what paid ChatGPT does. People like that every sentence is cited, which gives confidence. Some journalists and content creators found it useful for quickly pulling facts together for an article (one described it as getting a “structured briefing” on a topic). The main critique from power users is that it doesn’t go deep enough on certain queries – by design it stops at a concise summary, so it might not explore every nuance unless you ask follow-up questions. But generally, because it’s fast and straightforward, adoption is quite high. It also helps that Perplexity integrated this mode into their mobile app and other platforms promptly, so usage isn’t limited to desktop. A telling sign of community interest is that all three major companies – Google, OpenAI, and Perplexity – independently chose the same name “Deep Research,” which reflects user demand for such a capability across platforms.
Adoption in Different Communities:
In academic and research circles, OpenAI’s Deep Research has seen interest, but its $200/month Pro price is a barrier for many. Some academics with access (or who used the limited free trials OpenAI offered to some) have demonstrated it at lab meetings or on social media, showing how it can gather literature on a topic rapidly. However, universities and libraries are cautious – they note that while it’s a great assistant, it shouldn’t be the only tool (since it can’t access certain databases or do critical analysis). Google’s offering, if integrated into Google Scholar or similar, could find a niche in academia, but that hasn’t happened yet. Meanwhile, open-source tools are being eagerly tried in academic and open science communities, because they can be self-hosted and customized. For example, GPT-Researcher (assafelovic’s) reaching 19k stars on GitHub indicates huge interest, and contributors are already adding features (there are many community pull requests and forks). Researchers in AI have been quick to reproduce OpenAI’s results – the Hugging Face team’s 24-hour reproduction of DeepResearch using open models was widely lauded as a win for open science. Within days of OpenAI’s release, multiple GitHub projects named “Open Deep Research” or similar popped up, each gaining thousands of stars (dzhng’s deep-research repo has ~12k stars, Nickscamara’s 4k+, etc.). This indicates that the developer community is very keen on the concept and wants to create accessible versions for everyone. We also see a lot of discussion on forums like Hacker News about using these open tools to, say, integrate into one’s own knowledge management system or to conduct research for blog posts.
In the corporate sector, tools like OpenAI’s and Google’s are eyeing integration into workflows. Google plans to offer Gemini Deep Research to enterprise Google Workspace users (early 2025), which could drive adoption in businesses for market research, competitive analysis, etc. Some companies are experimenting with OpenAI’s Deep Research for internal reports (within the limits of data privacy – some are cautious to not have proprietary data fetched or uploaded). The absence of an official API holds back deeper enterprise integration for now. However, platforms like Jina AI’s are directly targeting enterprise adoption by providing an API and generous free token limits for developers to test. This could facilitate startups and products building on Deep Research capabilities. Indeed, one can envision news aggregators, consulting firms, or legal research tools building custom UIs over something like Jina’s DeepSearch API or GPT-Researcher, tailored to their domain.
Strength of Contributor Communities: The open-source projects vary in community size. GPT-Researcher has a very strong community – frequent commits, active discussions, and its developer is continuously adding features (for example, the improved frontend and multi-agent capabilities announced in updates). The project’s issue tracker shows users suggesting enhancements like support for more file types, translation, etc., indicating active engagement. The HuggingFace Open-DeepResearch effort brought together several well-known AI devs (the authors listed include HF’s Thomas Wolf and others), which lends credibility and momentum – although that was more of a prototype, it may evolve into a library. Langchain’s Ollama Deep Researcher is backed by the LangChain team (popular for chaining LLMs), so it benefited from their existing community of developers interested in chaining and agents. In general, since the task of “AI research agent” has captured imagination, we see a convergence of communities: the Autonomous AI agents (AutoGPT/BabyAGI) crowd, the information retrieval researchers, and the LLM prompt engineering enthusiasts all have come together to contribute to these open projects. This means rapid iteration and shared standards likely will come from open-source.
Meanwhile, the user communities around proprietary tools are forming mostly on official forums and Reddit. Perplexity has an official subreddit where the CEO and team occasionally answer questions, and users share their Deep Research outputs. OpenAI’s community forums have threads like “share your Deep Research results” and discussions about best prompts to use (for example, how to scope a query to get the best report). Google’s community is a bit quieter (possibly because fewer people have Gemini Advanced access yet), but support forums have questions on how to enable it, and some reviews on Medium have started to appear (one Medium blog concluded Google’s feature has significant potential but is not without flaws, like occasionally unrelated refs).
Adoption relative to Traditional Research: It’s worth noting that while adoption is growing, these tools are assistants rather than replacements for experts. Many students and professionals are testing them for gathering background info or summarizing existing knowledge, but they are cautious about using the results verbatim. The community consensus as seen in discussions is that Deep Research tools are great for a first draft or overview, after which a human should verify and refine. This cautious optimism is a healthy form of adoption – it means the tools are being used, but with human oversight, which is exactly the scenario their creators intend (AI to save time, human to ensure accuracy).
In summary, community reception has been enthusiastic about the potential time-saving and breadth of these tools. OpenAI’s offering is seen as the most powerful but limited to an elite user base right now. Google’s is applauded for being more accessible, though slightly less trusted for rigorous work. Perplexity’s free Deep Research has arguably the broadest immediate user uptake due to zero cost, making “AI research assistance” available to the masses. The open-source community has embraced the concept wholeheartedly, rapidly reproducing and even improving on aspects of the closed-source tools. This bodes well for the continued evolution of deep research agents, driven by community feedback and contributions.
Strengths, Weaknesses, and Best Use Cases
Each deep research tool has its own advantages and limitations, making them suitable for different use cases:
OpenAI Deep Research (ChatGPT) – Strengths: Unmatched depth and thoroughness of output. It can handle complex, niche topics especially well, making connections across diverse sources that less capable models might miss. It’s excellent for technical and academic research where you need extensive context and nuance. It also supports multi-modal input (attach papers, images, etc.), which is great for tasks like analyzing experimental data in a paper alongside web literature. Another strength is the transparency of its reasoning: it shows a live chain-of-thought and follow-up questions, which is educational and useful for trust. Weaknesses: The obvious one is cost – at $200/month, it is out of reach for many individuals and small organizations. This limits its use to those who absolutely need its power. It’s also slow for quick questions; if you just want a simple fact, the long report is overkill (and a normal ChatGPT would do). While detailed, it can sometimes overwhelm with information, including possibly conflicting or extraneous details. And as noted, it may still hallucinate or err in citations, so you cannot 100% trust it without verification. Best Use Cases: In-depth reports, literature reviews, or exploratory research in domains like science, law, policy, history – where a user needs a comprehensive briefing. It’s ideal when you “need extensive reports on a topic rather than short answers,” for example a market analysis, a policy whitepaper draft, or a technical state-of-the-art survey. Conversely, it’s not worth using for simple fact-finding or questions where a quick search suffices.
Google Gemini Deep Research – Strengths: Integration and ease of use stand out. It sits right in the Gemini AI Assistant interface, so using it feels seamless for those already in Google’s ecosystem. The approval of a research plan gives users a sense of control and confidence over the agent’s direction. It leverages Google’s unparalleled search index, often finding relevant webpages quickly. It’s also comparatively affordable – available with a Google subscription (~$20/mo), and likely to be included in enterprise Google accounts many companies already pay for. It produced organized summaries that are easy to skim (good for getting the gist fast). Weaknesses: Its reliability is not as strong as others – due to SEO bias and sometimes less reliable citations (it might cite a page that isn’t an authoritative source). It seems less suited for highly technical deep dives; for example, on specialized academic questions it performed worse in benchmarks. Another limitation is that it currently supports only text input (no direct file uploads into Gemini’s web version as of now for Deep Research) and only outputs in a Google Docs/text format (no fancy charts or images). Essentially, it’s focused on general web-based research – great for news, general knowledge, business research – but not the best for hardcore academic synthesis. Best Use Cases: General research tasks and exploratory web inquiries. For instance, if a user wants to “gather a competitor analysis and location recommendations for a new business” or “research recent marketing campaigns for planning”, Google’s Deep Research is advertised as perfect. Indeed, use cases like business intelligence, journalism research, or preparing a briefing on a broad topic (where sources will be mainly news, blogs, websites) play to Gemini’s strengths. It’s also a good training wheels version of deep research for those new to AI, given its guided plan – one can trust it for basic questions and structured reports but should be careful relying on it for academic or highly sensitive research without double-checking sources.
Perplexity Deep Research – Strengths: Speed, convenience, and solid accuracy. It’s the only one of the big three that offers a free tier, making it accessible to students or anyone on a budget. It excels at producing concise yet well-cited answers, which are easy to read and directly answer the query. This makes it highly efficient – you get exactly the information you asked for, with sources attached. It’s been optimized to ensure facts are correct (its high SimpleQA score reflects this). Also, it can incorporate real-time data from the web – great for current events, stock info, etc., something especially useful for journalists or analysts needing up-to-date info. Weaknesses: Because it keeps answers short, it might omit details that could be important for deeper understanding. If the user needs a long-form discussion or extensive context, Perplexity might not provide that unless you explicitly ask follow-up questions for more detail on each point. Its model, while good, is slightly below OpenAI GPT-4 in handling extremely convoluted queries (the difference showed in the HLE benchmark and some anecdotal tests). Another weakness is the 5-query/day cap for free users – heavy users will need to subscribe to Pro (which at $20/month is reasonable, but still a limitation to be aware of). Best Use Cases: Quick, structured research tasks and Q&A. It’s ideal when you have a clear question and want a well-referenced answer fast. For example, investigative journalists have used it to quickly gather facts and official stats on a topic before writing an article. Students might use it to get a summary of a concept with references to dive deeper (essentially a much better Wikipedia). It’s also great for real-time inquiries: e.g., “What’s the latest guidance on COVID travel restrictions?” – Perplexity can search news and government sites and give a summarized answer with current citations. Essentially, for short research (a few minutes) on topics where getting the answer right is crucial and you’re okay with a summary format, Perplexity is a go-to.
xAI Grok 3 DeepSearch – Strengths: Reasoning and “truth-seeking” focus. Grok’s DeepSearch is designed to handle conflicting information and dig out facts from noise. This suggests it’s strong in scenarios where the data is messy or opinions clash – the agent will attempt to compare and reason out the truth. It’s also integrated with the X (Twitter) platform in some way (given the context of xAI), which could mean it’s particularly good at pulling info from social media or understanding trends in user opinions. Speed is another strength; being described as lightning-fast implies it tries to give answers in near real-time. Also, for those who have X Premium (the likely requirement for Grok access), it’s an included benefit, so in that context it’s essentially no incremental cost. Weaknesses: Grok and its DeepSearch are quite new and relatively untested by independent third parties. There’s not as much public data on its accuracy. Given its concise output philosophy, it might not satisfy a user looking for a detailed report. Also, its availability is limited (it’s in beta for X Premium+ users at the moment), so community support is smaller. Until the Grok 3 API is out, it’s only via the X interface which is non-traditional for research queries. Best Use Cases: Monitoring and synthesizing current information and discussions. If one wants to “keep up with a world that never slows down” by having an AI digest live information, DeepSearch suits that. Think of use cases like tracking public sentiment on a topic, getting a quick analysis of “what if” scenarios (their example: “What if I bought $TSLA in 2011?” – a mix of historical data and reasoning), or just quick advice queries that involve web lookup. It’s likely useful for general knowledge Q&A and timely queries where being concise and correct is more important than being exhaustive.
Now, for open-source tools in terms of strengths/weaknesses and use cases:
GPT-Researcher (open-source) – Strengths: Extremely feature-rich and highly customizable. Its ability to incorporate local documents means it’s great for hybrid research (e.g., analyze my company’s internal PDFs and relevant web info together). It generates long, well-structured reports with references, much like OpenAI’s output. It supports images and can output to different formats, which is excellent for creating presentation-ready or report-ready documents. Since you control it, you can also enforce certain policies (for example, you could restrict it to only cite academic journals if you wanted). Also, cost-wise, running GPT-Researcher with your own API key might be cheaper for sporadic use than maintaining a ChatGPT Pro subscription – you pay only for what you use (though heavy use with GPT-4 could still rack up, it’s usage-based). Weaknesses: It requires some technical setup; it’s not a plug-and-play web app for non-developers (though they have provided a basic UI, it’s still self-hosted). Without a powerful model, its performance drops – so one often ends up using OpenAI API anyway (meaning it’s not fully “free” to operate at high quality). It can also be resource-intensive: aggregating 20 sources and processing images, etc., can tax memory and CPU/GPU. Debugging issues (like if it hits token limits or a website doesn’t load) is on the user. Use Cases: Developers or power users who need a tailor-made research agent, or organizations that want an in-house solution. For example, a consulting firm could integrate GPT-Researcher into their knowledge base to automatically research client industries, with the output then reviewed by an analyst. It’s also great for anyone who wants the maximum control – e.g., you want to experiment with different prompting strategies or incorporate proprietary data; GPT-Researcher provides the framework to do so.
Ollama Deep Researcher – Strengths: Complete data privacy and offline capability. Because it runs locally with local models and uses non-tracking search (DuckDuckGo by default), it’s ideal for those concerned about cloud data leaks. It’s also relatively lightweight to run – you can pull a 7B or 13B model and not require expensive API calls. The iterative gap-filling approach ensures thoroughness within the limits of the model’s knowledge. Weaknesses: The quality of results depends heavily on the chosen local model. Currently, no local model rivals GPT-4; even the best (Llama-2 70B, etc.) might miss subtle points or give more hallucinations. So the depth and accuracy might be lower. It also might struggle with very long sources due to local context limits (though it reflects and cycles to mitigate this). Use Cases: High confidentiality research (e.g., a lawyer researching a sensitive case without any queries leaving their secure network), or situations with no internet (it can work offline if you supply it with downloaded documents). It’s also good for tech-savvy hobbyists who want an AI research assistant but don’t want to pay API fees or rely on big tech services.
OpenDeepResearcher (Shumer’s) / similar notebook implementations – Strengths: They demonstrate cutting-edge techniques (async search, concurrent processing) that yield speed benefits, and use multiple services (SerpAPI + Jina + Claude) in one pipeline. For someone who wants to see how it all works or tweak each step, these are fantastic. Also, running in Colab or a notebook is very accessible for experimentation – no installation needed beyond having API keys. Weaknesses: Not a polished product – it’s more a reference implementation or for one-off use. You wouldn’t ask a non-technical colleague to run a Jupyter notebook every time they need research done. It also currently requires multiple API keys (SerpAPI, Jina, OpenRouter) which might be a hassle to obtain/configure. Use Cases: Experimentation and learning, or highly specific research where you want to manually oversee each iteration. It’s a great playground for AI researchers to test improvements to the agent (like trying a different LLM or adding a new decision heuristic) and for students learning about AI agents.
Jina DeepResearch – Strengths: Very focused: it provides fast, accurate answers with citations via an easy API. It also integrates directly with existing OpenAI client libraries (due to API compatibility), so a developer can swap this in place of a normal model to get better factual grounding. The fact that it’s hosted with a generous free tier (1M tokens) lowers the entry barrier. Weaknesses: Not meant for long reports; if you try to force it to produce an essay, it won’t – Jina explicitly states it’s not for generating long-form articles. It’s also somewhat at the mercy of the Jina infrastructure for quality (their custom model and search need to be good). And since it’s relatively new, some developers might be hesitant to rely on an API from a smaller company compared to OpenAI or Google. Use Cases: Integration into apps where you want a “research brain” behind the scenes. For instance, a chatbot in an education app could use Jina DeepSearch so that when students ask a complex question, the bot can fetch reliable info and answer with sources. It’s also useful for users who want a quick command-line or programmatic tool to answer tough questions (one could script queries to Jina’s API for automating some reporting tasks, etc.).
Overall, to choose the best tool, one should consider: How complex is my query? How important is absolute accuracy? Do I need a lengthy report or just an answer? Am I okay with proprietary systems or do I need custom control?
In a nutshell: OpenAI’s Deep Research is the go-to for the most complex, high-stakes research where depth is valued (e.g., a researcher exploring a new field, or an analyst compiling a detailed report). Google’s Deep Research is great for broad, general-topic research and for users who want a quick but decently thorough overview (like a business owner researching market info, or a student writing an essay outline). Perplexity shines in quick turnaround factual research and structured Q&A (journalistic facts, straightforward research questions for work or study) especially when budget or time is tight. Grok DeepSearch could become useful for social media and trend analysis or real-time queries given its design, but it’s still emerging. Among open-source: GPT-Researcher and similar are powerful for those who need an adaptable solution (like building your own research assistant tailored to a domain), while Ollama Deep Researcher is for those prioritizing privacy and offline usage. Each has niches: for example, a medical researcher might prefer OpenAI’s or GPT-Researcher (to ingest PDFs of studies), a journalist might lean on Perplexity (to get quick facts with links), a strategic analyst might use Google’s for a broad scan of news and reports, and a developer might use Jina’s in their app to give users a fact-checked assistant.
No single tool is universally “best” – but the good news is that the strengths of one can complement the weaknesses of another. Some power users even employ multiple: e.g., run Perplexity for a quick snapshot, and OpenAI for a deep dive, then compare and compile. The ecosystem allows users to pick the right tool for the job.
Emerging Patterns & Standards
The rapid development in deep research tools has revealed several trends and emerging standards in how AI handles complex information tasks:
Agent-Based Architectures
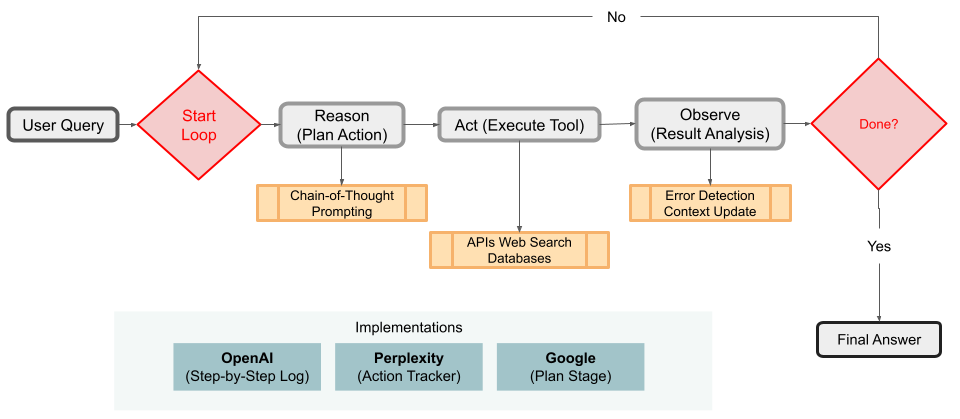
A clear pattern is the rise of the LLM-as-agent model. All major tools implemented a form of what AI researchers call the ReAct (Reason+Act) paradigm – the AI can not only answer but also take actions like web search or running code as intermediate steps. This agentic approach is becoming standard for any “deep” AI task. Even beyond research, we see it in things like coding assistants or data analysis assistants. The specific pattern of planning, tool use, reflection, and output is being reused widely. For example, OpenAI’s and Google’s systems both explicitly have a planning phase (OpenAI’s hidden, Google’s user-visible). The agent loop diagram in Jina’s README (search-read-reason repeat) essentially formalizes a standard workflow that others also converged on. We can expect future AI frameworks to include agent capabilities out-of-the-box. Indeed, the HuggingFace team open-sourced a library called smol-agents around this time, which they used to prototype their DeepResearch clone. Agent-based AI is quickly becoming a default design for complex tasks, moving away from single-turn Q&A to multi-turn autonomy.
Large Context and Memory
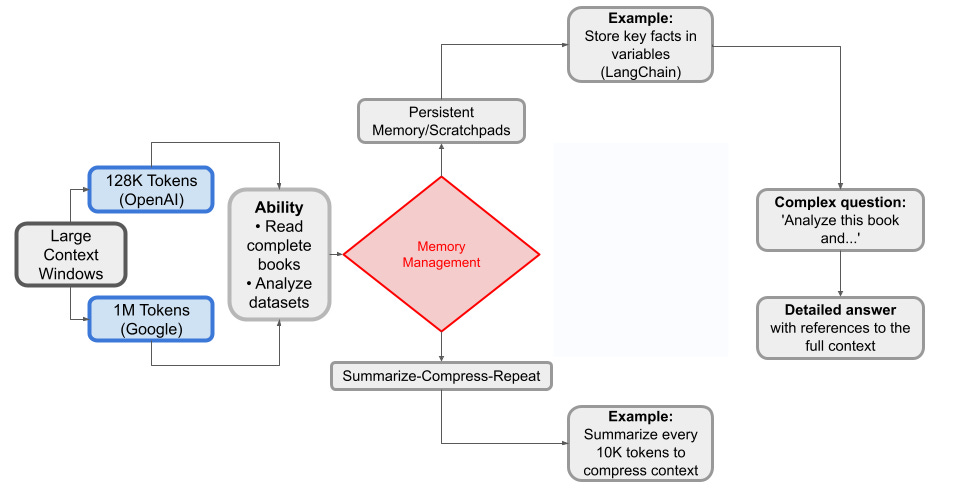
Another trend is pushing context window limits. Google and xAI tout 1M token contexts, and OpenAI has been testing 128k. The reason is clear: deep research involves a lot of text (many source documents). Rather than dropping information, these systems are trying to retain as much as possible to synthesize holistically. One emerging approach is hierarchical summarization – the agent might summarize batches of sources, then summarize those summaries, to cope with context limits (OpenAI’s approach internally, and how open reproductions handle exceeding 100k tokens). This is leading to a standard practice of dividing a big task into sub-tasks that fit context, which is evident in open implementations (they iterate until no more new info is found). Memory beyond just context window is also being considered: e.g., caching results of previous searches so they aren’t repeated (duplicate filtering), or using embeddings to recall if a certain source was seen before. Over time, we might see standardized “research memory” components – perhaps shared databases of facts that agents consult to avoid re-reading the same site anew each time.
Structured Outputs with Citations
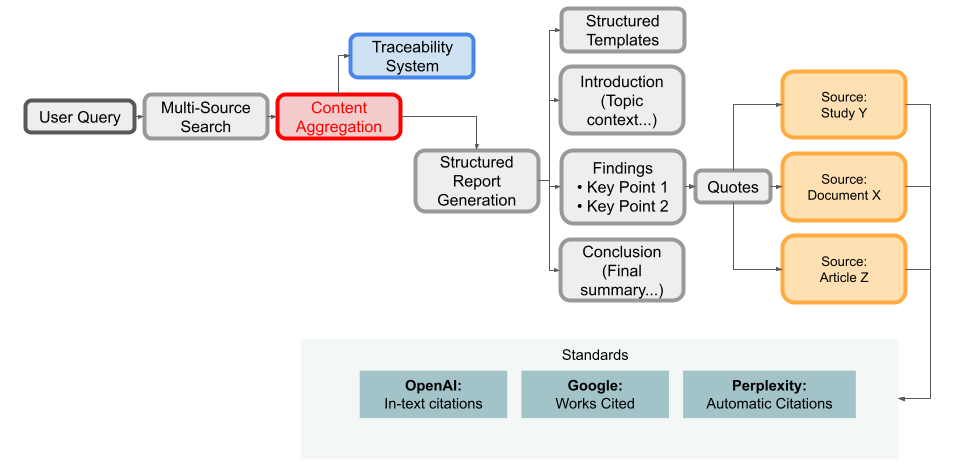
A notable standard set by these tools is that the output is a structured report with sections, bullet points, etc., and importantly, citations for each major claim. This was not common in AI answers before – ChatGPT would give you prose with no sources. Now, both enterprise users and normal users will likely expect source citations as a default for any factual multi-source answer. We see a commitment to this standard: OpenAI’s Deep Research cites specific passages from sources in a clear way, Google’s report links directly to original webpages, and Perplexity has always cited its answers. This is establishing a norm of AI-generated content being traceable. It’s a crucial shift for trust – and likely will extend beyond these tools (e.g., Bing Chat and others are also citing sources more). The structured format (with headings like “Introduction, Findings, Conclusion” in reports) is also becoming common. It makes the AI’s output more digestible and professional. We might see standardized templates or schemas for AI research reports in the future, especially for enterprise use (so that the output can be easily imported into documents or presentation slides).
Tool Use Expansion (Coding, Calculators, etc.)
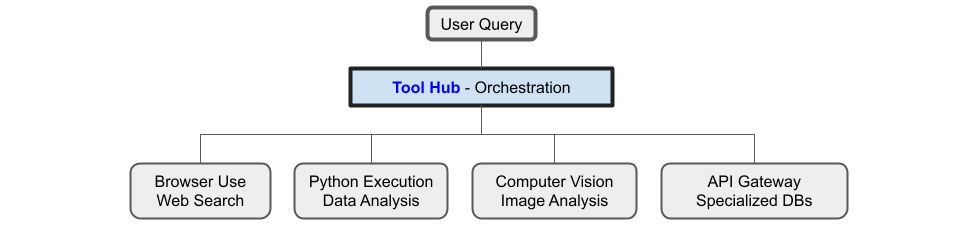
Initially, “research assistant” meant browsing text, but now we see multimodal and tool extensions. Perplexity’s inclusion of “coding” in its research loop and OpenAI’s use of Python for data analysis point to a future where a deep research agent can not only find text but also interpret data files, run statistical analysis, maybe even generate charts or maps to include in the report. In fact, OpenAI’s interface with Code Interpreter (now called GPT-4’s Advanced Data Analysis) is somewhat merged with Deep Research in the ChatGPT Pro interface, meaning the AI can do things like fetch a CSV from the web and produce insights from it. This convergence of web research and data science tools is an emerging pattern: a single agent that can both gather qualitative info and crunch quantitative data. The end goal seems to be a kind of all-purpose research agent that can handle text, data, and perhaps images (e.g., an agent could find a diagram or graph in a PDF and explain it – something we might see as multimodal models improve).
Multimodal and Cross-Domain Research

Emerging deep research tools are starting to not just read text but also possibly look at images or videos. Perplexity’s output can include related videos and even AI-generated diagrams, hinting at a multimodal experience for the user. We can expect future standards where an AI research assistant might, for example, watch a lecture video and summarize it alongside text articles on the same topic – giving a more comprehensive cross-media analysis. While current tools mostly handle text, the architecture is being laid for multimodal agents (OpenAI’s GPT-4 is multimodal by design, xAI’s Grok mentions image understanding benchmarks). So a pattern might be an agent that can say “I found a relevant chart in this PDF [shows chart] and here’s the explanation…”. This will require standard ways to represent and cite non-text content (perhaps referencing figure numbers or timestamps in videos).
Workflow Automation and Orchestration
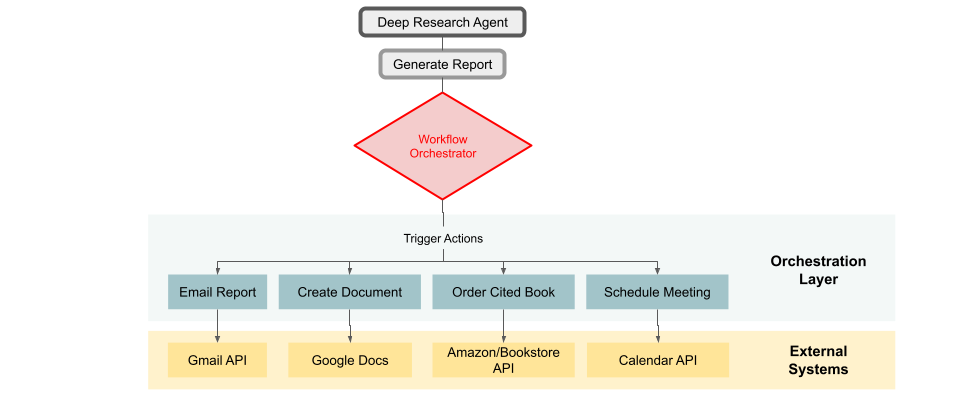
As these agents become more capable, there’s a trend toward automating entire workflows. OpenAI hinted that Deep Research is just the first step in their vision of agents that “act on your behalf to get even more done”. Future versions might not just stop at a report, but could possibly take actions like emailing that report, or ordering a book it cited, or scheduling meetings with experts – basically integrating with other services. This moves into the territory of AI personal assistants that can execute tasks. Already, we see some integration: e.g., Google allowing export to Docs (action: create a document for you). The notion of OpenAI’s “Operator” suggests a framework where agents can perform real-world operations (perhaps controlling web apps or APIs). The deep research agent could thus be part of a larger chain – find info, compile report, then perhaps draft an email to a colleague summarizing those findings or create a slide deck out of it. The standard that might emerge is a set of protocols for AI agents to hand off outputs to other systems or to chain into next steps. We’re already seeing early standards like LangChain’s agent interfaces, Microsoft’s Guidance library, or the OpenAI function calling feature that let an AI choose tools – these could evolve into formal protocols (some have talked about an “API for AI agents” or intermediaries that translate between one agent’s output and another’s input).
RLHF and Benchmark-Driven Development
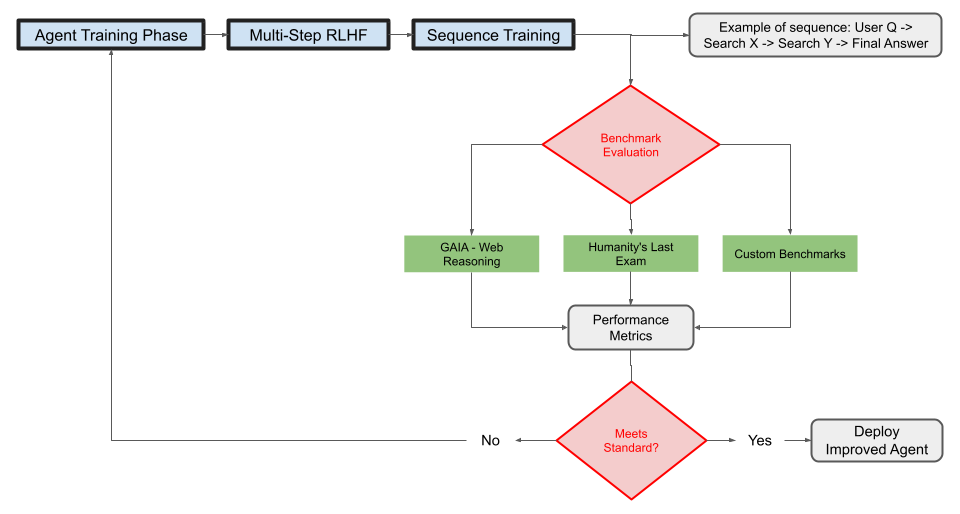
With the introduction of benchmarks like Humanity’s Last Exam (HLE) and GAIA specifically stressing multi-step reasoning, a standard is emerging to measure these agents’ performance in a more rigorous way. HLE tests “expert-level” questions and GAIA tests real-world task solving with browsing and tools. These are far more challenging than traditional QA benchmarks and are driving improvements. For instance, OpenAI boasting a record on HLE, and Perplexity quoting its HLE and SimpleQA scores in announcements shows that companies are using these benchmarks as marketing and quality metrics. We can expect that as more participants enter this space, they will all evaluate on a common set of tasks (much like GPT models compete on MMLU or other tasks today). This helps users understand strengths: one model might be state-of-the-art in answering encyclopedic questions, another in solving multi-hop puzzles. An emerging standard might also be challenge evals – e.g., “internet safety” tests to ensure an agent doesn’t stray into unsafe content while browsing. Companies will likely implement filters (OpenAI and Google certainly have safe browsing filters for their agents). Over time, community-driven evaluation might create a leaderboard for research agents, possibly hosted by academic workshops or HuggingFace, fostering transparent comparison. The use of RLHF (Reinforcement Learning from Human Feedback) or similar techniques to fine-tune these agents on multi-step tasks is likely to become a best practice. Instead of just training on single Q&A pairs, companies are training on sequences (e.g., [User question -> agent searches X -> finds Y -> agent searches Z -> ... -> answer]). This could lead to standardized training datasets or simulators for agent behavior.
User-in-the-Loop and Control
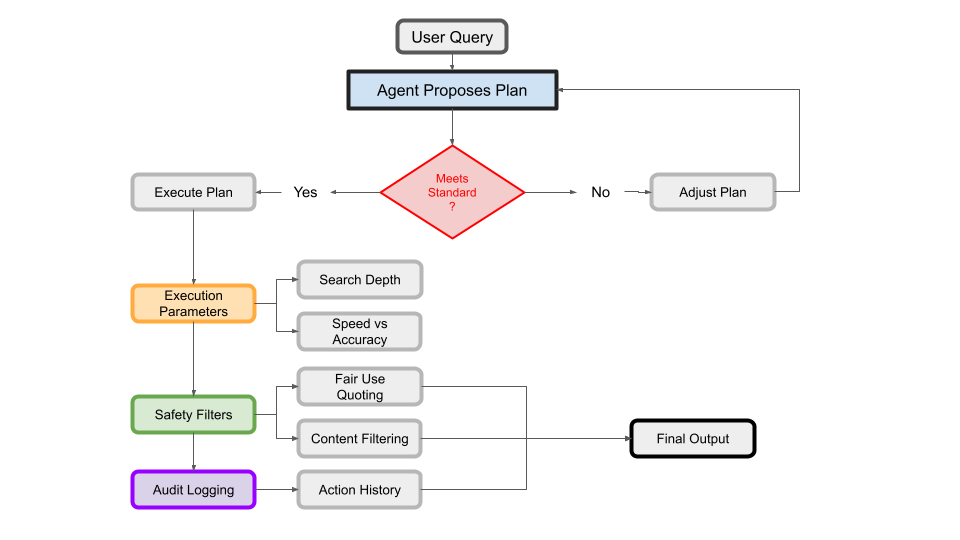
While these agents are autonomous, a pattern is emerging about keeping the user in the loop for oversight. Google requiring plan approval is one example. We might see that as a standard UX: the agent proposes “I will do A, B, C – does that look good?” to ensure alignment with user intent. This addresses one of the main concerns (agents going off track or doing unwanted actions). Another user control is the ability to set the number of steps or depth – e.g., Perplexity doesn’t expose it, but open ones let you say “do 3 iterations vs 5 iterations”. In enterprise settings, one might want to trade accuracy for speed or vice versa. Providing such knobs could become common. There’s also discussion of safety and compliance standards: since these agents browse the web, they could stumble on unsafe content or bring back copyrighted text. Companies will likely implement filters (OpenAI’s browsing already had some limitations). It’s plausible we’ll have a standard policy for AI research agents to only use publicly available data and to quote limited excerpts (to avoid copyright issues) – essentially aligning with fair use. Another emerging best practice is auditability: saving the chain-of-thought and actions for each session (a log) so that results can be audited after the fact. This is useful for debugging and for compliance in industries that need to know how an AI arrived at an answer.
Conclusion
The development of deep research tools in this short span has set new standards for AI-assisted research: it’s no longer impressive for an AI to just answer questions – it should show its work, cite sources, handle multiple modalities, possibly use external tools, and integrate into workflows. The competition and rapid open-source innovation ensure that these patterns will consolidate. We’re likely heading toward a future where an “AI research agent” is a commonplace assistant – much like web search is today – with common protocols and expectations (like always providing sources). The convergence of designs (all tools doing similar multi-step processes) and the sharing of benchmarks and open frameworks suggest that while implementations differ (proprietary vs open), the methodologies are standardizing. It’s an exciting time, as we’re essentially witnessing the birth of a new class of AI – one that doesn’t just answer, but researches. And as more users and developers adopt these tools, their feedback will further refine the emerging norms and standards governing AI-driven deep research.
Coming to this a bit late, but the DIY direction has moved a lot since this was published. The open-source options you covered have matured, and there's now another angle: assembling a pipeline from APIs buried in subscriptions you're already paying for.
Wrote it up here: https://reading.sh/how-to-build-a-solid-research-pipeline-in-claude-code-ff7878c5e2b5
Synthetic.new's standard plan includes a real-time search API that returns full page content - I only found it after digging through the docs. Combined with Firecrawl and Exa, that's a three-engine pipeline for the cost of one subscription.
Has the open-source landscape you covered here held up, or have these projects moved on significantly since you wrote this?