

Evaluating Agent Systems and Human AI Fluency (Part 1)
Benchmarking Multi-Agent Coordination, Reliability, and Interoperability

The Challenge of Evaluating Agentic AI
The emergence of AI agents – Large Language Models (LLMs) augmented with reasoning, planning, memory, and tool-use capabilities – marks a pivotal shift towards active systems increasingly deployed in complex real-world scenarios. However, alongside the excitement, high-profile failures reveal a critical challenge: evaluating these agents rigorously is genuinely hard, and current methods often fall short. This creates an urgent need to refine how we assess agent performance and reliability.
This first part of our two-part series delves into the rapidly evolving landscape of AI agent evaluation. We will survey the key benchmarks developed between 2023-2025 for both single and multi-agent systems, highlighting significant advancements in assessing planning, tool use, and interaction. Crucially, we will analyze the persistent gaps in these evaluations, particularly concerning the assessment of multi-agent coordination reliability, the integration of emerging interoperability standards like A2A and MCP, the often-overlooked dimension of cost-effectiveness, and the vital distinction between mere capability and true operational reliability. To address these shortcomings, we propose a Dual-Layer Evaluation Framework designed to provide deeper diagnostic insight into agent systems.
While rigorously evaluating the agents themselves is essential, achieving effective and safe deployment also requires understanding the capabilities and limitations of the humans who interact with them. This crucial aspect of Human AI Fluency, and its synergy with agent evaluation, will be the focus of Part 2.
The Evolving Landscape of Agent Benchmarks
The evaluation of AI agents has rapidly evolved from static LLM benchmarks measuring knowledge recall towards dynamic, interactive environments assessing planning, reasoning, tool use, and interaction capabilities. A growing suite of benchmarks aims to measure agent performance across various domains.
Single-Agent Benchmarks
Single-agent benchmarks typically evaluate the ability of an individual AI agent to perform tasks within a specific environment or across a range of domains. Recent benchmarks emphasize realism, complexity, and interaction.
OSWorld (Operating System World) – NeurIPS 2024

What it is: A fully functional Ubuntu/Windows/macOS VM suite with 369 reproducible tasks, designed to test multimodal agents on realistic open‑ended computer work (arbitrary apps, file I/O, multi‑app workflows).
Why it matters: Moves beyond app‑specific or synthetic GUI tests, letting researchers probe how well agents ground vision‑language models (VLMs) in real operating‑system interactions.
Headline results: Best current model records 12.2 % success versus 72.4 % human, exposing a large competence gap in GUI grounding and operational know‑how.
Main limitations:
Massive performance gap limits fine‑grained comparison across strong models.
Heavy reliance on long text‑based trajectory histories hampers efficiency measurement.
VLMs prove brittle to UI layout/skin variations, constraining generalization.
GAIA (General AI Assistants) – ICLR 2024

Purpose & design: 466 real‑world questions that look “easy” for people but demand reasoning, multimodal lookup, web browsing, and tool use from an agent; answers are short strings, so grading is an automated quasi‑exact match.
Philosophy: Shifts focus from superhuman feats to robustness on ordinary, human‑solvable tasks—argued as a truer path to AGI readiness.
Results to date: Humans score 92 %, while GPT‑4 + plugins (Nov 2023) manages 15 %, revealing a wide competence gap.
Strengths: No simulator needed → low evaluation cost; single‑string answers enable clean, reproducible scoring.
Limitations:
Only final answers are graded—reasoning traces go uninspected.
Vulnerable to web‑content drift and potential dataset contamination; English‑centric.
Lacks linguistic diversity and multimodal reasoning auditability.
WebArena – NeurIPS 2023

Setup & scope: Self‑hostable “mini‑web” with fully functional replicas in four domains—e‑commerce, social forums, software development, and CMS—plus auxiliary tools (map, wiki, calculator) and internal knowledge bases. It defines 812 long‑horizon tasks framed as high‑level natural‑language goals and grades agents on functional correctness rather than exact action traces.
Extensions:
VisualWebArena adds visually grounded tasks for multimodal agents.
WABER augments evaluation with reliability and efficiency metrics, addressing the original single‑metric focus.
Limitations: Early agent performance still low; evaluation confined to four site archetypes, so broader web diversity remains untested.
AgentBench – ICLR 2024

Design & scope: A multi‑dimensional benchmark that treats LLMs as autonomous agents in 8 interactive environments—Operating System, Database, Knowledge Graph, Digital Card Game, Lateral Thinking Puzzles, House‑Holding, Web Shopping, and Web Browsing.
Evaluation setup: Ships ready‑to‑run datasets, environments, and scoring code; test split entails ~13 k multi‑turn generations, with per‑environment success‑rate metrics.
Limitations: Knowledge‑Graph server can be unstable, and some tasks—especially WebShop—demand substantial compute/time.
Ecosystem:
VisualAgentBench extends the suite to vision‑language agents.
AgentTuning repurposes AgentBench tasks for instruction‑tuning LLMs.
EmbodiedBench – 2025

Setup & scope: Evaluates multimodal LLMs as vision‑driven embodied agents on 1,128 tasks in four sims—EB‑ALFRED and EB‑Habitat for high‑level semantic goals, EB‑Navigation and EB‑Manipulation for low‑level atomic actions.
Capability matrix: Scores agents on six dimensions, offering finer‑grained insight than a single accuracy metric:
basic task completion,
commonsense reasoning,
complex‑instruction understanding,
spatial awareness,
visual perception, and
long‑horizon planning
Framework: Ships a unified agent stack that fuses perception, context, history, and feedback for reproducible experiments.
Limitations: None explicitly stated in available sources; real‑world transfer and sim fidelity remain open questions.
Other Single-Agent Benchmarks: The landscape includes numerous other benchmarks targeting specific capabilities or domains. Examples include SWE-Bench for resolving real-world GitHub issues, ToolBench for tool manipulation, Mind2Web for predicting actions on static web pages, WebVoyager for live web navigation, BEARCUBS for information seeking on the live web with multimodal interactions, WebLists for structured data extraction from websites, BrowseComp for challenging web browsing information retrieval, AgentBoard for multi-turn interactions with subgoal progress tracking, τ-bench for measuring tool-use reliability, TheAgentCompany for simulating real-world professional tasks in a software company, and ResearchArena for academic survey tasks. These benchmarks collectively push towards evaluating agents on more realistic, complex, reliable, and domain-specific tasks.
Multi-Agent System (MAS) Benchmarks
Evaluating systems with multiple interacting agents introduces new challenges related to coordination, competition, communication, and emergent behavior. MAS benchmarks are emerging to address these complexities.
BattleAgentBench – 2024
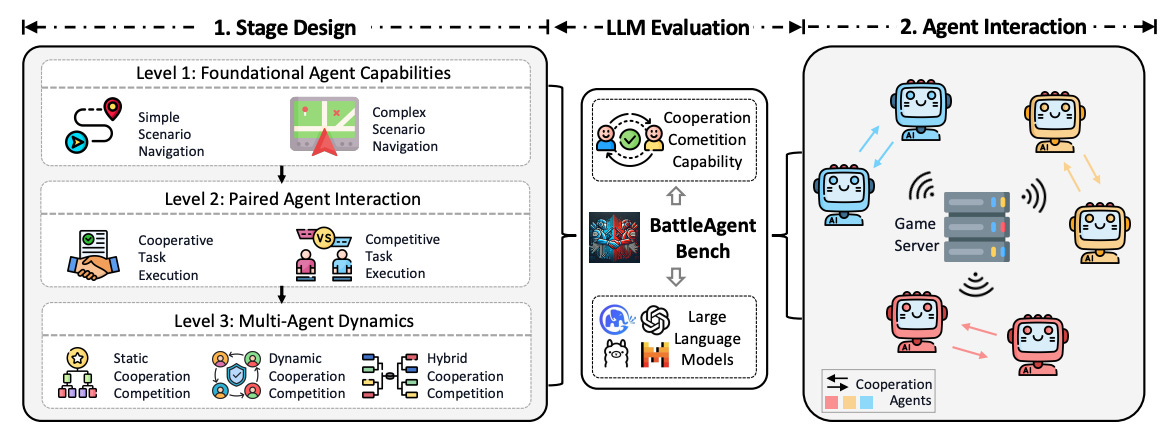
Design & scope: A modified Battle City tank game with 7 sub‑stages spread over 3 difficulty levels to disentangle single‑agent navigation, paired execution, and full multi‑agent cooperation/competition, especially where collaboration and rivalry coexist and spatial perception is vital.
Evaluation protocol: Agents’ aggregated game scores serve as the primary metric, capturing both task completion and competitive outcomes.
Strengths: Fine‑grained stage design pinpoints weaknesses in coordination vs. competition; deterministic arcade setting eases reproducibility.
Limitations: Heavily domain‑specific: insights may not transfer beyond this single game. Current scoring ignores dialogue quality and broader real‑world dynamics.
MultiAgentBench / MARBLE (2025)

Framework: MARBLE supplies both a benchmark and reusable infrastructure for testing LLM‑driven multi‑agent systems in mixed cooperative-competitive settings.
Task suite (5 scenarios):
Research co‑authoring (mutual goal)
Minecraft building (mutual)
Database error analysis (mutual)
Werewolf party game (conflicting goals)
Bargaining negotiation (conflicting)
Evaluation: Agents are scored on task completion plus milestone‑based KPIs that grade interaction quality. The framework systematically varies coordination topologies (star, chain, tree, graph) and strategies (e.g., group discussion, cognitive planning).
Limitations: complexity of setup and the interpretation of nuanced interaction metrics. Generality beyond the five crafted scenarios remains to be shown.
ZSC‑Eval (NeurIPS 2024)

Objective – Benchmark and toolkit for Zero‑Shot Coordination (ZSC): training an ego agent that must instantly collaborate with unseen partners, framed as an out‑of‑distribution generalization problem in cooperative MARL.
Three‑Stage Evaluation Pipeline
Partner Generation – Create a large pool of candidate partners via behavior‑preferring rewards that elicit diverse policies.
Partner Selection (BR‑Div) – Use Best‑Response Diversity to pick a subset that maximizes diversity of optimal responses (not just partner behaviors).
Scoring (BR‑Prox) – Compute Best‑Response Proximity, comparing the ego agent’s return against the ideal return obtainable by a best response to each selected partner.
Environments Used – Overcooked and Google Research Football, demonstrating domain‑agnostic applicability.
Advantages – Yields fairer, more informative scores than raw mean episode returns by explicitly capturing partner diversity and the ego–partner performance gap.
Limitations – Tailored to cooperative MARL; effectiveness depends on crafting suitable behavior‑preferring rewards for partner generation; competitive or mixed‑motivation settings are outside scope.
Other MAS Evaluation Approaches
REALM‑Bench (2025) – evaluates LLM/MAS planning & coordination in real‑world tasks (e.g., supply chains, disaster response); scores planning quality, adaptation, resource use, and constraint satisfaction across scalable complexity.
BenchMARL – TorchRL‑based library standardizing MARL benchmarks across environments (VMAS, MPE) with strong reproducibility guarantees.
POGEMA (2023) – cooperative multi‑agent path‑finding suite; procedurally generated maps, scalable to ≈ 1 M agents.
Emergent‑coordination analysis – causal‑inference and sub‑team‑identification techniques expose influence patterns beyond simple correlations.
LLM‑Co – tests LLM theory‑of‑mind, situated reasoning, sustained coordination, and partner robustness in Overcooked‑style games.
Social‑simulation testbeds – new platforms explore large‑scale emergent behaviors such as coordinated deception.
Trends and Observations
Rising realism and complexity
Single‑agent: interactive OS- and embodiment‑level sims (OSWorld, WebArena, EmbodiedBench) mimic everyday computer and physical tasks, pushing perception + tool‑use boundaries.
Multi‑agent: game abstractions (BattleAgentBench, ZSC‑Eval) let researchers isolate social dynamics, while richer domains (MultiAgentBench, REALM‑Bench) probe true coordination and planning.
Tension: high‑fidelity solo tests v. interaction‑heavy MAS often force trade‑offs between environment realism and experimental control.
Expansion of evaluation dimensions
Reliability & consistency (τ‑bench, WABER) track run‑to‑run stability.
Efficiency & cost (WABER, WebLists) surface latency and resource use.
Safety (SafeAgentBench) targets harmful or insecure behaviour.
Intermediate progress (AgentBoard) and capability‑specific probes (EmbodiedBench) reveal how success is achieved, not just if.
Interaction‑quality measures (MultiAgentBench, ZSC‑Eval) rate dialogue, planning, and partner adaptation.
Portfolio, not panacea
No single test covers all facets; a coordinated suite—spanning tasks, domains, and metrics—is essential for holistic insight.
Need for continual refresh
Benchmark saturation and data‑leak risk demand versioning, contamination checks, and periodic task renewal to stay predictive of real‑world performance.⁴
Analysis of Gaps in Current Agent Benchmarking
Multi‑Agent Coordination Remains Under‑Evaluated
Most legacy suites (GAIA, WebArena, OSWorld, AgentBench) were designed for single‑agent runs; they miss the dynamics of agents collaborating, competing, or dividing labour.
Early fixes—BattleAgentBench, MultiAgentBench, ZSC‑Eval—introduce milestone KPIs, communication‑topology experiments and BR‑Prox metrics, yet still cover only small teams, short horizons, and limited use cases.
There is a shortage of benchmarks evaluating reliable communication, action alignment, and knowledge sharing in team settings. Metrics for collaboration quality and efficiency are only beginning to emerge.
Open research challenges
Quantifying coordination quality: efficiency of dialogue, conflict resolution, dynamic role allocation, synergy.
Competition & mixed motives: testing negotiation, betrayal‑proof strategies, adaptive behaviour when goals partially diverge.
Emergent phenomena: detecting beneficial swarm abilities vs. harmful collective behaviours (e.g., coordinated deception).
Scalability: tooling that analyses hundreds‑to‑thousands of agents without prohibitive compute or manual annotation.
Interoperability Gap: No Benchmarks for Standard Protocols (A2A, MCP)
Real deployments require agents to discover, negotiate, and collaborate through shared interfaces; industry is converging on:
Agent‑to‑Agent (A2A): horizontal messaging, task hand‑off, secure opaque execution.
Model Context Protocol (MCP): vertical access to tools, data, and context.
Current academic benchmarks embed bespoke APIs; none score agents on protocol compliance or cross‑vendor plug‑and‑play. This overlooks evaluating how reliably agents interact within standardized ecosystems.
Needed evaluation dimensions
Dynamic capability discovery & handshake.
Standardised task lifecycle management across heterogeneous agents.
Collaboration quality when messages follow protocol specs.
Generalisation from benchmark‑specific wrappers to protocol‑based ones.
Robustness, Safety & Ethics Insufficiently Tested
Benchmarks usually assume clean inputs and stable environments; few probe resilience against network errors, UI/layout drift, or noisy data.
Safety suites (e.g., SafeAgentBench) are narrow; broader checks for harmful tool usage, privacy violations, or bias amplification during autonomous actions are sparse.
Desired additions
Stress tests for transient failures and adversarial perturbations.
Metrics for ethical alignment, refusal correctness, accountability logging.
Efficiency & Cost Still Second‑Class Metrics
Academic tasks reward capability, not practicality; compute time, token usage and monetary/API cost are rarely reported.
Benchmarks such as WABER and WebLists hint at cost‑aware scoring, but there is no standard efficiency leaderboard.
Future suites should expose budget‑constrained tracks and energy/latency charts.
Long‑Horizon Planning & Error Recovery Weak Points
Agents falter on extended, multi‑step workflows that need memory, re‑planning and mistake correction (identified in GAIA, WebArena, EmbodiedBench).
Alternative metrics—e.g., task‑completion time horizon or recovery rate—have been proposed but not widely adopted.
Over‑Simplified or Closed Environments
Many benchmarks operate in simulated or narrow settings, failing to capture the challenges of agents acting within dynamic environments.
Simulated websites, synthetic OS abstractions, and narrow game-like tasks omit the unpredictability of the real web, live APIs, or full desktops.
Static input/output tests are insufficient.
OSWorld’s real computer setting is a rare exception; open‑world, tool‑rich, and continuously evolving arenas remain largely unexplored.
Gaps include handling unexpected events, long‑running sessions, and self‑directed goal generation.
Furthermore, benchmarks often lack mechanisms for incorporating human domain expert judgment or dynamically adapting evaluation criteria, limiting their real-world relevance.
Lack of Integrated Multi‑Modal & Tool‑Use Evaluation
Benchmarks tend to silo tasks (text‑only, vision‑only, code‑only), making it hard to evaluate reliable performance on complex challenges requiring blended capabilities.
Real workflows demand agents that weave together perception, language, reasoning, code writing and tool invocation in one continuous episode.
No benchmark yet forces an agent to, for instance, interpret an image, plan actions, write code, and execute it on a real system end‑to‑end.
Conflating Capability with Reliability
Most benchmarks measure capability: what an agent can achieve, perhaps infrequently (high pass@k).
However, real-world applications demand reliability: consistent, correct performance (high pass^k).
Over-reliance on capability metrics (like high SWE-Bench scores driving investment despite poor real-world task reliability) is misleading and risky. We lack standardized methods to rigorously assess agent consistency and dependability.
Summary: Priority Directions for Next‑Gen Benchmarks
Protocol‑aware interoperability tests that score A2A/MCP compliance.
Large‑scale multi‑agent arenas measuring coordination efficiency, emergent risks, and scalability.
Robustness‑, safety‑, and cost‑centric tracks that run stress scenarios and budget limits.
Open‑world, multi‑modal tasks combining real web, OS, APIs, and diverse data types in long‑horizon missions.
Proposed Dual-Layer Evaluation of Agent Systems
To address the identified gaps in current benchmarks – particularly concerning multi-agent coordination, standardized protocols, integrated skills, cost, and the critical need to assess reliability – we propose a dual-layer evaluation framework for new benchmarks. This design assesses systems on two levels: (A) individual specialist agent capabilities and (B) coordinated multi-agent system performance. This separation allows for measuring both micro-level competence and macro-level emergent behaviors, providing deeper diagnostic insights than single-score evaluations.
Layer A: Individual Specialist Evaluation
This layer evaluates the core competence of individual agent types (e.g., coding, data analysis, web search) in isolation, akin to unit testing for component capability and reliability.
Methodology: Agents face tasks specific to their designated role, abstracting away complex coordination. Benchmark tasks would test core functions (e.g., code generation correctness, information retrieval accuracy).
Key Metrics:
Task Accuracy/Correctness & Consistency: Success rate over multiple trials and quality of output for the agent's specialized function.
Efficiency: Resource usage (latency, API calls, steps) and associated operational cost for completing its sub-task.
Robustness: Performance on edge cases or with perturbed inputs.
Protocol Interaction (Agent-to-Tool/Context): Assess the agent's ability to reliably and correctly interact with tools or external context provided via protocols like MCP. This involves evaluating if the agent (acting as an MCP client) can correctly handle the protocol's message exchange (e.g., requests, results, errors) to utilize resources provided by an MCP server.
Layer B: Coordination System Evaluation
This layer assesses the effectiveness of the entire multi-agent system (including any orchestrator) on complex tasks requiring collaboration, assessing the reliability and efficiency of the coordinated system.
Methodology: The system tackles benchmark scenarios demanding division of labor and inter-agent interaction. Evaluation focuses on the process and outcome of the collaboration.
Key Metrics:
Task Routing & Capability Discovery: How effectively does the system assign sub-tasks to appropriate agents? This involves assessing the use of discovery mechanisms, like an A2A Client reviewing Agent Cards to select the right A2A Server (specialist agent) for a job.
Workflow Efficiency & Parallelism: Measures overall task completion time, degree of parallelism achieved, and total system cost (sum of component costs + overhead) relative to optimal schedules, penalizing poor task decomposition or unnecessary sequential processing.
Communication Effectiveness (Inter-Agent): Evaluates the reliability and efficiency of communication between agents, using protocols like A2A. Metrics could include message overhead (count, tokens), clarity (e.g., minimizing clarification loops), and successful management of the A2A Task lifecycle (initiation, updates via Messages/Parts, completion states). Correct and efficient protocol usage would be positively evaluated.
Global Task Success, Quality & Consistency: Measures the overall success rate (over multiple runs) and quality of the final outcome achieved by the collaborating agents, potentially using milestone tracking for credit assignment.
System Resilience & Error Recovery: Assesses the system's ability to reliably detect and recover from individual agent failures (e.g., faulty output, unresponsiveness) during collaborative tasks.
Scoring Rubric
A composite score combining Layer A (Specialist Competency) and Layer B (Team Coordination) results is recommended, possibly using a weighted structure (e.g., 50/50). The breakdown should be transparent, allowing evaluators to pinpoint specific weaknesses in individual agents or the coordination logic.
Benefits of this Design
This dual-layer approach provides granular diagnostics for reliability engineering, distinguishing between failures in individual agent skills/consistency versus failures in system coordination or protocol handling. It encourages evaluating agents not just on what they do but also on cost-effectiveness, dependability, and how they interact within a potential ecosystem, promoting the development of robust, interoperable systems ready for standardized protocols like A2A and MCP. This structured evaluation is crucial for guiding improvements at both the component and system levels in complex AI deployments.
Recommendations and Research Agenda
Building on the analysis of the current agent benchmarking landscape and its gaps, the following recommendations focus on advancing the state-of-the-art in evaluating AI agents themselves:
Evolve Benchmarks Towards Integrated, Realistic, and Robust Evaluation
Enhance Realism and Open-Endedness: Move beyond narrow tasks to evaluate agents in realistic, open-world, longitudinal scenarios blending modalities and requiring sustained reasoning (e.g., simulating complex workflows, using real software). Evaluate persistence, prioritization, and context handling. Implement strategies to combat benchmark saturation.
Prioritize Robustness, Reliability, and Safety: Shift evaluation focus from average performance to consistency (pass@k), reliability under realistic noise/perturbations, and graceful failure/recovery. Integrate metrics for safety, fairness, bias, transparency, and explainability. Incorporate human domain expert validation loops where feasible.
Standardize and Deepen Multi-Agent System (MAS) Evaluation
Focus on Coordination, Competition, and Emergence: Develop richer metrics for coordination quality (communication efficiency, negotiation, role adaptation, conflict resolution), standardize evaluation of competitive/mixed-motive scenarios, and create methods to assess emergent behaviors (beneficial and harmful).
Address Scalability: Design evaluation frameworks capable of assessing MAS with large numbers of agents.
Integrate MAS Components: Encourage adding collaborative components (e.g., pair programming) even to traditionally single-agent benchmarks.
Encourage and Evaluate Use of Interoperability Protocols (A2A, MCP)
Incorporate Protocol-Relevant Scenarios: Design benchmark tasks where using standards like A2A (for agent communication, discovery via Agent Cards, task management) and MCP (for tool/context interaction) is advantageous and assessable.
Develop Specific Metrics: Create metrics measuring quality of protocol usage, including adherence to specifications, efficiency (overhead, latency), and robustness to errors.
Incentivize Interoperable Design: Structure scoring to positively evaluate effective use of standard protocols, promoting ecosystem readiness.
Adopt the Dual-Layer Evaluation Framework
Design new multi-agent benchmarks to explicitly support dual-layer evaluation:
Layer 1: Specialist Capabilities/Reliability/Cost
Layer 2: System Coordination/Reliability/Cost.Promote this diagnostic approach for its ability to pinpoint reliability failures and bottlenecks at component vs. system levels, encouraging modular design.
Prioritize Multi-Dimensional Evaluation including Cost
Inclusion of cost (monetary, compute, tokens) alongside performance and reliability metrics in agent benchmarks.
Reporting and analysis using cost-performance Pareto frontiers to enable informed engineering trade-offs.
Foster Transparency and Standardization in Benchmarking
Promote accessible dissemination of benchmark results, including common failure modes related to reliability and cost.
Encourage open standards for protocols (A2A, MCP) and open-source evaluation frameworks/suites to enhance reproducibility and comparability. Facilitate open access to benchmark data and code.
Towards More Reliable Agent Evaluation
The journey towards truly capable and deployable AI agents necessitates a significant evolution in our evaluation methodologies. While current benchmarks provide valuable insights and drive progress, this review has highlighted critical shortcomings. The field struggles with reliably assessing multi-agent coordination, incorporating vital interoperability standards like A2A and MCP, treating cost as a first-class evaluation metric, and, perhaps most importantly, distinguishing between an agent's occasional capability and the consistent reliability demanded by real-world applications. The over-reliance on static benchmarks that fail to capture these nuances can lead to misleading assessments and brittle systems.
The proposed Dual-Layer Evaluation Framework offers a structured approach to gain deeper diagnostic insights, separating individual component reliability and cost from system-level coordination effectiveness and efficiency. By incorporating protocol adherence, cost-awareness, and reliability metrics directly into this framework, we can create benchmarks that better reflect the challenges of engineering dependable agentic systems.
However, evaluating the agent system in isolation provides only half the picture. The ultimate success of these agents hinges on their interaction with humans. Understanding how to measure and cultivate human AI fluency, and recognizing the profound parallels between human competencies and desired agent capabilities, is essential for designing systems that are not just technically proficient but also safe, effective, and trustworthy when deployed alongside people. Part 2 of this series delves into this crucial human dimension, exploring frameworks for AI fluency and outlining a path towards a truly unified evaluation of the human-AI partnership.
References and Further Reading
Anthropic. “Model Context Protocol.” Anthropic, 25 Nov. 2024.
Gonzalez, Leonardo. “Google’s A2A Protocol.” Trilogy AI Center of Excellence, 10 Apr. 2025
Google. “Announcing the Agent2Agent Protocol (A2A).” Google Developers Blog, 9 Apr. 2025.
Kapoor, Sayash. "Building and evaluating agents that matter." AI Engineer Summit. 21 Feb. 2025
Liu, Xiao, et al. “AgentBench: Evaluating LLMs as Agents.” arXiv, 7 Aug. 2023 (rev. 25 Oct. 2023). arXiv:2308.03688 [cs.AI]. (ICLR 2024 Poster)
Long, Qian, et al. “TeamCraft: A Benchmark for Embodied Multi-Agent Systems in Minecraft.” Withdrawn ICLR 2025 Submission (Sept. 2024). OpenReview, forum id: nE3flbe88p.
Wang, Wei, et al. “BattleAgentBench: A Benchmark for Evaluating Cooperation and Competition Capabilities of Language Models in Multi-Agent Systems.” arXiv, 28 Aug. 2024. arXiv:2408.15971 [cs.CL].
Xie, Tianbao, et al. “OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments.” arXiv, 11 Apr. 2024 (rev. 30 May 2024). arXiv:2404.07972 [cs.AI].
Yang, Rui, et al. “EmbodiedBench: Comprehensive Benchmarking Multi-Modal Large Language Models for Vision-Driven Embodied Agents.” arXiv, 19 Feb. 2025. arXiv:2502.09560 [cs.AI].
Zhou, Shuyan, et al. “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv, 25 Jul. 2023 (rev. 16 Apr. 2024). arXiv:2307.13854 [cs.AI].
Zhu, Kunlun, et al. “MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents.” arXiv, 3 Mar. 2025. arXiv:2503.01935 [cs.MA].