

Retrieval Benchmarking: Agentic vs. Vanilla, and What Actually Works in 2025
Does agentic retrieval trump vanilla retrieval? What's the top performing combination of datastores and embeddings from a retrieval accuracy perspective

Purpose
I set out to understand the state of the art in retrieval as of June 2025. There’s a lot of hype around vanilla retrieval being dead, and agentic retrieval being the new hot sauce. Additionally, we’re building several RAG based applications across the board, and it’s critical to ensure that we’re using the best retrieval setups across use cases.
So here are the questions we want to answer:
What are the commonly accepted benchmarks for evaluating retrieval systems?
What exactly is agentic retrieval, and how does it compare to traditional retrieval in terms of performance?
Are there any black-box, off-the-shelf retrieval solutions that can handle the full pipeline effectively?
Which embedding models currently offer the best performance, and how do they influence retrieval quality?
How do different vector datastores stack up against each other? Do they materially affect retrieval accuracy?
Why Evaluate Retrieval in Isolation?
Many popular evaluation methods focus on the end-to-end effectiveness of RAG systems - typically measuring the quality or accuracy of the final answers. While this approach is fully valid, it doesn’t isolate the quality of the retrieval component itself, which is often where performance bottlenecks reside.
I believe that a robust retrieval setup should be evaluated as a standalone module before it is integrated into a broader RAG system. Benchmarking retrieval independently ensures that downstream tasks like generation aren’t compensating for poor document recall or ranking.
Approach to this Research
To assess the current state of retrieval systems, I took the following steps:
Identified standard methods, datasets, and evaluation metrics commonly used in retrieval benchmarking.
Developed a flexible benchmarking framework, with the option to either write custom tooling or integrate existing libraries.
Surveyed the most widely-used and promising vector datastores for serving embeddings at scale.
Compiled a list of state-of-the-art embedding models from trusted sources and leaderboards (e.g., MTEB).
Ran experiments across a matrix of combinations, including:
Multiple vector datastores
A wide range of embedding models
Several benchmark datasets
Captured and analyzed results with the goal of producing concrete, actionable guidance for RAG system developers.
But first - What is Agentic Retrieval?
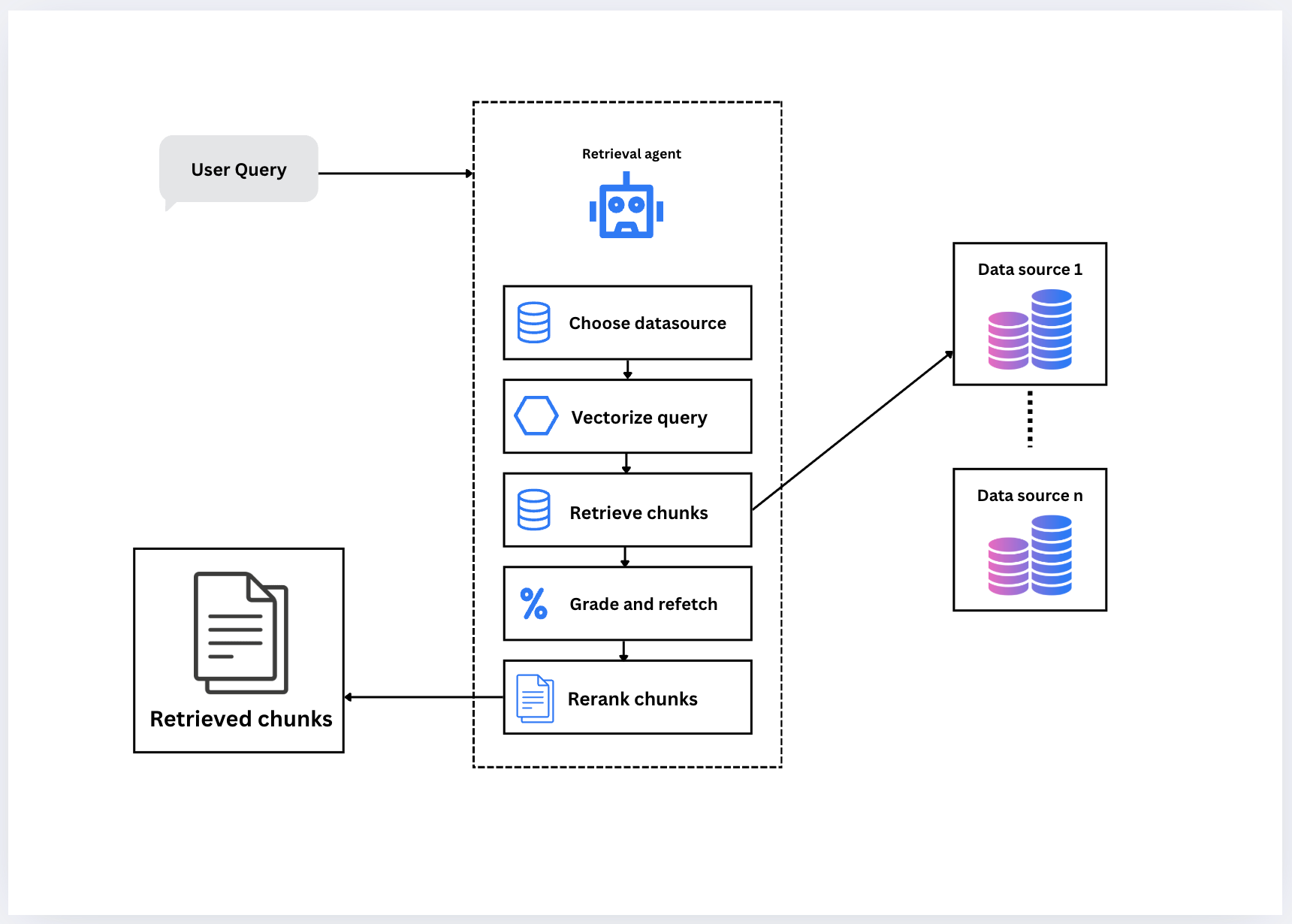
Traditional retrieval in Retrieval-Augmented Generation (RAG) pipelines often follows a rigid flow: a query is embedded, documents are fetched, and a model generates a response. But as expectations for accuracy and contextual relevance grow, this approach struggles to keep up. Agentic retrieval on the other hand is a dynamic, feedback-driven method that makes retrieval smarter and more adaptive.
An agentic retrieval system behaves more like a reasoning assistant with a series of likely steps:
Choose Data Source: It dynamically selects the most relevant data source depending on the intent of the query.
Vectorize Query: It transforms the user’s question into a high-dimensional vector using an embedding model.
Retrieve Chunks: Candidate documents or passages are retrieved using vector similarity search.
Grade and Refetch: Rather than settling for the first result set, the agent assesses quality (e.g., relevance, coverage) and may re-query or switch sources as needed.
Rerank Chunks: Retrieved results are re-ordered based on learned or rule-based scoring mechanisms to surface the most relevant information.
This loop is iterative and self-improving, leading to better recall, reduced hallucination in generation, and stronger alignment with user intent. It’s a foundation for building autonomous, retrieval-augmented agents capable of solving complex knowledge tasks with minimal human oversight.
What Makes a Retrieval System “Good”?
The key performance metrics used to evaluate retrieval systems are those defined by the BEIR benchmark suite:
k = the number of retrieved results. Evaluation was conducted using various k values (i.e., the number of retrieved results), specifically: [1, 3, 5, 10].
nDCG@k (Normalized Discounted Cumulative Gain): Measures ranking quality by rewarding systems that place the most relevant documents near the top.
MAP@k (Mean Average Precision): Captures the overall ranking performance by averaging precision values at each point where a relevant document is retrieved.
Recall@k: Evaluates how many of the total relevant documents are captured within the top k retrieved results.
Precision@k: Determines the proportion of retrieved documents within the top k that are actually relevant.
Together, these metrics provide a holistic view of retrieval effectiveness across both precision and recall dimensions.
Candidates for evaluation
End-to-End Agentic Retrieval Solutions
Azure AI Search (agentic)
Vertex AI RAG (agentic)
Vector Datastores
(Milvus and Chroma planned but not yet included)
Benchmark Datasets
BEIR Natural Questions - Corpus size - 200K of 2.8M available docs
Google FRAMEs - Corpus size of 2.5K
Microsoft MARCO V1.1 - Corpus size of 102K
HotpotQA - Corpus size of ~ 65K
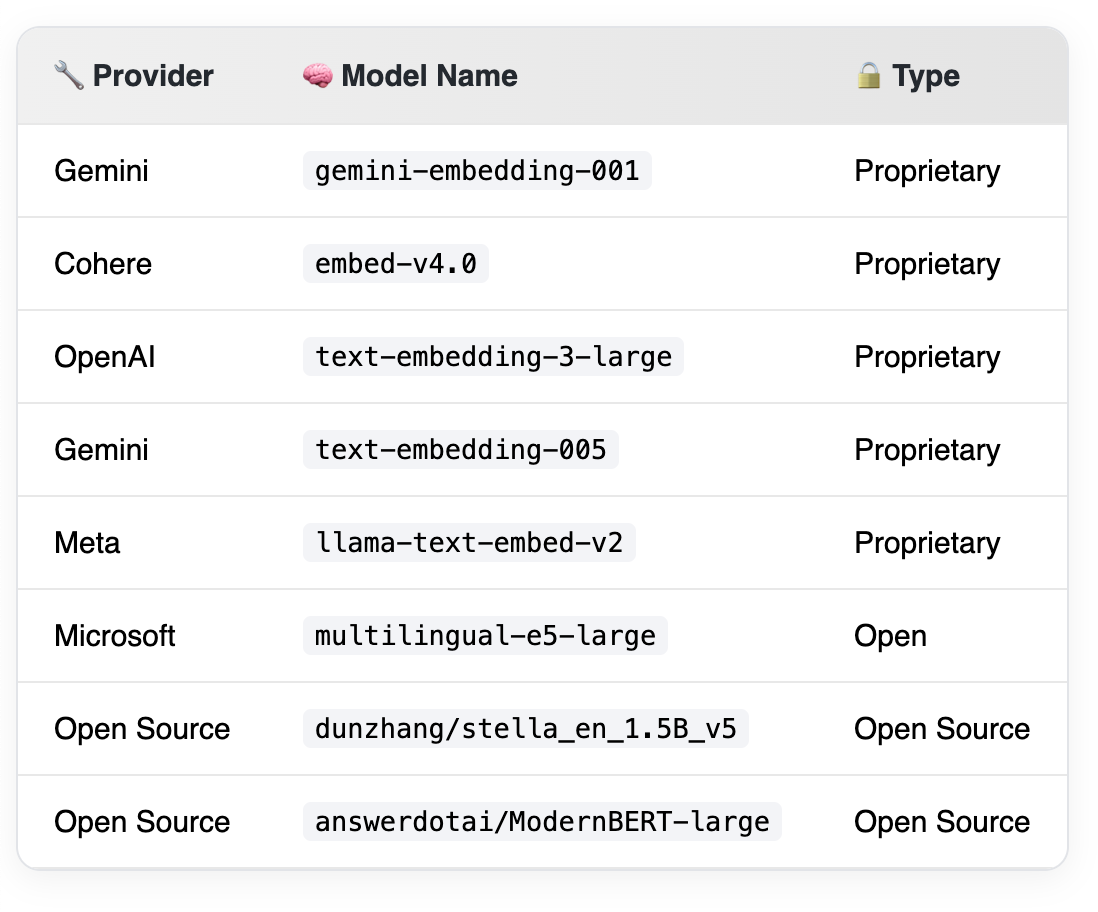
Embedding Models
I used a selection of proprietary and open source models, that I largely curated from the MTEB leaderboard
Code and Benchmark Setup
The benchmark setup is published on Github. Grab the code from the github repo (I’ll admit it’s a bit rough).
It has an interactive shell that you can spin up , which lets you download datasets, index them to a datastore of choice, and then evaluate the actual results. I’ve run over 40 experiments and published the results here.
Benchmark Results
Over 40 benchmark tests were run, across multiple combinations. Here’s a breakdown of the results from the benchmark, starting with datastore performance.
Datastore Performance
Between vector databases, the performance isn’t appreciably different. However what’s significant is that the black-box agentic setups are significantly weaker in retrieval accuracy
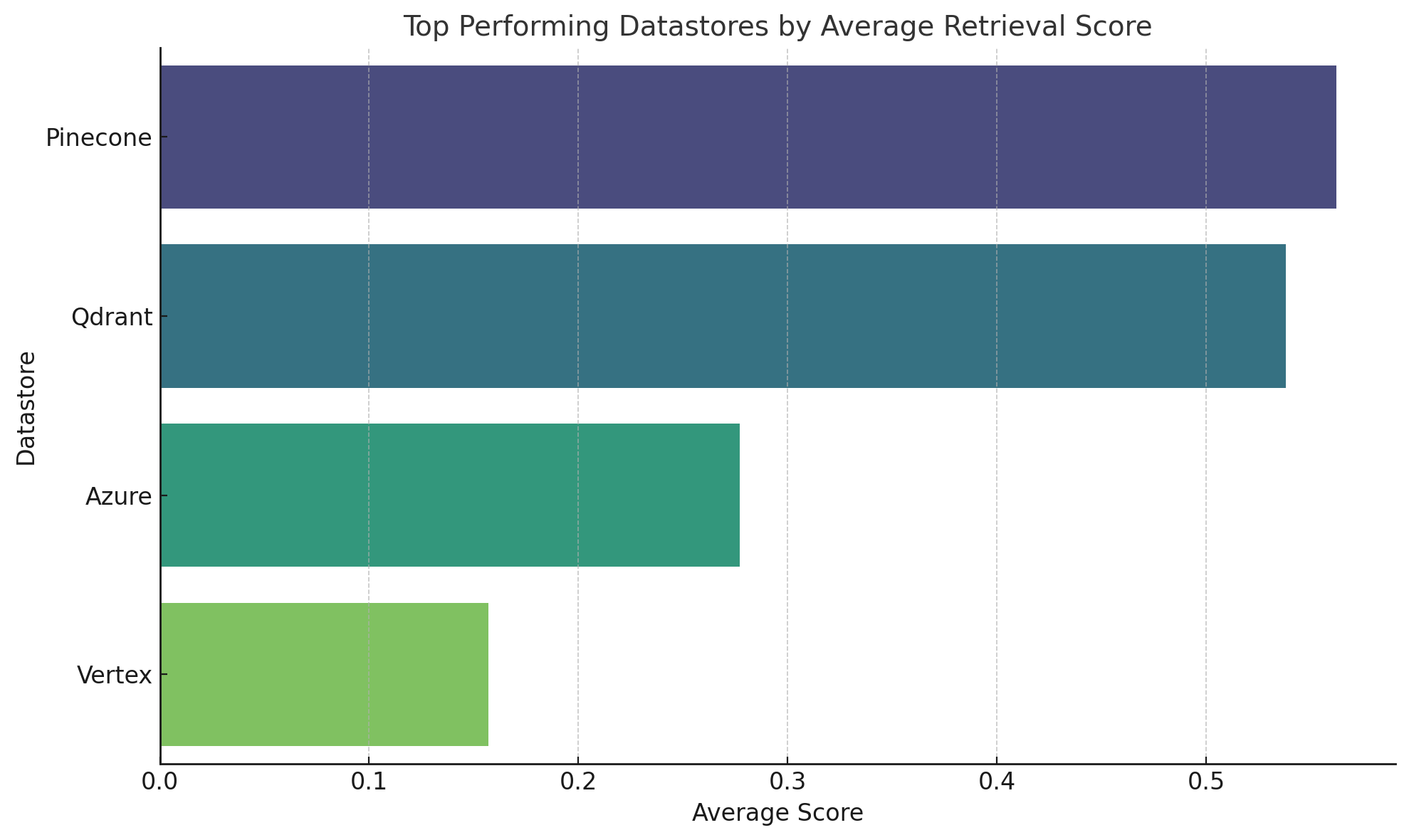
Pinecone and Qdrant are the top performers by a significant margin.
Azure performs moderately
Vertex trails significantly, despite some isolated strengths in Recall@10.
Outcomes Breakdown by Metric
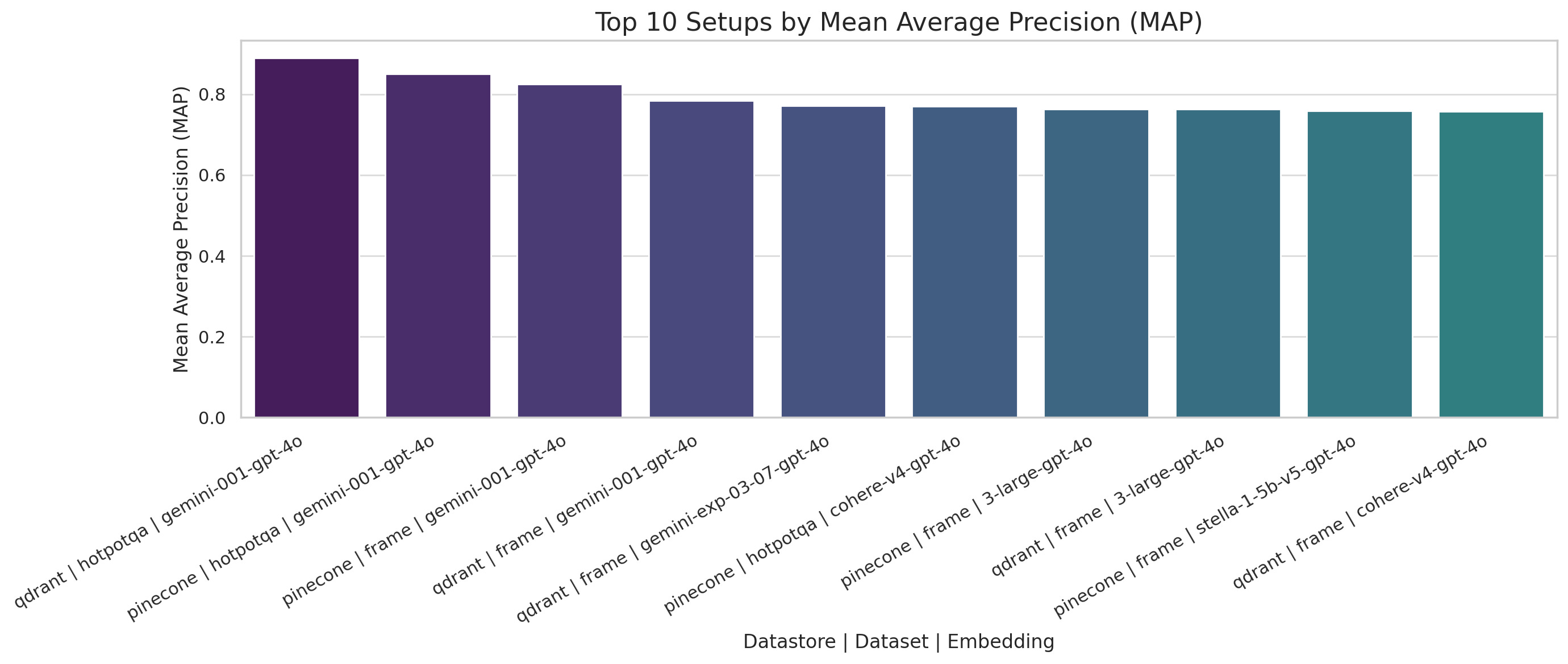
MAP@10 – Mean Average Precision
Gemini-001 with Qdrant and Pinecone leads MAP performance, especially on HotpotQA and FRAME datasets.
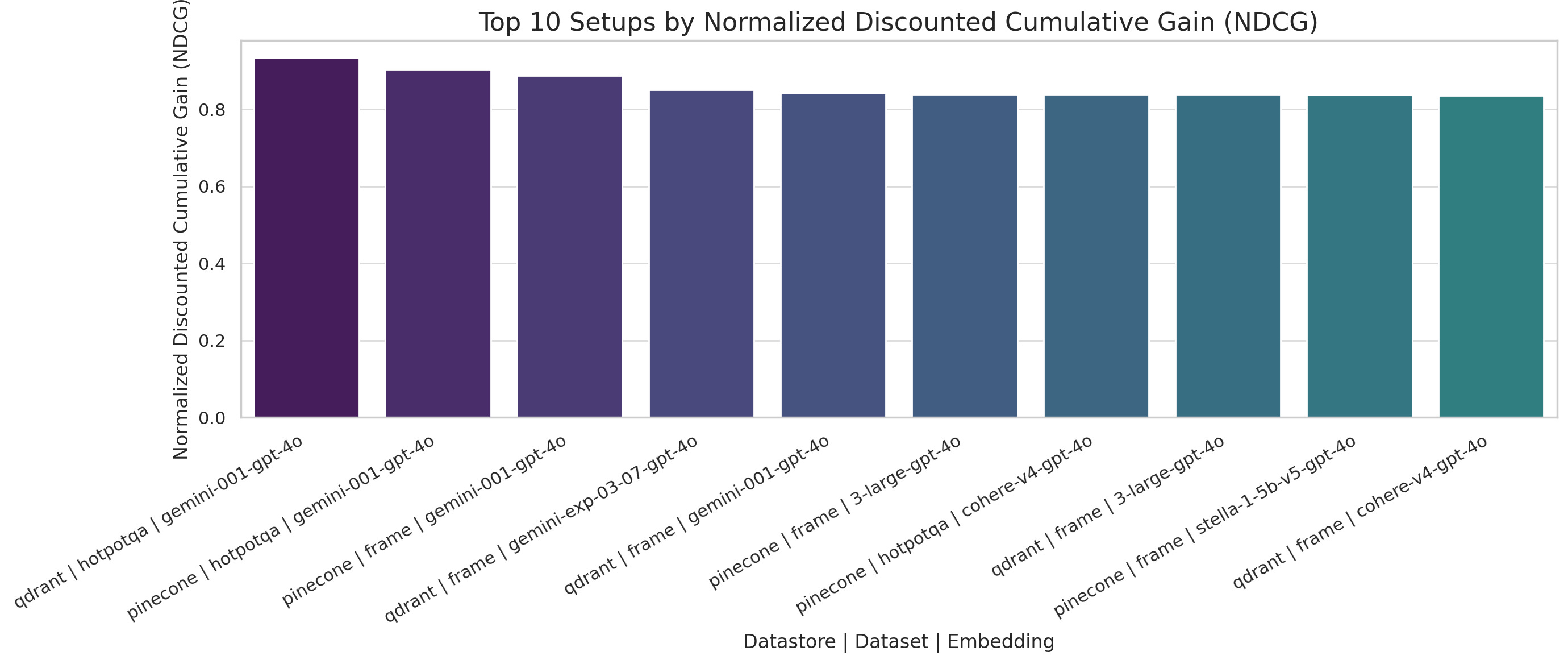
NDCG@10 – Normalized Discounted Cumulative Gain
Top setups prioritize highly relevant documents early, with Gemini models again dominating across both stores.
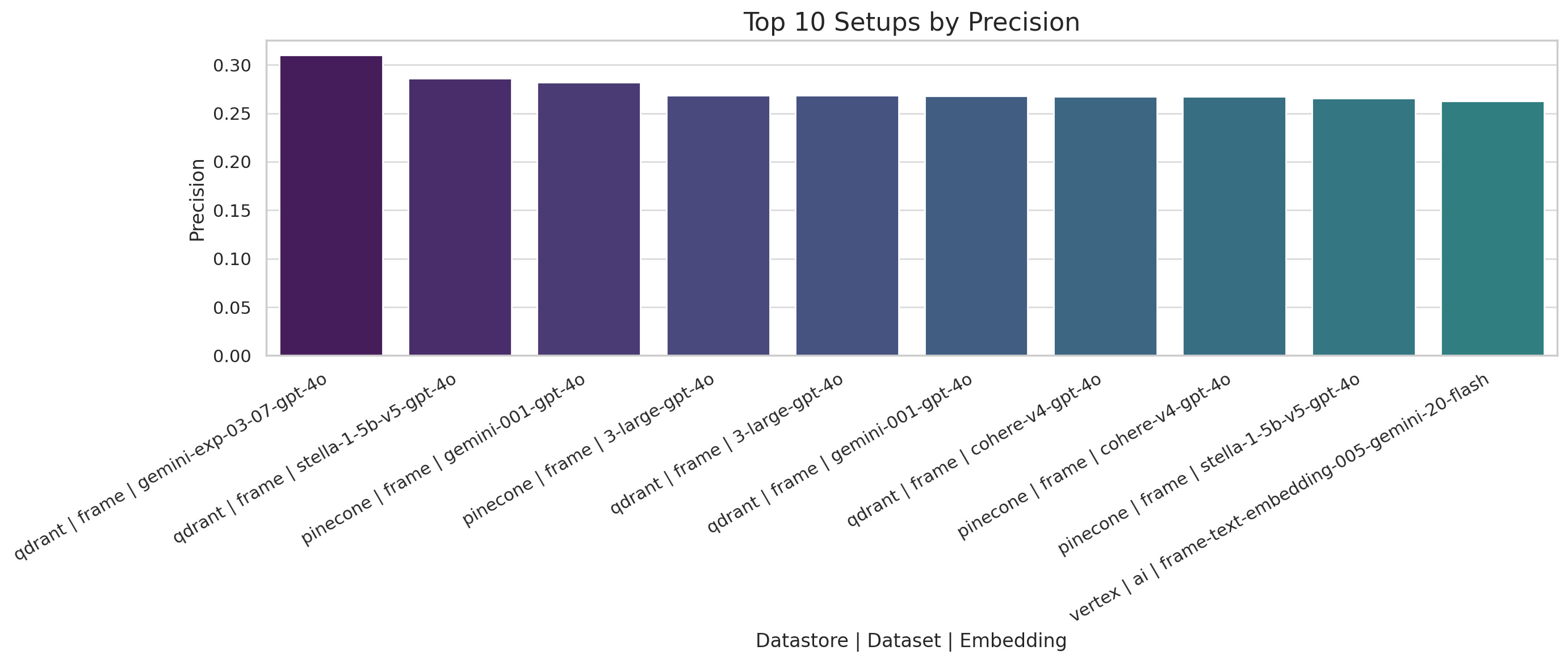
P@10 – Precision
Experimental Gemini and Stella models yield the highest precision, particularly when paired with Qdrant on FRAME.
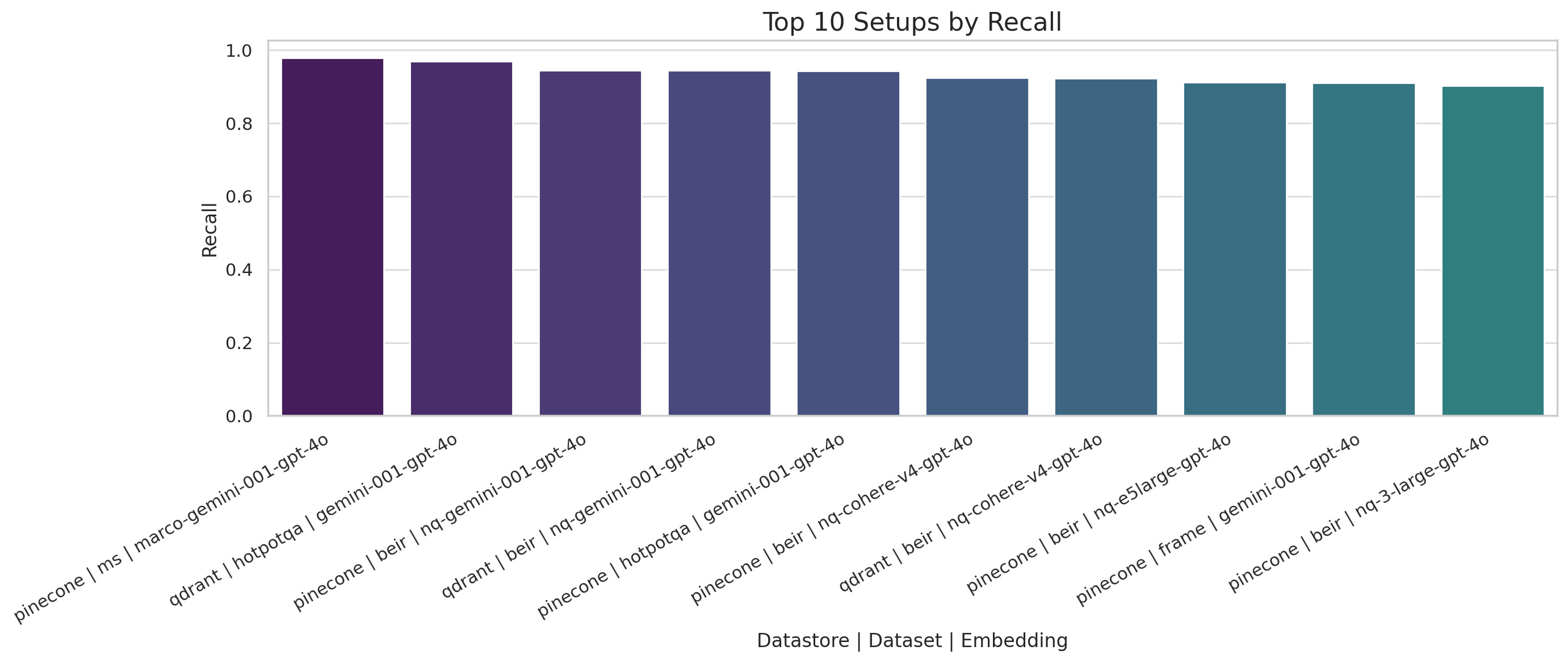
Recall@10 – Recall
Pinecone and Qdrant achieve near-perfect recall using Gemini-001 across diverse datasets including MS Marco, BEIR, and HotpotQA.
Metrics Breakdown by Embeddings
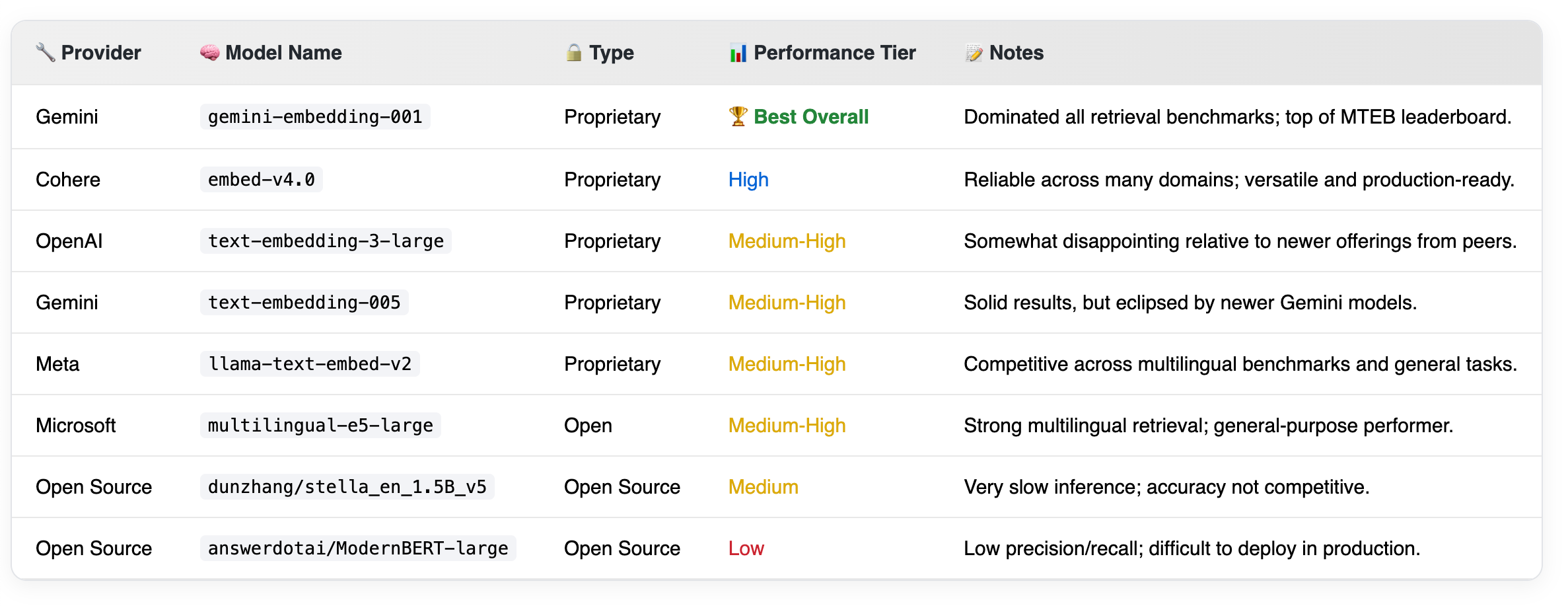
Gemini leads across all major metrics, delivering the highest precision (P@1) and best NDCG scores, especially at top ranks.
Cohere maintains a strong second position with balanced precision and recall.
Stella embeddings perform competitively, especially in top-k precision.
OpenAI 3-large lags behind slightly but still shows solid performance in Recall@10 and mid-tier precision, making it a viable option for less compute-intensive deployments.
Conclusions
1. 🧠 Agentic vs. Vanilla Retrieval: Simplicity Wins (for the moment)
Out-of-the-box agentic solutions like Vertex AI RAG and Azure AI Search’s consistently underperforms in our benchmarks compared to standard vanilla retrieval pipelines across all datasets. Despite marketing claims of intelligence and adaptability, these systems appear to add minimal value-primarily through a black-box agentic rerank step that does not improve core retrieval quality.
This underperformance likely stems from their lack of transparency and tunability. The black-box nature of these services severely limits control over retrieval logic and optimization.
A more promising path lies in custom-built agentic pipelines using open frameworks like Haystack, LangGraph, or CrewAI, which offer full control, modularity, and better integration of task-specific intelligence.
2. 🗃️ Datastore Choice: No Significant Impact
The benchmark confirms that choice of vector datastore-whether Pinecone or Qdrant-has negligible effect on retrieval performance. Both yielded near-identical scores across all metrics and datasets.
This is expected: vector databases are primarily neutral infrastructure layers, designed to index and retrieve vectors efficiently. They don’t influence the semantic quality of retrieval-only the mechanics of access.
It’s reassuring to validate this assumption with empirical evidence: retrieval quality is largely independent of the datastore when all else is equal.
There is no appreciable difference in performance between datastores
Both pinecone and qdrant yielded very similar scores in retrieval accuracy.
This is well in line with what one would expect, considering the datastores are meant to be neutral storage layers. However it is good to confirm this
3. 🧬 Embedding Models: The Most Critical Factor
The most decisive factor in retrieval performance was the choice of embedding model. The gap between older models and newer offerings is stark:
Gemini’s
embedding-001is the clear winner, leading across every metric, and strongly correlating with top performance on public benchmarks like MTEB. The single drawback with them is that the current vertex API allows only one document per embedding request, making it excruciatingly slow. However I expect this will change very soon.Cohere’s newer models also perform well, offering a solid balance of speed and accuracy.
OpenAI’s
text-embedding-3-large, while an improvement over older versions, lags behind significantly compared to Gemini.Open-source models like
stella-1.5b-v5could be viable, particularly for specialized domains. For general use, their inferior performance and slow inference times make them quite convenient to use, without powerful infrastructure.
In short: picking high-quality embeddings is the most impactful decision in building a performant RAG system. Given that embedding choice locks you into a particular vector space, changing models later entails expensive full re-indexing.