

Building the AI COE Chatbot
Willfully over-engineering a simple RAG bot to explore agentic workflows

The Simple Goal and the Ambitious Detour
The Problem: The Trilogy AI Center of Excellence (COE) needed a central knowledge source. Engineers constantly ask about our preferred tools, coding standards, deployment patterns, and past project learnings.
The Obvious Solution: A simple Retrieval-Augmented Generation (RAG) chatbot pulling from our Substack knowledge base.
It took me a few hours to whip up a simple RAG setup over our COE knowledge base, using the best practices synthesized from previous research, but that felt like I’d just assembled modular Swedish furniture: technically functional, but viscerally unsatisfying.
The real question wasn't if we could solve it, but how far should we push the solution to understand the practical limits and real-world trade-offs of agentic workflows?
This led me down a rabbit hole of experimentation, from naive agents out of the langgraph toolkit to more tightly controlled manual pipelines to more sophisticated self-reflection loops. Here's the journey.
Video - Why this chatbot?
Setup 1: The Naive Approach - A Single LLM with Tools
Every journey starts somewhere, and in AI development, that "somewhere" is usually the simplest thing that could possibly work. In this case, it’s a standard ReAct (Reason+Act) agent. You give an LLM a prompt, a box of tools, and let it figure out the rest.
Approach
The idea is to empower a single LLM to act as a reasoning engine. It receives the user's query, "thinks" about which tool (if any) could help answer it, executes that tool, observes the result, and repeats this loop until it has enough information to generate a final response. It's simple, elegant, and often, the first thing people try.
Architecture
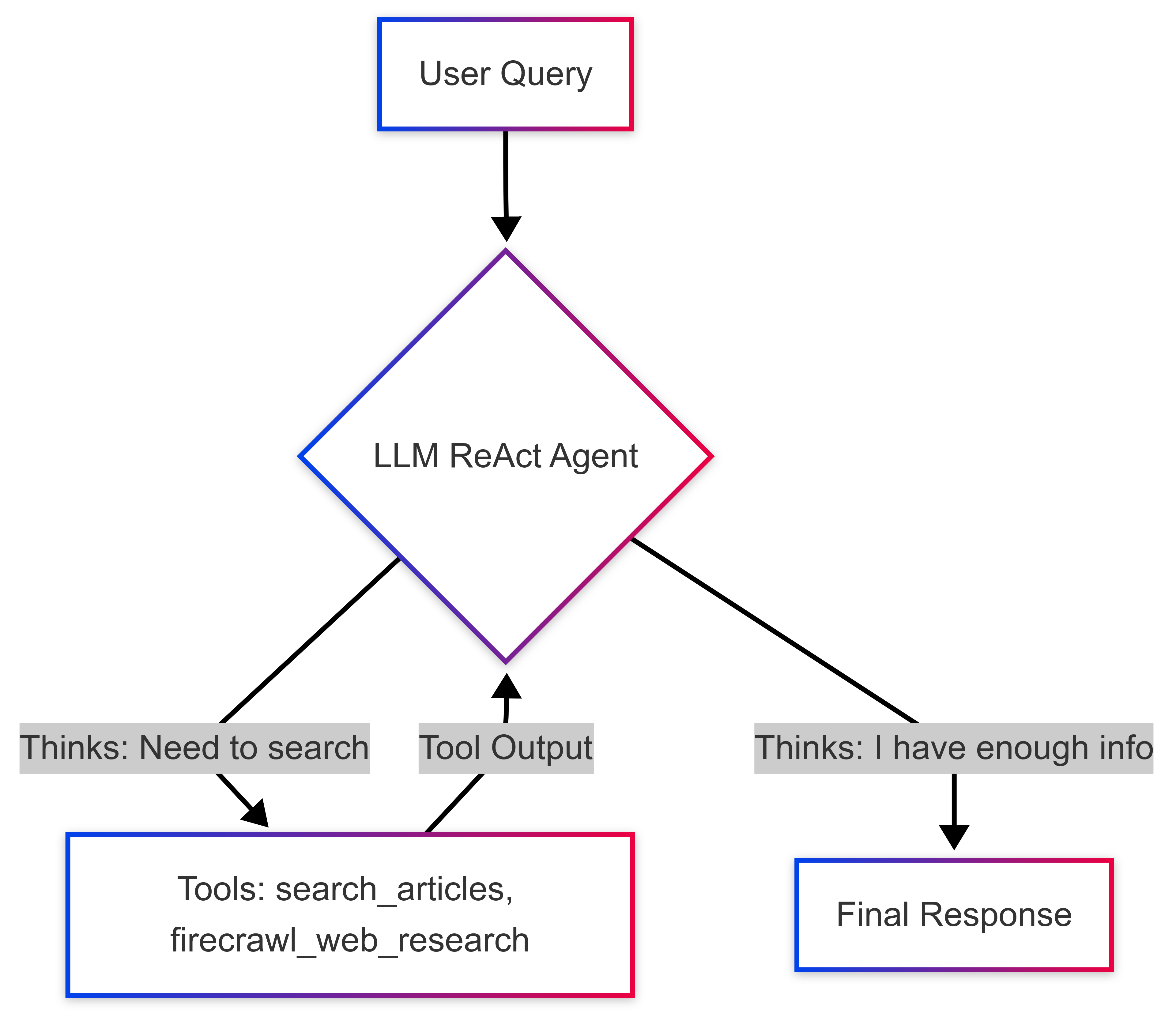
Single ReAct Agent: One LLM, configured with
langgraph.prebuilt.create_react_agent, is responsible for the entire workflow: understanding the query, planning steps, executing tools, and synthesizing the final answer.Monolithic Prompt: The agent's entire "brain" is a single prompt that describes its persona, lists the available tools, and instructs it on how to reason.
Tool Set: The agent has direct access to all available tools (
search_articles,firecrawl_web_research_tool) and must decide which one to use based on the query.
Pseudocode
// 1. Define the agent's components
DEFINE agent_prompt WITH persona_and_tool_instructions
DEFINE tool_set = [search_articles_tool, web_research_tool]
// 2. Create the agent with a single function call
agent = create_react_agent(
model = LLM,
tools = tool_set,
prompt = agent_prompt
)
// 3. Execute by invoking the compiled agent graph
result = agent.invoke({"query": user_query})Pros ✅
Speed of Implementation: This is the fastest architecture to get up and running. A few lines of code and you have a functioning agent.
Theoretical Flexibility: Because the LLM is in full control, it has the potential to chain tools or use them in novel combinations you didn't explicitly program.
Cons ❌
Unpredictability: This is its fatal flaw. The agent is a black box. It might decide not to use a tool when it's clearly needed, giving a lazy answer from its parametric memory. For example, to "What's the latest on DSPy?", it might ramble about 2023-era knowledge instead of using the web search tool.
Lack of Control: You have almost no direct control over the execution flow. The agent can get stuck in loops, call tools with the wrong arguments, or simply give up.
Brittle Prompting: The entire system's reliability hinges on one monolithic prompt. A small, innocent-sounding change to the prompt can have drastic, unforeseen consequences on its behavior.
Analysis
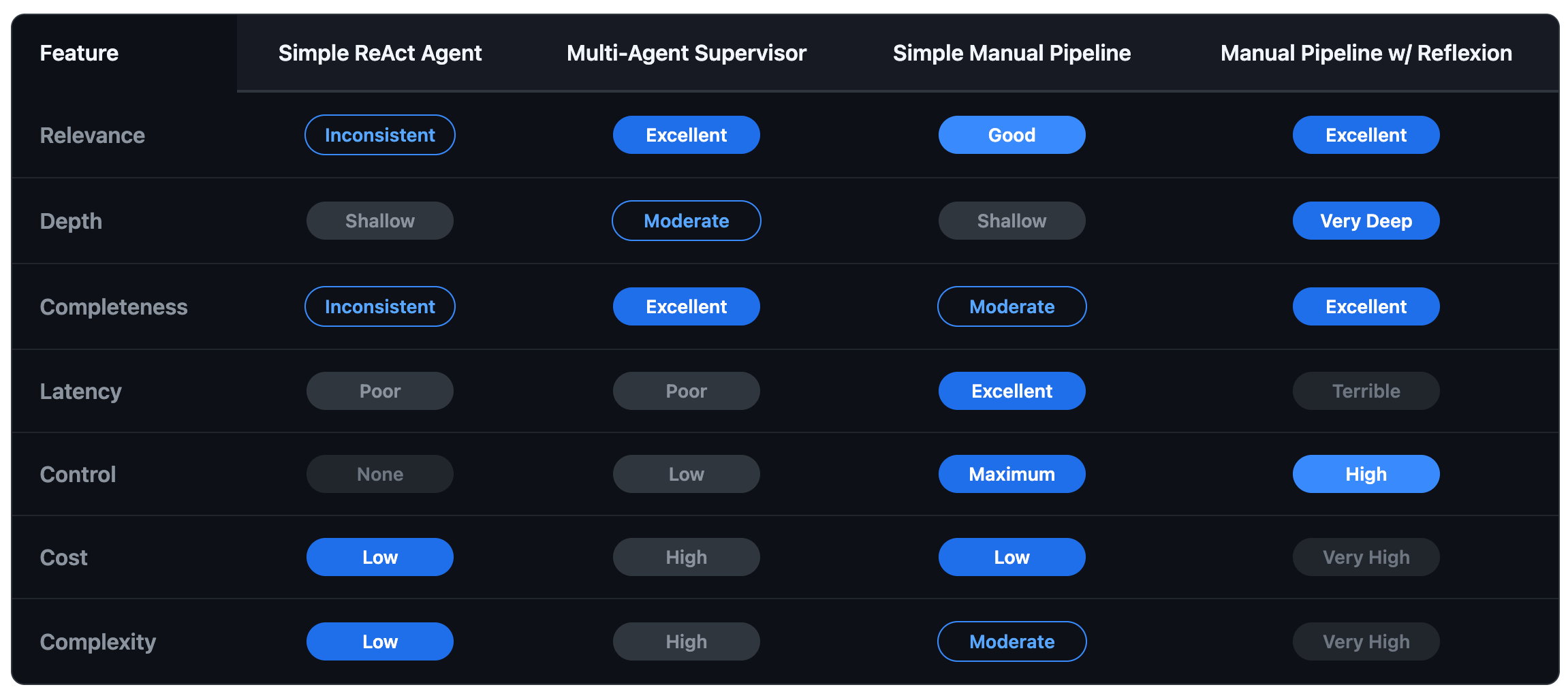
Relevance & Completeness: Wildly inconsistent. Sometimes it nails the query; other times it completely misses the point by failing to use a tool.
Depth of Response: Almost always shallow. ReAct agents are typically optimized to find an answer and stop, not to synthesize deeply.
Latency: Can be surprisingly high. The "thinking" step can be slow, and the agent might make several unnecessary tool calls, adding significant delays.
Video: Simple RAG
Setup 2: The Supervisor Model - Team of Agents
The single ReAct agent was too chaotic. The first attempt to tame this chaos was not to reduce its autonomy, but to structure it. The idea was to break down the monolithic agent into a team of specialized agents managed by a supervisor, hoping that smaller, more focused agents would be more reliable.
Approach
This setup uses langgraph_supervisor to orchestrate a team. The Supervisor acts as a project manager. It receives the user's query and decides which worker agent is best suited for the job. The workers are standard ReAct agents, each with their own prompt and tools. This introduces a layer of autonomous delegation that was missing from the single-agent setup.
Architecture
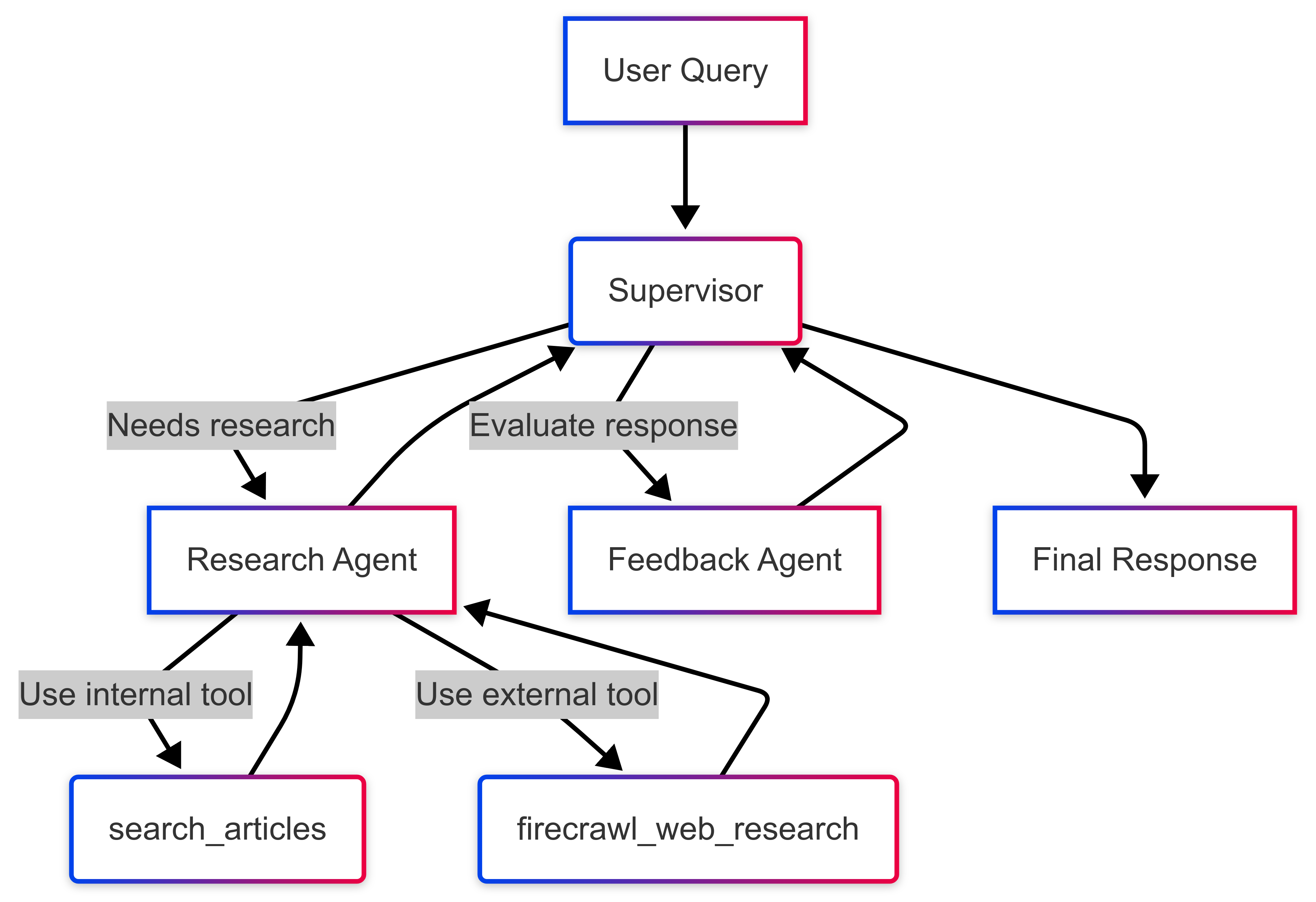
Supervisor Agent: The central router. Its prompt instructs it to analyze the overall goal and delegate sub-tasks to its team of worker agents.
Research Agent: A specialized ReAct agent armed with both the internal
search_articlestool and the externalfirecrawl_web_research_tool.Feedback Agent: A ReAct agent with no tools. Its sole purpose is to receive a generated response and critique it based on its prompt.
Pseudocode
// 1. Define the specialized worker agents
DEFINE research_agent = create_react_agent(LLM, [search_tool, web_tool], research_prompt)
DEFINE feedback_agent = create_react_agent(LLM, [], feedback_prompt)
// 2. Define the supervisor to manage the workers
supervisor = create_supervisor(
model = LLM,
agents = [research_agent, feedback_agent],
prompt = supervisor_prompt
)
// 3. Execute by invoking the supervisor
result = supervisor.invoke({"query": user_query})Pros ✅
Specialization & Modularity: Each agent has a clear, specialized role. You can improve the
Research Agent's prompting strategy without touching theSupervisor, making the system easier to scale and maintain.Dynamic Tool Use: The
Research Agentcan autonomously decide whether the query requires a simple internal lookup or a more comprehensive web search.Potential for Complex Workflows: The supervisor can chain agent calls together. It can ask the
Research Agentto find information and then pass the draft to theFeedback Agentfor review.
Cons ❌
Loss of Control (Still): While more structured, you're still relying on LLM reasoning for routing. The supervisor might get stuck in a loop or fail to delegate correctly if its prompt isn't perfectly tuned.
Compounded Latency: This is a huge issue. Every handoff between the supervisor and a worker agent is another expensive, high-latency LLM call. A simple query can become painfully slow as it bounces between agents.
"Black Box" Problem: Debugging is even harder. If the final answer is wrong, you now have to trace the path of delegation through multiple autonomous agents to find the point of failure.
Analysis
Relevance & Completeness: Very high potential. The ability to use web search as a fallback means it's far more likely to provide a complete answer.
Depth of Response: Moderate to High. The feedback loop allows for some level of refinement.
Latency: Poor. The overhead of the supervisor-agent communication makes this architecture noticeably slower.
Video: Web research to augment insufficient context
Setup 3: The Control Freak's Delight - Simple Manual Pipeline
Having found that both a single autonomous agent and a team of them were too unpredictable and slow, I swung the pendulum in the complete opposite direction. I decided to sacrifice autonomy for absolute control. This meant abandoning agentic delegation in favor of a rigid, deterministic workflow where I could explicitly define every single step.
Approach
Using LangGraph, I built a stateful graph that functions like a highly controlled flowchart. A central Orchestrator node acts as a smart router, analyzing the user's intent upfront. Based on its decision, the query is routed to a dedicated Search node or a general Chatbot node. This eliminates guesswork; the model doesn't decide whether to search, it just executes the step it's told to.
Architecture
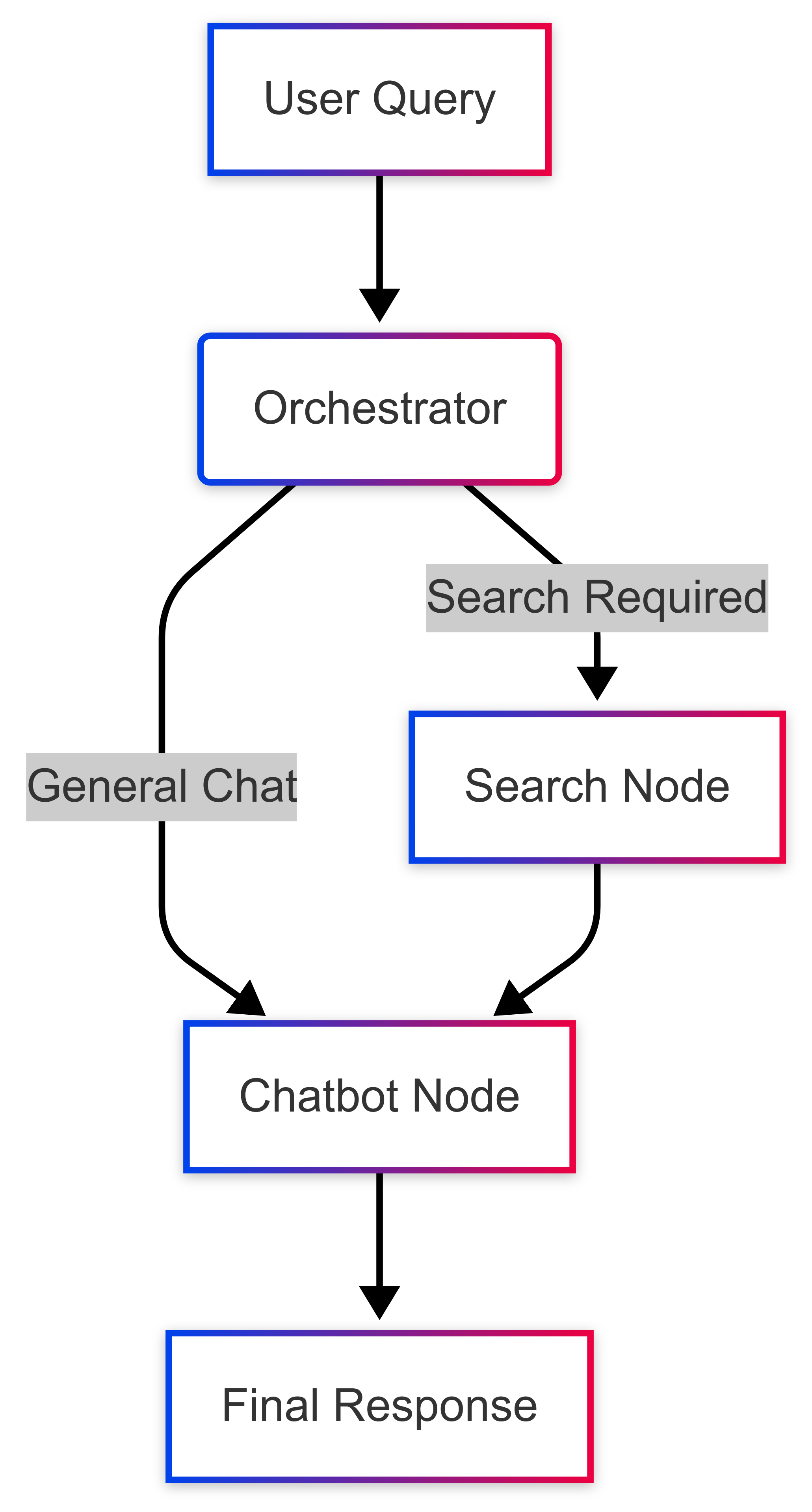
Orchestrator Node: A fire-and-forget LLM call using a strict prompt to output a JSON object. It determines if a search is needed, if the query is a simple greeting, or if a follow-up requires conversation history.
Search Node: A dedicated function that executes a semantic search against our knowledge base using the
search_articlestool. It has one job and does it well.Chatbot Node: The final synthesis step. It receives context from the conversation history and, if applicable, the search results to generate the final response.
State Management: The graph maintains the full state of the conversation using a Postgres checkpointer for persistent memory.
Pseudocode
// 1. Define a function for each step (node)
FUNCTION orchestrator_node(state): ...
FUNCTION search_node(state): ...
FUNCTION chatbot_node(state): ...
// 2. Build the graph structure step-by-step
DEFINE workflow = new StateGraph(ChatState)
workflow.add_node("orchestrator", orchestrator_node)
workflow.add_node("search", search_node)
workflow.add_node("chatbot", chatbot_node)
// 3. Define the explicit routing logic
workflow.set_entry_point("orchestrator")
workflow.add_conditional_edges("orchestrator",
IF search_is_required THEN route_to "search"
ELSE route_to "chatbot"
)
workflow.add_edge("search", "chatbot")
workflow.add_edge("chatbot", END)
// 4. Compile the graph and execute
graph = workflow.compile()
result = graph.invoke({"query": user_query})Pros ✅
Predictability & Reliability: The workflow is 100% deterministic. A simple "hello" will never trigger a costly vector search. It just works.
Maximum Performance (Low Latency): By deciding the path upfront, you avoid unnecessary tool calls or LLM invocations, which keeps latency and costs down for the vast majority of simple queries.
Robust Error Handling: Since each node is a distinct function, you can wrap them in specific try-except blocks, making the system more resilient.
Cons ❌
Rigidity: The pipeline is inflexible. If I want to add a web search capability, I have to add a new node and manually update the orchestrator's routing logic. The system can't adapt on its own.
Maintenance Overhead: The logic is fragmented across multiple nodes and routing functions. A simple change can require modifications in several places.
Limited Reasoning: The bot can't make complex decisions dynamically. It can't decide on its own that the initial search was insufficient and try another tool.
Analysis
Relevance & Completeness: Good, but capped by the quality of the initial RAG search.
Depth of Response: Shallow. It's a one-shot RAG system.
Latency: Good, for simple queries.
Setup 4: The Sisyphus Machine - Manual Pipeline with Reflexion
The manual pipeline was fast and reliable, but it was also dumb. The final challenge was to see if I could re-introduce deep reasoning capabilities into this controlled framework, but only when explicitly needed. This led to the final architecture: a manual pipeline with an optional, user-triggered self-correction loop.
Approach
This architecture extends the manual pipeline with a "Reflexion" loop. After the Chatbot node generates an initial response, it can be routed to an Evaluator node if the user's query contained phrases like "think deeply." The Evaluator scores the response. If the score is too low, it's sent to a Reflexion node, which generates critiques. These critiques are then fed back to the Chatbot node to inform a second, improved attempt.
Architecture

Extended State: The graph's state now tracks
iteration_count,current_response,evaluation_result, and a list ofreflections.Smarter Orchestrator: The orchestrator can now detect phrases like "think more critically" to trigger the
reflexion_requestedflag.The Loop: An explicit
Evaluator->Reflexion->Chatbotloop for iterative refinement, which can also trigger a fallback web search if internal RAG is insufficient.
Pseudocode
// 1. Define additional nodes for the loop
FUNCTION evaluator_node(state): ...
FUNCTION reflexion_node(state): ...
// (Re-use orchestrator, search, chatbot nodes from the simple pipeline)
// 2. Build the graph with the new nodes
DEFINE workflow = new StateGraph(ReflexionState)
workflow.add_node("orchestrator", ...)
workflow.add_node("search", ...)
workflow.add_node("chatbot", ...)
workflow.add_node("evaluator", evaluator_node)
workflow.add_node("reflexion", reflexion_node)
// 3. Define complex routing, including the self-correction loop
workflow.set_entry_point("orchestrator")
workflow.add_edge("search", "chatbot")
workflow.add_conditional_edges("chatbot",
IF reflexion_is_requested THEN route_to "evaluator"
ELSE route_to END
)
workflow.add_conditional_edges("evaluator",
IF evaluation_passed OR max_iterations_reached THEN route_to END
ELSE route_to "reflexion"
)
// This edge creates the feedback loop
workflow.add_edge("reflexion", "chatbot")
// 4. Compile and execute
graph = workflow.compile()
result = graph.invoke({"query": user_query})Pros ✅
Unmatched Depth and Quality: When triggered, this process can produce exceptionally high-quality, nuanced, and complete answers, turning a generic summary into a detailed analysis.
User-Controlled Depth: The power is in the user's hands. The bot stays fast for simple queries but has the capability to go deep when explicitly asked.
Forced Self-Correction: It's an implemented mechanism to combat "lazy" or generic LLM responses, forcing the model to adhere to a higher standard of quality.
Cons ❌
Astronomical Latency: The single biggest drawback. Each iteration adds 10-15 seconds. A query requiring two refinements can take over 30 seconds, which is unacceptable in a chat context.
High Cost: Every loop is a flurry of expensive LLM calls (generation, evaluation, reflection).
Brittle Evaluation: The entire loop hinges on the
Evaluatornode. If its scoring is inconsistent, the bot might loop unnecessarily or exit prematurely.
Analysis
Relevance & Completeness: Potentially perfect. It will keep trying until it gets it right.
Depth of Response: The deepest possible of all architectures.
Latency: Abysmal. This architecture sacrifices speed on the altar of quality.
Video - Self evaluation and reflection
The Bottom Line
This journey from a simple, uncontrollable agent to a complex, self-correcting machine was a masterclass in architectural trade-offs. Each step solved a problem but introduced a new, often more insidious one.
Latency is the king of chat. When building a RAG bot, speed is paramount. Users expect near-instantaneous responses. Any architecture that sacrifices latency for quality in a real-time context is fundamentally flawed.
A chatbot with amnesia is worse than useless; it's insulting. Forcing a user to repeat context from two messages ago is the fastest way to get them to abandon your bot. This isn't a feature; it's the bedrock of conversation. If your "memory" isn't backed by a persistent, thread-aware store like a real database, you haven't built a conversational agent - you've built an infuriatingly stupid command-line tool.
Optimize for the 99%. Most user queries are simple. The best architecture is one that answers these simple queries as quickly and cheaply as possible. This means a smart, upfront routing decision (like the orchestrator in the manual pipeline) is more valuable than a complex backend loop.
Go deep, but only on demand. The reflexion architecture, while a failure for chat, holds a valuable lesson: provide a mechanism for users to request deeper analysis. The ideal system is fast by default but has the capability to trigger a slower, more thorough process when needed.
Reflexion is the right tool for the wrong job. The self-correction loop is almost useless for a synchronous chatbot. However, this exact pattern is incredibly powerful for asynchronous tasks, like generating a deep research report or iteratively improving a piece of code. The failure here was a mismatch between the pattern and the interface.
Control is a spectrum, not a binary choice. This experiment shows the fundamental tension between explicit control (manual graphs) and emergent autonomy (agentic supervisors). There's no single right answer. The most robust systems will likely be hybrids: well-defined graphs that can delegate specific, sandboxed tasks to autonomous agents when a burst of complex reasoning is required. The art is in knowing where to draw the line.
Nice write-up. The ‘simple RAG bot’ tends to work after you solve the other parts: source curation, metadata standards, refresh cadence, and evals.