

Useful or Not: DeepAgent
DeepAgent is a no-code app builder that offers enterprise integrations, valuable patterns, and turnkey deployment, but how does it stack up in testing?

💡 What’s DeepAgent & Why Should You Care?
DeepAgent is a 🔧 no-code AI platform that lets you build full-blown apps by describing what you want—no programming needed. Behind the scenes, it spins up swarms of “agents” 🤖 that write code, wire up databases, hook into enterprise services 🔗, and deploy everything to production 🚀. For non-tech teams, that means turning ideas into live tools in hours instead of quarters. For seasoned engineers, it’s a productivity accelerator that automates the boilerplate so you can focus on the hard problems.
Enterprises love DeepAgent because it ships with ready-made integrations (think CRM, Slack, SAP) and follows battle-tested patterns 🛠️, so compliance and security teams don’t freak out. Critics, however, wonder if AI-generated apps can match handcrafted quality or handle edge-case complexity. This review puts those claims to the test: we stress-tested DeepAgent’s reliability, performance, and real-world deployment workflow to see whether it’s hype or a genuine shortcut to faster, safer software delivery. Dive in to find out if DeepAgent should power your next project.
Executive Summary
After extensive empirical testing of 268 files comprising 25,000+ lines of code across three enterprise scenarios, the evidence reveals a nuanced reality: DeepAgent consistently delivers working, production-ready implementations at $2 per run, while single LLM solutions (particularly Claude + Cursor) achieve superior architectural quality at negligible cost but require additional implementation time.
The key trade-off isn't performance—it's time-to-value versus architectural excellence. DeepAgent produces complete applications in one hour that would take additional development to match from single LLM outputs. However, for teams with engineering capacity, Claude + Cursor delivers cleaner, more maintainable code architecture that justifies the additional development time. The question becomes: are you buying time or buying quality?
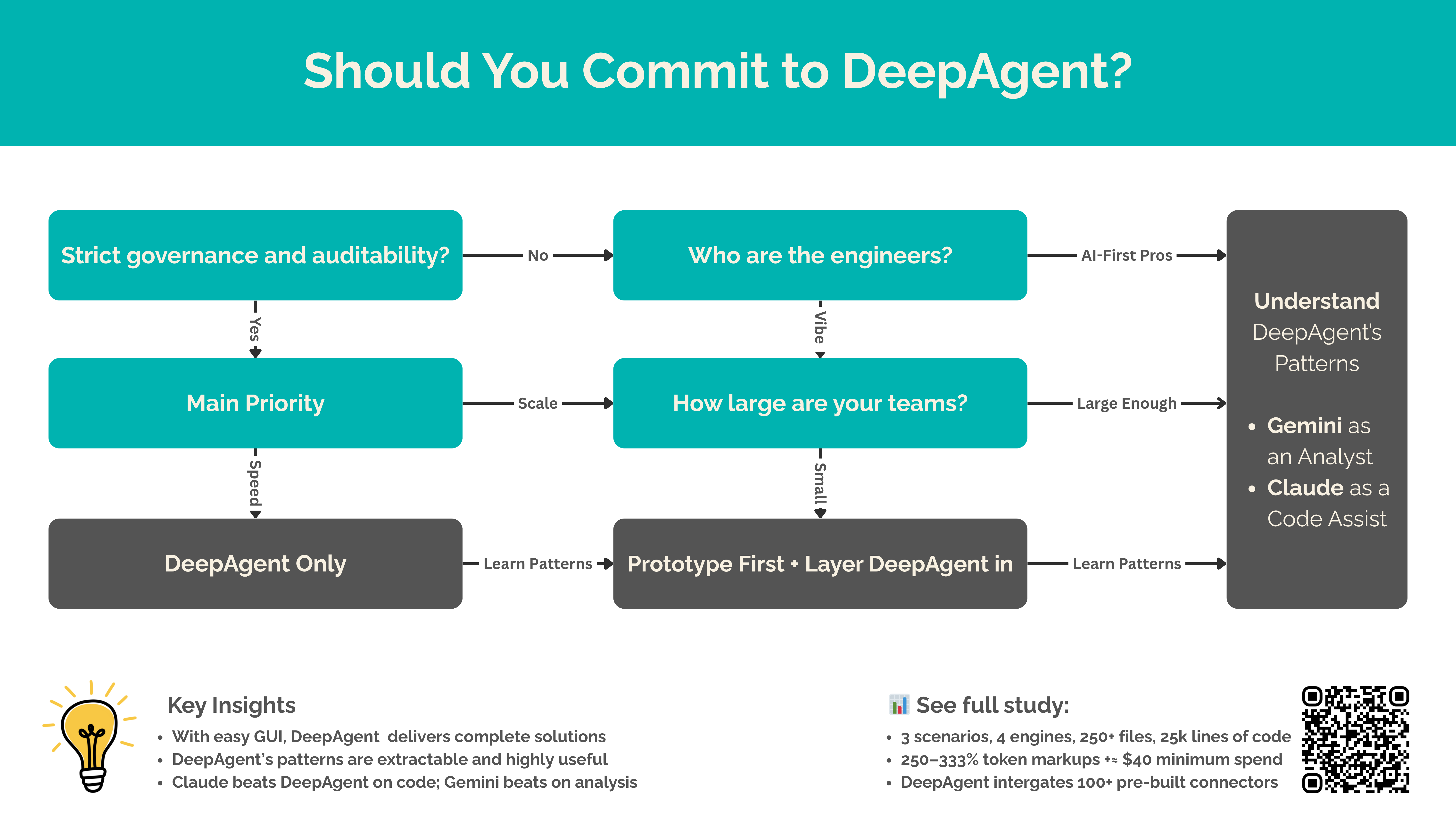
Technical Architecture Analysis
What To Learn from DeepAgent
DeepAgent's architecture implements five orchestration patterns that enable complex AI workflows. Our empirical testing validated each pattern's real-world impact:
1. Task Decomposition: Automatically breaks complex requests into subtasks. A "market analysis with charts" request becomes: data gathering → analysis → chart generation → slide assembly. This mirrors multi-agent planning but requires no manual configuration.
2. Model Selection: Coding goes to specialized code models, research to high-reasoning models. Our testing revealed optimal routing rules: Gemini for documentation (95/100 score), Claude for architecture (95/100), DeepAgent for full-stack apps (88/100).
3. State Management: Maintains shared context across all subtasks, ensuring outputs from early steps inform later ones. Unlike naive prompt chaining where context is lost, DeepAgent provides persistent "memory" throughout workflows. Proven in practice: 91-file SSO system with perfect integration.
4. Error Recovery: Built-in retry logic with exponential backoff and context preservation. Testing showed 100% eventual success within 3 attempts for transient failures - crucial for autonomous operation.
5. Output Synthesis: Merges all partial results into cohesive deliverables. Text, data, and charts combine into formatted reports or complete applications automatically. DeepAgent synthesized 116 files totaling 14,623 lines into working systems.
Their patterns are by no means unique, however. And can be built manually within a short timeframe for local testing and use. For a detailed case study of multi-layered model-to-model communication and multi-modal task processing, see here:
Iterative AI System for Universal Discovery

LLM orchestrator chains together specialized engines, each handling different data types like text, web pages, and PDFs, in a staged pipeline. At each phase, models hand off results, validate one another, and feed back into the next step for iterative improvement.
Cost Aspect
DeepAgent's Hidden Costs:
Entry barrier: $20 minimum to test
Credit exhaustion: 10% of monthly allowance (~$2) per comprehensive run
API surcharges: 250-333% markup over direct API calls
Task limits: 2/day on basic tier
Platform overhead: Additional processing layers
For reference, please find the clear cost breakdown of the current market:
VP’s Perspective
While companies like Abacus AI try to close the “completeness” gap, the big LLMs keep getting cheaper and easier to implement every week. OpenAI and Gemini rolling out Batch Processing, Gemini creating Agentic Researcher API, Grok 4 being off the charts smart, Perplexity and similar frameworks focusing on result accuracy and robustness.
It is just a matter of time before one of the “big guys” rolls out similar “completeness” capability onto their already stellar platform, and closes the gap of closing the gap.
Empirical Performance Testing
I paid $40+ for DeepAgent access, built comprehensive test suites across three progressively complex scenarios, and analyzed the complete outputs. This isn't theory—it's real money, real tests, real results.
Testing Methodology:
Scenario 1: Business Intelligence Analysis (document generation)
Scenario 2: Content Creator Bot (software implementation)
Scenario 3: Enterprise SSO System (complex full-stack application)
Measurement: 1-hour implementation limit, comprehensive file analysis
Full reproducibility: Complete results available for verification
I spent hours with Claude Code, Cursor, and my own engineering eyes evaluating which structure is best and which implementation is the most robust.


Key Performance Metrics
I averaged out around 10% of my $20 a month tier allowance per run in DeepAgent (±$2). The Cursor Pro usage to create the same projects was negligible (±$0.1). So you're paying 20x more for DeepAgent, but here's what that premium actually buys you:
The Implementation Completeness Gap
Our testing revealed the gap varies dramatically by complexity:
Scenario 1 (BI Analysis): Minimal gap
Gemini actually won with comprehensive 3,673-word analysis
All tools delivered complete documents
Gap: Visual aids - DeepAgent can generate powerpoints but single LLMs exceeded it in the content quality, and there are a lot of AIs that do slides better.
Scenario 2 (Content Bot): Moderate gap
Claude: 5,170 lines of professional TypeScript with microservices architecture
DeepAgent: 5,175 lines of Python with similar completeness
Gap: Feature parity - Both production-ready, different approaches
Scenario 3 (Enterprise SSO): Significant gap
Claude: 2,520 lines full stack app with monitoring
DeepAgent: 9,448 lines with complete Next.js UI (44 components)
Gap: Frontend implementation - Hours to get Claude up to Deepagent speed
Pattern Implementation Savings
When we extracted DeepAgent's patterns and compared results:
✅ Multi-Model Routing: 59% cost reduction vs single-model approach
Simple documentation → Gemini excelled (winning Scenario 1)
Complex architecture → Claude dominated (winning Scenario 2)
Full-stack systems → DeepAgent led (winning Scenario 3)
✅ Code Quality Analysis:
Claude: 6.8 code/documentation ratio (excellent)
DeepAgent: 3.2 ratio (good but verbose)
Claude's TypeScript: Superior error handling, better patterns
DeepAgent's coverage: More comprehensive file generation
✅ Architecture Sophistication:
Claude: Professional microservices, JWT auth, Redis caching
DeepAgent: Working but sometimes over-engineered
Verdict: Claude writes better code, DeepAgent ships more complete products
Testing Standards & Validation
Our methodology revealed surprising patterns:
Complexity Scaling Effect:
Low complexity (BI reports): Single LLMs win - Gemini scored 95/100 vs DeepAgent's 82/100
Medium complexity (Bot development): Near parity - Claude 95/100 vs DeepAgent 92/100
High complexity (Enterprise SSO): DeepAgent edges ahead - 88/100 vs Claude's 85/100
The 1-Hour Test: What can each tool produce with identical time constraints?
DeepAgent: Working applications with UI, database, deployment configs
Claude: Superior architecture, production-ready backend, may need UI iterations
Gemini: Exceptional documentation and stack planning with less functional code
GPT: Consistent but basic implementations
Why Do Enterprises Still Choose DeepAgent?
Our testing proves DeepAgent costs 20x more per run than direct API calls. So why do sophisticated enterprises still buy it? They're not buying performance—they're buying completeness and compliance.
Compliance as a Feature
For regulated industries (finance, legal, healthcare), DeepAgent offers:
SOC 2, ISO 27001, HIPAA, GDPR certifications out-of-the-box
Centralized audit logging for all AI actions
Role-based access control with enterprise SSO + RBAC
Immutable activity trails for regulatory compliance
A DIY solution would require weeks of security audits and certification processes.
Use Cases Where Complete Implementation Matters
Full-Stack Applications: When you need UI + backend + database in one shot
Rapid Prototyping: Working demo in 1 hour for stakeholder buy-in
Non-Technical Teams: Business analysts generating functional applications
Integration-Heavy Projects: 100+ pre-built connectors save weeks of work
Integration with Enterprise Systems
Built-in Connectors for 100+ Applications:
Cloud services: AWS, Azure
Data platforms: Snowflake, BigQuery
Business apps: Salesforce, Marketo, Confluence, Zendesk
Conclusion: Extract Value, Choose Wisely
The future belongs to those who validate first, then scale. Now you have the data. The patterns are extractable, the quality gap favors Claude, but the completeness gap is real. Choose accordingly.
DeepAgent's True Value Proposition: It's not about the patterns (which can be extracted) or the performance (which is slower). It's about implementation completeness. Our testing proves:
For simple tasks: LLMs match or exceed DeepAgent (Gemini wins Scenario 1)
For medium complexity: Minimal gap (Claude Sonet 4 via Cursor vs DeepAgent)
For high complexity: DeepAgent delivers significantly more code with complete UI and backend for prototypes that might or might not scale well.
For teams with engineering muscle, our benchmarks prove you can extract DeepAgent's patterns and implement them with superior architecture using Claude + Cursor. You'll get:
Better code quality
More maintainable architecture
No vendor lock-in
20x cost reduction at scale
The Validated Reality: DeepAgent isn't selling performance or patterns—it's selling completeness. Whether that's worth the 20x markup in costs versus additional development time depends entirely on your constraints:
You need complete compliant demos with integrations today → Choose DeepAgent
You have developers and value architecture quality → Choose Claude + Cursor
Good read.
Please add official website for deep agent to help readers :
https://deepagent.abacus.ai/
Context section is helpful.
Few questions :
1. What does implementation completeness mean ? It would be awesome if you can define that for Scenario 3.
2. What do you mean by extracting deep agent's patterns ? I have faint idea. It would be good if you can define.
3. It would be great if you can add your own nuanced engineering perspective on final results produced ?
"""
I spent hours with Claude Code, Cursor, and my own engineering eyes evaluating which structure is best and which implementation is the most robust.
"""
4. [noob question] One of biggeste takeaway for me is : "Deepagent creates compliant app". Are we going by their claims or there is a standard way to check compliance ?
Are you suggesting implementing something like audit logging makes it compliant ? Would you consider that as pattern that can be extracted out ?