Agentic Retrieval Deepdive
From Off-the-Shelf to Custom: A Benchmarking Study of Agentic Retrieval Pipelines

AI platform and tool vendors are propounding agentic retrieval as a better alternative to traditional dense or hybrid vector searches.
Do RAG systems truly benefit from agentic retrieval, or is it just sequential orchestration dressed up in a new avatar?
Each vendor has their own spin on agentic retrieval. Common offerings are:
Automated query routing to the right datastore
Query decomposition and planning
Hybrid search (sparse + dense)
Reranking
Grading and refetching
Which of these actually move the needle in retrieval accuracy? I wanted to get to the bottom of this.
The Experiments
This study benchmarks four RAG setups using the FRAMES dataset , a testbed that challenges systems with tricky, intent-rich queries. Here are the evaluation candidates:
Setup 1: Azure AI Search’s new agentic retrieval features
Setup 2: Managed via Vertex AI RAG Engine
Setup 3: Agentic orchestration using Crew AI
Setup 4: A sequential modular pipeline with decomposition and reranking
Evaluation metrics included:
Retrieval accuracy (vs traditional dense retriever)
Query latency
Cost per query
Architecture transparency and control
Setup 1: Azure AI Search
Launched in mid-2025, Azure AI Agentic Retrieval is Microsoft’s latest enterprise search engine, claiming to offer advanced capabilities like query planning, dense–sparse fusion, hybrid reranking, and dynamic refetching. It supports multiple datastores (e.g., files, SQL) and advertises ease of development, and accuracy with tunable, explainable internals.
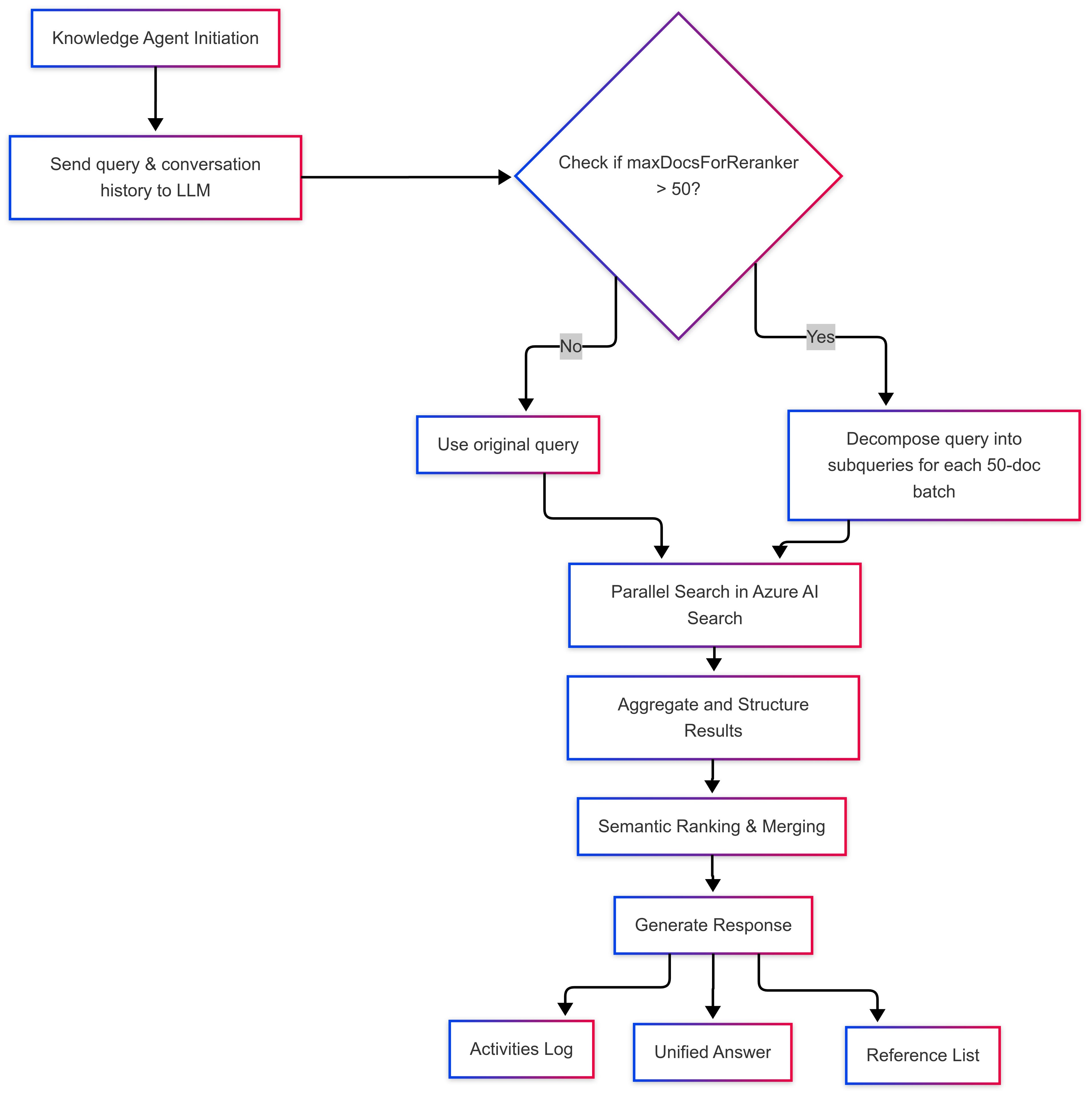
Azure Retrieval Process Overview
Initiation: A knowledge agent sends the user query and any relevant conversation context to an LLM for preprocessing
Query Decomposition: If
maxDocsForReranker > 50, the LLM breaks the query into subqueries (1 per 50-doc batch).Parallel Execution: Subqueries run in parallel on Azure AI Search, producing structured results with references.
Ranking & Merging: Outputs are semantically ranked and merged.
Response Format: The agent returns:
A unified answer string,
A reference list,
An activities log of all operations.
This setup combines retrieval orchestration with LLM reasoning, enabling scalable, high-quality search across varied data sources.
Setup 2: Google Vertex RAG Engine
Google’s Vertex AI RAG Engine is a fully managed, opinionated pipeline for Retrieval-Augmented Generation. It focuses on simplicity and automation-handling ingestion, indexing, retrieval, and generation-without requiring deep customization. While designed for ease of use, it lacks some features found in other agentic setups - such as query decomposition, and integrations to third party data sources outside of Google.
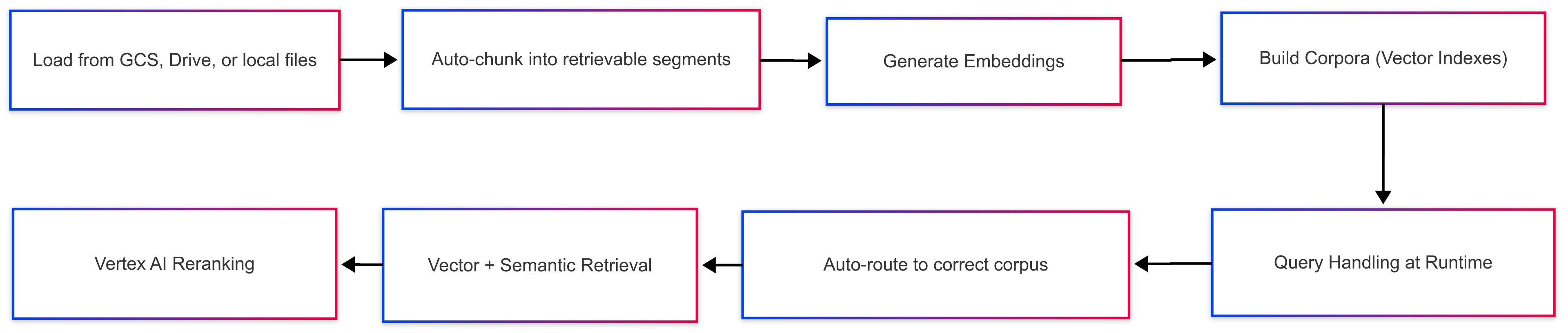
Retrieval Process Overview
Data Ingestion: Supports loading data from local files, Google Cloud Storage, and Google Drive.
Data Transformation: Automatically chunks documents into retrievable segments.
Embedding & Indexing: Generates embeddings and builds vector indexes, called corpora, optimized for search.
Query Handling: At runtime, the engine:
Automatically routes the query to the appropriate corpus (supports multiple corpora).
Handles query processing, retrieval, and re-ranking based on semantic relevance out-of-the-box.
Response Generation: Combines retrieved data with the user query to generate grounded responses using a PaLM or Gemini model.
Setup 3: Custom - Crew AI
This retrieval pipeline combines CrewAI, Pinecone, OpenAI, and Cohere to orchestrate a modular, agentic retrieval flow with multi-step reasoning. It supports query decomposition, vector-based retrieval, reranking, and optional grading - all coordinated through an autonomous agent framework.
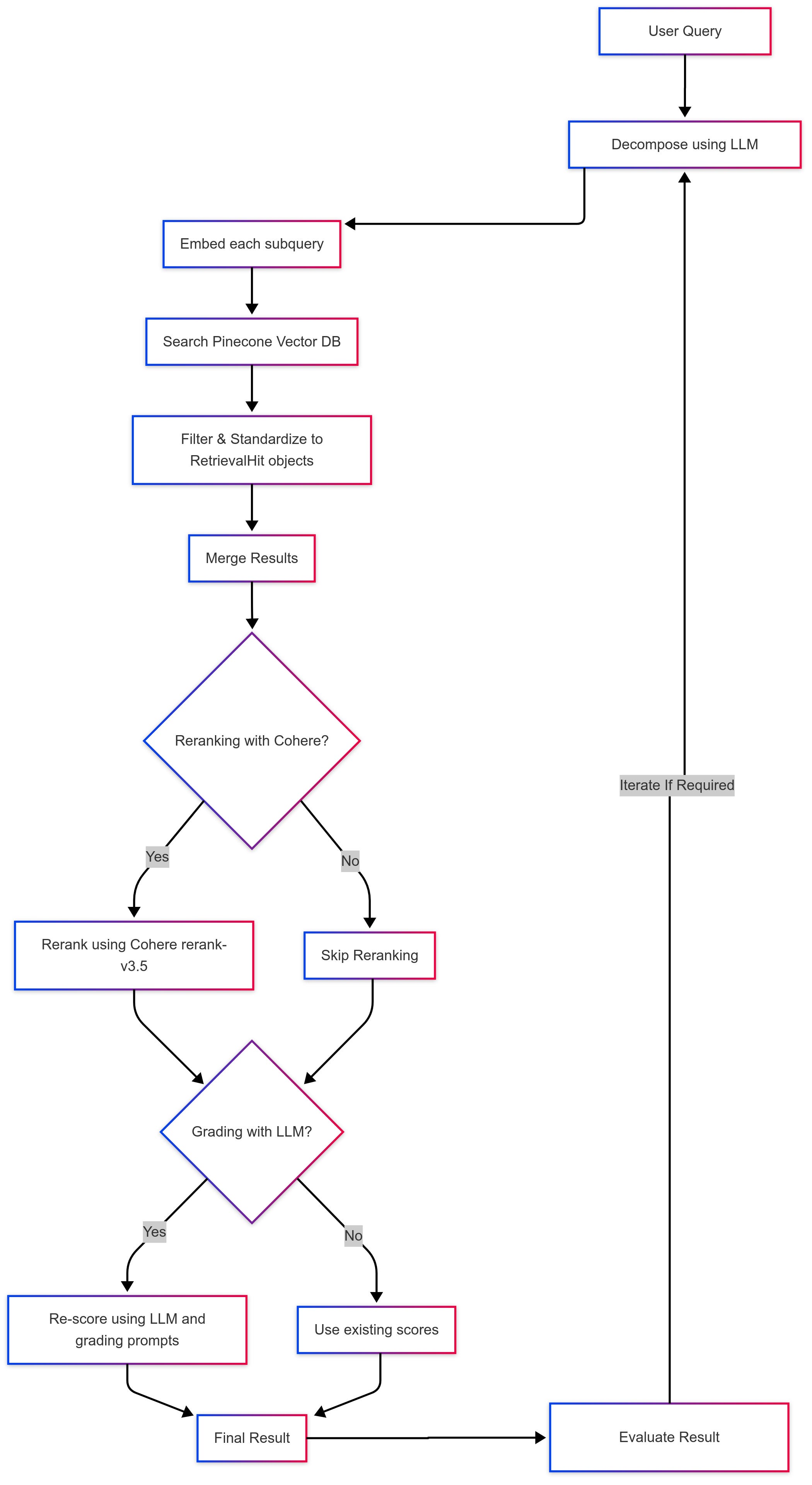
Retrieval Process Overview
Query Decomposition: A GPT-4o-powered tool breaks complex queries into multiple variants or subqueries for improved recall.
Vector Retrieval: Each subquery is embedded using a configurable embedding model and executed against a Pinecone index. Retrieved results are filtered and structured into standardized
RetrievalHitobjects.Reranking (Optional): Results from all subqueries are merged and passed to Cohere’s
rerank-v3.5model, which returns a top-K ranking based on semantic relevance to the original query.Grading (Optional): An LLM can further assess and re-score the reranked results using custom grading prompts for added precision.
Agent Execution: A CrewAI
Agentmanages the tool flow, executes query decomposition, invokes retrieval tools, calls the reranker, and enforces output format constraints.
Agent Code Snippets
Tool Setup
class RerankTool(BaseTool):
name: str = "RerankTool"
description: str = "Reranks retrieved docs using Cohere API"
args_schema: Type[BaseModel] = RerankInput
def __init__(self, cohere_client):
super().__init__()
self._cohere_client = cohere_client
def _run(self, query: str,
retrieved_docs: List[RetrievalHit],
top_k: int = 10
) -> List[RetrievalHit]:
docs = [doc["text"] for doc in retrieved_docs]
response = self._cohere_client.rerank(
model="rerank-v3.5",
query=query,
documents=docs,
top_n=min(top_k, len(retrieved_docs))
)
print("Cohere Reranker response:", response)
return [
RetrievalHit(
doc_id=retrieved_docs[r.index]["doc_id"],
text=retrieved_docs[r.index]["text"],
score=r.relevance_score
) for r in response.results
]
class GradeTool(BaseTool):
name: str = "GradeTool"
description: str = "Grades retrieval quality using LLM."
args_schema: Type[BaseModel] = GradeInput
def __init__(self, openai_client):
super().__init__()
self._openai_client = openai_client
def _run(self, query: str,
retrieval_results: List[RetrievalHit],
top_k: int = 10
) -> List[RetrievalHit]:
prompt = f"""
Grade each document for relevance on a scale of (0.0 to 1.0).
Query: {query}
Documents: {json.dumps([r.dict() for r in retrieval_results]}
Return a JSON array of dicts with "doc_id", "text", and "score".
"""
response = self._openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
try:
graded_list=json.loads(response.choices[0].message.content)
return [
RetrievalHit(**doc)
for doc in graded_list
if all(k in doc for k in ("doc_id", "text", "score"))
]
except Exception:
return []
Equip and execute the agent
tools = [
DecomposeQueryTool(openai_client=self.openai_client),
RetrieveTool(
index_name=self.index_name,
namespace=self.namespace,
embedding_helper=self.embedding_helper,
pinecone_client=self.pinecone_client
),
RerankTool(cohere_client=self.cohere_client),
GradeTool(openai_client=self.openai_client)
]
agent = Agent(
role="Agentic Retriever",
goal="Maximize relevance of documents for any given query using query decomposition, search, and other tools",
backstory="Expert in retrieval of the most relevant documents from Pinecone based on a user query in natural language.",
tools=tools,
verbose=True,
max_iter=3,
max_retry_limit=2
)
task = Task(
description=(
f"For the given query: '{query}', retrieve the top
{top_k} most relevant documents."
...
),
expected_output="List of dicts: [{'doc_id': ..., 'score':
..., 'text': ...}]",
agent=agent
)
crew = Crew(agents=[agent], tasks=[task], verbose=True)
crew_output = crew.kickoff()Setup 4: Sequential Retriever with Pinecone + Cohere Reranking
This setup defines a custom sequential retrieval pipeline using Pinecone for dense/hybrid search, OpenAI for query decomposition, and Cohere for reranking. It emphasizes controlled, step-by-step logic with optional decomposition and deduplication before final scoring.
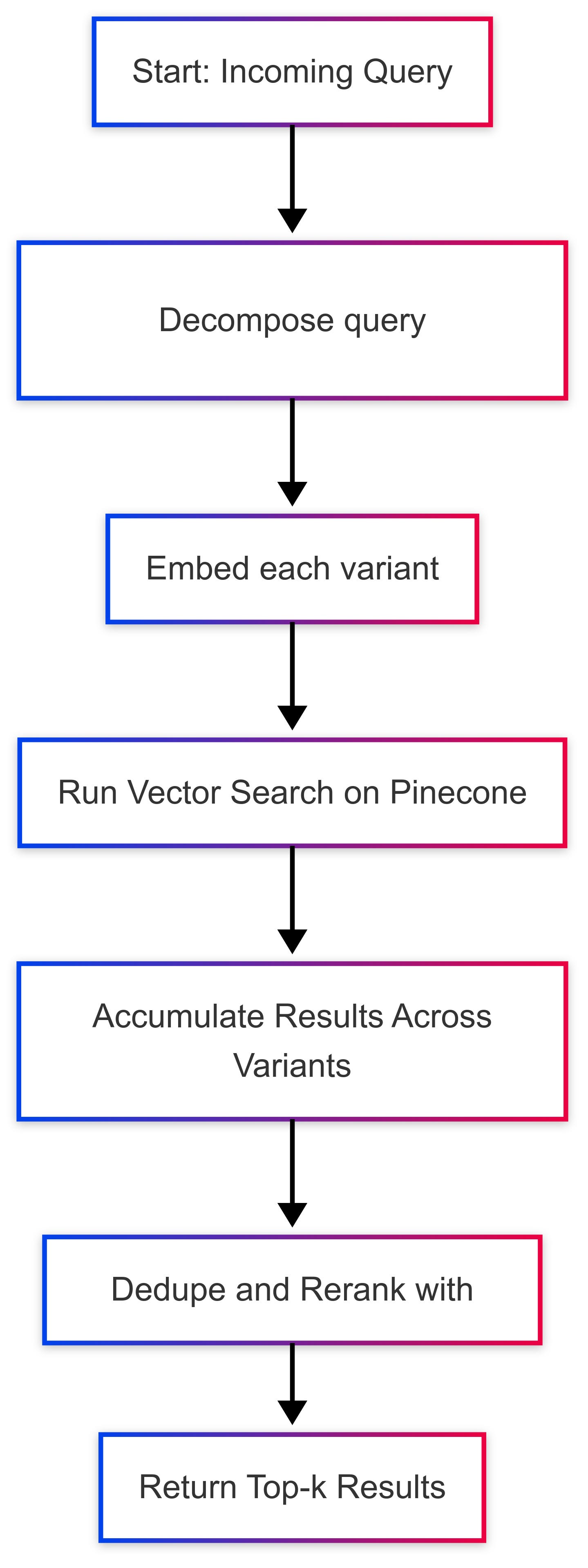
Retrieval Process Overview
Query Decomposition: A GPT-4o-based decomposer generates 4 semantically faithful variants of the query - even for simple queries - to improve recall across phrasings. Complex queries are broken down into subqueries.
Sequential Vector Search:
Each decomposed subquery is embedded and executed independently against a Pinecone index.
The system accumulates results across all subqueries, deduplicating by document ID.
Reranking:
The merged, unique results are reranked using Cohere's
rerank-v3.5model.Top-k documents are returned based on semantic relevance to the original query.
🔑 Key Findings
1. Retrieval Quality
Surprisingly, none of the advanced setups outperformed a strong dense baseline. In fact, all performed worse, with Vertex AI RAG and Azure AI Search performing significantly worse.
Even agentic and reranked systems like Crew AI and Sequential pipelines showed 2–3% lower accuracy, often due to noisy decomposition or coordination overhead.
2. Latency Trade-offs
Vertex AI RAG Engine offers a fast retrieval experience once indexed but suffers from slow ingestion/setup times.
Azure AI Search is the fastest overall in terms of query and ingestion latency.
Crew AI Agentic suffers from extreme latency (~30s/query), making it unsuitable for responsive applications. Too many repeated loops, which could perhaps be remedied with heavy tuning
Sequential pipelines are moderately slow due to multi-stage processing.
3. Practical Friction
Azure AI Search, has a promising architecture, and easy setup. But it feels early-stage, with limited observability and tuning options for production use.
Vertex AI RAG works well with existing corpora sitting on GCS. Any other form of data - for example in a DB or a benchmark dataset is incredibly slow to ingest.
Sequential pipelines are simple but inherently brittle - especially when decomposition yields low-signal subqueries or the reranker lacks grounding.
Custom agentic retrieval while in theory has massive potential, introduces too much latency overhead not justified for most retrieval tasks.
🧭 Conclusions
Generally speaking, building a retrieval agent doesn’t make sense in the current state of tech-maturity. A higher level agent armed with retrieval tools is the way to go.
Vertex AI RAG: Not so great developer experience, excruciatingly slow to index documents, poor retrieval quality.
Azure AI Agentic: Despite its promising architecture, it just did not deliver what was promised in terms of retrieval accuracy
Custom Agentic: Overengineered for basic cases - slow and expensive without clear quality gains.
Sequential RAG: Reasonable fallback option - but needs careful tuning to actually realize performance improvements.
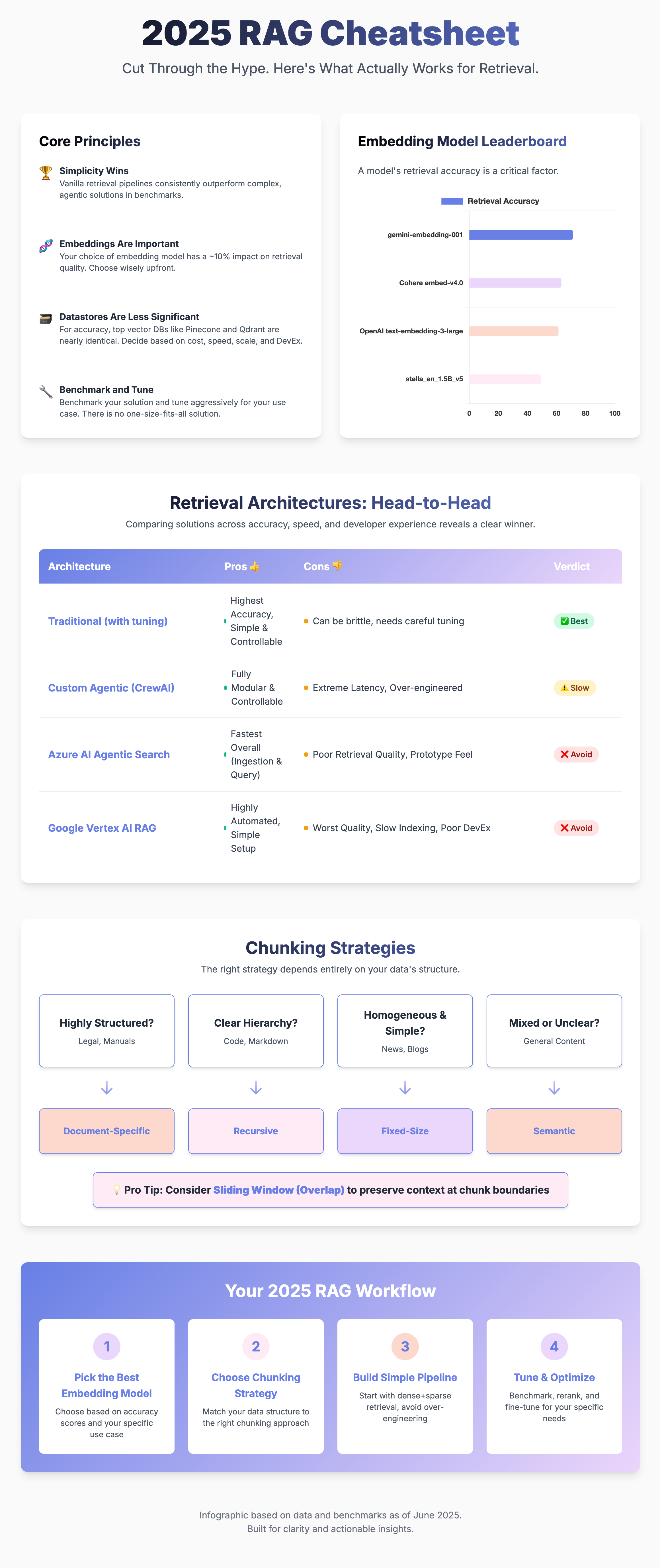
RAG Cheatsheet
To help with decision making around choice of technologies and approaches for building your retrieval system, I’ve put together a cheatsheet.