


The Evolution of Text-to-Video Technology
Text-to-video AI models represent one of the most significant breakthroughs in generative AI, enabling the creation of dynamic video content from simple text descriptions. These technologies have rapidly evolved from producing basic, short clips to generating sophisticated, high-resolution videos with realistic physics, detailed characters, and complex narratives.
However, significant challenges remain in spatial/temporal consistency, video length limitations, and computational requirements. This comprehensive analysis examines the current state of text-to-video generation, examining theoretical foundations, comparing leading models, and exploring the challenges and solutions in this rapidly developing field. We also introduce ttv-pipeline, an open-source tool that addresses critical limitations through intelligent automation.
Theoretical Foundations
Text-to-video generation leverages several foundational technological strategies, each shaping how models interpret prompts and synthesize moving images:
GAN-Based Approaches

Generative Adversarial Networks (GANs) were among the first architectures to demonstrate convincing video synthesis. GANs employ a generator to create video content and a discriminator to assess its realism, driving the generator to improve over time. While GANs such as MoCoGAN (Tulyakov et al., 2018) and TGAN (Saito et al., 2017) pioneered the field, they have largely been surpassed by diffusion models in terms of video quality, temporal consistency, and scalability.
Diffusion Models

Diffusion models are the leading paradigm in contemporary video generation. These models operate by learning to reverse a process in which noise is incrementally added to training data, enabling them to synthesize new videos by starting from pure noise and progressively denoising it into coherent sequences. Diffusion-based approaches are known for their ability to produce high-fidelity, temporally consistent videos. Prominent examples include Stable Video Diffusion (Stability AI, 2023), OpenAI Sora (OpenAI, 2024), and CogVideoX (CogVideoX paper, 2024).
Autoregressive Transformers

Autoregressive transformer models generate videos one frame or segment at a time, with each output conditioned on preceding content. While less prevalent than diffusion models for video, transformers excel at maintaining narrative and temporal coherence over extended sequences. VideoPoet (Google, 2024) is a notable example, employing a large-scale transformer architecture to generate videos that preserve context and storyline throughout longer clips.
Hierarchical Decoupling

Many advanced video generation models utilize hierarchical strategies to balance quality and efficiency. Typically, these models first generate keyframes or anchor points that define the overall scene and structure. Intermediate frames are then synthesized to create smooth, coherent motion between keyframes. This hierarchical approach not only enhances consistency across the video but also reduces computational demands. Techniques like those used in Imagen Video (Google, 2022) and Make-A-Video (Meta, 2022) exemplify this methodology.
Spatial and Temporal Modeling in Video Generation
A central challenge in video generation is achieving consistency across both spatial and temporal dimensions—ensuring that each frame is visually coherent and that motion and narrative flow smoothly over time.
Spatial Consistency

Spatial consistency refers to the model’s ability to maintain the appearance, structure, and positioning of objects within each frame. This includes preserving details such as lighting, textures, and relative spatial relationships. Advanced models like OpenAI Sora (OpenAI, 2024) and Runway Gen-4 (Runway, 2024) demonstrate strong spatial fidelity, generating scenes where objects remain visually realistic and stable throughout the video.
Temporal Consistency

Temporal consistency is crucial for producing videos where motion, object continuity, and narrative progression are believable. Without robust temporal modeling, generated videos may exhibit issues such as flickering, inconsistent object trajectories, or unnatural transitions between frames. State-of-the-art models address these challenges through techniques like temporal attention, motion-aware conditioning, and explicit modeling of object trajectories (Ho et al., 2022; Singer et al., 2024).
Space-Time Diffusion

Modern approaches increasingly treat video as a unified "space-time" volume rather than as a sequence of independent frames. For example, Google’s Lumiere (Singer et al., 2024) introduced a space-time diffusion process that jointly models spatial and temporal dependencies, enabling the generation of videos with both high spatial detail and smooth, coherent motion. This methodology has influenced subsequent models such as Veo 2 and Veo 3 (Google DeepMind, 2024), which further refine space-time modeling for longer and higher-resolution video generation.
Technical Challenges and Solutions
The Training Data Bottleneck
A critical insight from initial investigation revealed a fundamental constraint: while text-to-video presents much harder inference challenges than text-to-image, the available training data is significantly more limited. The scarcity of high-quality text-video paired samples compared to text-image datasets creates a significant bottleneck in model development.
This limitation has driven innovative approaches:
Transfer Learning: Leveraging pre-trained image models
Synthetic Data Generation: Creating artificial training sequences
Image-to-Video Bootstrap: Using reference images to improve quality and accuracy
Temporal Consistency
Problem: Maintaining consistency of objects, characters, and scenes across video frames.
Solutions:
Space-Time Diffusion: Processing video as a unified 3D block (2D space + time) rather than sequential frames.
Motion Modules: Specialized components focused solely on realistic motion patterns.
Memory Mechanisms: Storing and referencing previously generated content to maintain consistency.
Keyframe Anchoring: Generating key moments first, then filling in transitions between them.
Object Permanence
Problem: Objects disappearing, changing, or behaving unnaturally between frames.
Solutions:
World Modeling: Creating internal representations of scene elements and physics.
Object-Centric Generation: Tracking individual objects separately throughout generation.
Physics Simulation: Incorporating simplified physics models to guide natural motion.
Attention Mechanisms: Focusing model awareness on important scene elements.
Limited Video Length
Problem: Most models struggle to generate videos longer than 5-10 seconds.
Solutions:
Video Stitching: Generating sequential clips that can be combined seamlessly.
Keyframe Extension: Using the final frame of one clip as the starting keyframe for the next.
Hierarchical Generation: Creating a low-resolution storyboard first, then filling in details.
Narrative Planning: Incorporating high-level planning before detailed generation.
These solutions are implemented with automation in the ttv-pipeline utility discussed later in this article.
Computational Requirements
Problem: Video generation demands significantly more resources than image generation.
Solutions:
Model Compression: Reducing parameter count while maintaining quality.
Efficient Architectures: Designing models specifically for video rather than adapting image models.
Progressive Generation: Starting with low resolution/framerate and gradually enhancing.
Hardware Optimization: Creating specialized implementations for various hardware configurations.
Advanced Video Generation Techniques
Video Segment Chaining
Image-to-Video Transformation
While text-to-video generates content from descriptions, image-to-video uses visual references as starting points:
Style Control: Reference images establish the visual style, lighting, and character appearance.
Motion Addition: The model adds motion to static scenes based on text descriptions or learned patterns.
Scene Extension: Some models can extend beyond the frame of a reference image, imagining what exists outside the boundaries.
This approach has proven particularly effective for character animation and consistent scene rendering, as models like Wan 2.1, CogVideoX, and Luma Ray demonstrate strong capabilities in this area.
Chaining Videos through Last-Frame Images
Platforms like Runway allow users to chain video segments by:
Generating an initial 5-10 second clip
Manually pausing at the last frame
Using that frame as the starting point for the next segment: a reference image for an Image-to-Video model
Repeating the process to build longer sequences
While effective, this approach requires significant manual effort and careful timing to capture appropriate transition frames.
Keyframe-Based Generation
Keyframe-based video generation represents one of the most promising approaches for creating longer, more controlled videos. This approach:
Establishes Anchors: The user or model defines key moments (keyframes) in the desired video.
Fills Transitions: The AI then generates intermediate frames that create smooth, natural transitions between keyframes.
Maintains Consistency: By working with defined anchor points, the model can better maintain character and scene consistency.
Model platforms like Runway Gen-4, Luma Ray, and Hunyuan particularly excel at this approach, allowing users to upload multiple reference images that serve as keyframes, creating more predictable and controlled outputs. However, none of them offer this in an automated fashion via APIs.
Services like EasyVid implement a keyframe-based approach:
Generate multiple static images representing key moments
Use image-to-video models to animate transitions
Manually adjust timing and transitions
Combine segments into final output
This method offers more control but remains a UI-intensive operation that's difficult to automate or scale.
Prompt Engineering for Video
Creating effective videos requires specialized prompt engineering techniques:
Cinematic Language: Using film terminology like "close-up," "tracking shot," or "aerial view" to control camera behavior.
Temporal Markers: Including phrases like "starts with," "transitions to," or "ends with" to guide narrative progression.
Style References: Specifying artistic influences like "in the style of Wes Anderson" or "like a nature documentary."
Technical Parameters: Including specifications for lighting, color grading, and visual effects.
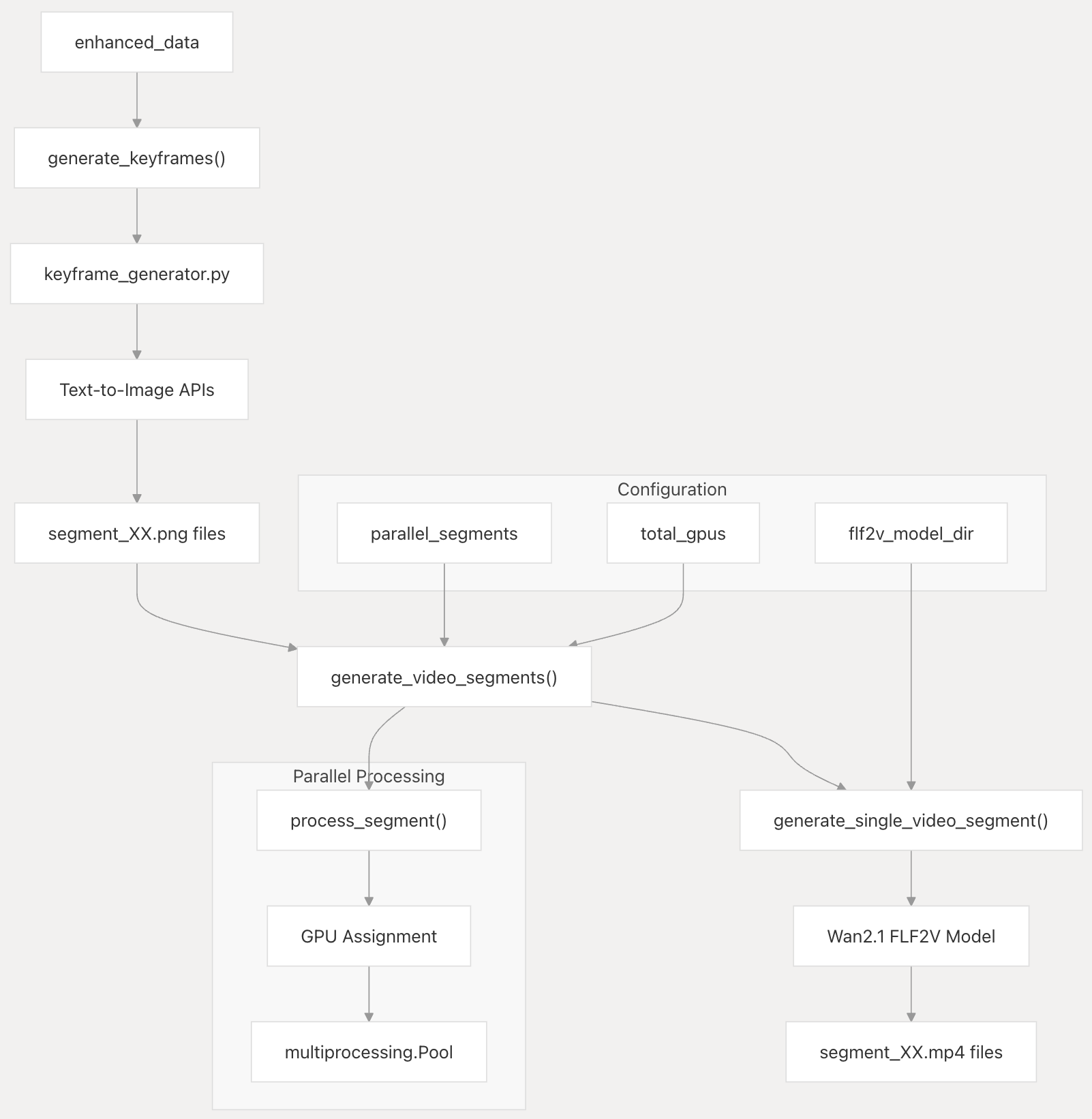
The ttv-pipeline: Automating Long-Form Video Generation
The ttv-pipeline represents a comprehensive open-source solution to these challenges, transforming manual workarounds into an automated, scalable system.

System Architecture
The pipeline implements a multi-stage approach:
1. Text Prompt Segmentation
Analyzes input prompts to determine optimal segment boundaries
Preserves narrative coherence while managing technical constraints
Automatically calculates the number of required 5-second segments
Applies specialized prompt engineering to construct new prompts for each segment
2. Dual Generation Mode Options
Keyframe Mode:
Generates static keyframe images for each segment's final frame
Creates video clips using first-frame and last-frame references
Enables parallel processing across multiple segments
Ideal for maintaining visual consistency across longer narratives
Chaining Mode:
Automatically extracts the last frame from each generated segment
Uses extracted frames as reference images for subsequent segments
Ensures frame-to-frame continuity without manual intervention
Sequential processing maintains temporal coherence

3. Flexible Parallelization and Scaling
The pipeline offers sophisticated resource management:
GPU Distribution: Spreads segment processing across multiple GPUs
Parallel Segment Processing: Simultaneous generation in keyframe mode
Cloud Scaling: Supports remote API usage for users without local GPU resources

4. Remote API Integration
Recent enhancements include support for cloud-based video generation:
Runway ML: Integration with Gen-4 Turbo model via API
MiniMax: Integration with MiniMax I2V-01-Director model via API
Google Veo 3: State-of-the-art generation on Google Cloud (currently in testing)
Seamless switching between local and cloud generation
Extensible video generator architecture with fallback support
5. Automated Assembly
Intelligently combines generated segments
Ensures smooth transitions between clips
Produces seamless final output without manual editing
Practical Impact
The ttv-pipeline addresses critical limitations in current text-to-video workflows:
Extended Duration: Enables creation of videos far beyond typical 5-10 second limits
Consistency Maintenance: Automated reference management preserves character and scene coherence
Resource Efficiency: Intelligent parallelization optimizes GPU utilization
Accessibility: Cloud API support democratizes access to high-quality generation
Automation: Eliminates manual UI operations for scalable production
Major Text-to-Video Models (mid-2025)
Note: there are numerous gallery examples available for these models showing their realism, high resolution, and otherwise good quality results. I chose to challenge these models with a technically difficult task involving complex geometric, mathematical, text, and multi-character action sequence. All models failed spectacularly, with Veo 3 approaching coherence. I include the results here in order to highlight the limitations in the current state of video generation instead of touting their prowess. Prepare to be underwhelmed.
Initial prompt (before processing):
Animated short, classic slapstick cat-and-mouse cartoon featuring Milo, an orange tabby cat, and Pip, a grey mouse, in 1940s cel-animation style with a vibrant palette. The scene begins in a classroom with a chalkboard reading "Fun with Fractions!" Milo writes "1/2 + 1/4 = ?" on the chalkboard. Pip wheels in a big round cheese. A chase ensues where Milo's swipe slices the cheese into two 1/2 pieces, and Pip's dodge cuts one half into four 1/4 pieces, with fraction labels appearing in mid-air. Milo slips on a 1/4 slice, sliding across the floor. Pip skateboards on a 1/4 slice down a ruler ramp. Milo pauses, holding a 1/2 slice, and Pip holds a 1/4 slice. They place their slices next to a chalkboard drawing showing 1/2 plus 1/4 equals 3/4. The scene ends with Milo and Pip high-fiving, with bold on-screen text "1/2 + 1/4 = 3/4!"
Closed-Source Commercial Models
OpenAI Sora
Company: OpenAI
Source Type: Closed Source
Deployment Method: API access (currently limited to ChatGPT Plus, Team, and Pro users; also available at sora.com)
Theoretical Approach: Diffusion transformer architecture using space-time patches; world modeling for object permanence and scene consistency
Key Features:
Generates videos up to 20 seconds long at 1080p resolution
Adept at realistic physics, object permanence, and world-state modeling.
Accepts multimodal inputs: text, image, and video
High scene complexity and temporal consistency.
High quality texture, realistic or surreal
Limitations:
Character consistency
Chaining clips is quite difficult through the web UI
Characters often blend into each other
Difficulty writing text
Challenges with prompt adherence
Luma Ray2
Company: Luma Labs
Source Type: Closed Source
Deployment Method: Web interface (Dream Machine and Ray2 platform)
Theoretical Approach: Large-scale multimodal transformer with diffusion; trained on extensive video data for realism.
Key Features:
Generates up to 10-second videos at 720p.
Supports text-to-video and image-to-video inputs, including first-last frame.
Advanced physical realism, smooth motion, and cinematic quality.
Strong style transfer, keyframe-based extension, and camera motion controls.
Limitations:
Very long wait times in queue for generation
(Only first segment generated)
Kling AI
Company: Kuaishou
Source Type: Closed Source
Deployment Method: Web interface and mobile app (Kwaiying/KwaiCut; primarily for invited testers).
Theoretical Approach: Hierarchical video diffusion with 3D spatiotemporal attention and VAE; diffusion transformer backbone.
Key Features:
Generates videos up to 2 minutes at 1080p and 30 fps (for select users).
Superior texture rendering, character animation, and high motion quality.
Supports multiple aspect ratios and multimodal references (text, image, video).
Enhanced lip-sync and facial/body control.
Support “AI Sound” generation (textural / background, not dialog)
Limitations:
Poor text abilities
(Only first 3 segments generated)
Hailuo MiniMax
Company: MiniMax
Source Type: Closed Source
Deployment Method: Web interface, API, and MCP server.
Theoretical Approach: Diffusion transformer with specialized models for character animation, camera control, and subject preservation.
Key Features:
Specializes in short, cinematic clips (typically 6–10 seconds).
Strong subject control using reference images; excels at character consistency.
Supports text-to-video and image-to-video workflows.
Rapid generation and easy integration with creative tools.
Limitations:
Long time for waiting and processing
Limited prompt adherence and character consistency
Runway Gen-4 Turbo
Company: Runway ML
Source Type: Closed Source
Deployment Method: Web interface, API
Theoretical Approach: Image-to-video diffusion with transformer-based architecture; enhanced motion and scene consistency.
Key Features:
Generates 5–10 second videos at 720p resolution (default).
Fastest model in Runway’s lineup: 10-second videos in about 30 seconds.
Strong character, object, and scene consistency across shots.
Advanced keyframe and motion brush controls for precise animation.
Cinematic results; supports multiple aspect ratios and camera controls.
Optimized for creative professionals and rapid iteration.
Google Veo 3
Company: Google DeepMind
Source Type: Closed Source
Deployment Methods: Available via Flow platform for Gemini Ultra subscribers, and restricted allowlist access through Vertex AI API.
Theoretical Approach: Multimodal transformer with diffusion; integrates language models for advanced prompt interpretation.
Key Features:
Generates videos up to 8 seconds at 720p (current public capabilities).
Synchronized audio: generates sounds, music, and speech with lip-syncing.
Exceptional compositional and prompt understanding.
Realistic physics, lifelike human features, and artifact-free output.
Scene scripting, directorial controls
Limitations:
Veo 3 currently does not support any of the following features:
“Extend video” (rumored to be coming soon)
Image-to-Video with audio
First-Last Frame to Video
Therefore, segments could be chained together but they will have limited character consistency.
Open-Source Models
Wan 2.1
Company/Creator: Alibaba (Qwen/Tongyi Lab)
Source Type: Open Source
Deployment Method: API and local installation; supports consumer-grade GPUs.
Theoretical Approach: Advanced spatio-temporal VAE with multi-stage motion refinement.
Key Features:
Largest open-source video model, with 14B parameters.
Supports text-to-video, image-to-video, and video editing tasks.
Superiority over OpenAI's Sora across various benchmarks
excels on the VBench Leaderboard in 16 different dimensions,
particularly subject consistency and motion smoothness.
Visual text generation (Chinese/English), strong motion diversity
VAE reconstructs video at 2.5 times the speed of HunYuanVideo
Tencent HunyuanVideo
Company/Creator: Tencent
Source Type: Open Source
Deployment Method: Local install, API, online platform (China phone required)
Theoretical Approach: Hybrid dual-to-single stream Transformer with 3D VAE compression and MLLM text encoder
Key Features:
13B parameter model
Generates up to 5.4s (129 frames) at 720p (1280×720); supports 540p/960p
Excellent text-video alignment, motion stability, and visual quality
competitive with top closed-source models
Strong Chinese-language and general prompt support
Handles facial speech, action, and shot transitions with ID consistency
Requires 45–80GB GPU VRAM for high-res generation
The above is a minute-long video created with HunyuanVideo model via FramePack, discussed later.
CogVideoX
Company/Creator: Tsinghua University/THUDM
Source Type: Open Source
Deployment Method: Local installation; ComfyUI integration.
Theoretical Approach: Diffusion transformer with 3D VAE compression and expert correction.
Key Features:
5B parameter model; generates 10-second videos at 768p, 16 fps.
Strong temporal coherence and text-video alignment.
Background image input for controlled generation.
Open-Sora
Company/Creator: Open-source community (HPC-AI Tech)
Source Type: Open Source
Deployment Method: Local installation; modular and extensible.
Theoretical Approach: Spatial-Temporal Diffusion Transformer (STDiT), aiming to replicate Sora’s approach.
Key Features:
Community-driven, modular, and actively improving.
Generates up to 15-second videos at 720p.
Focus on accessibility, documentation, and ecosystem growth.
Recent Innovations
FramePack

FramePack is a neural network architecture and software tool engineered to overcome the significant hurdles of scalability and quality degradation in long-form video generation, particularly with large diffusion models. It introduces an innovative method to compress the input frame context into a constant size (O(1) complexity), meaning the computational effort doesn't increase with the video's length. This is achieved through a specialized GPU memory layout and variable "patchifying kernels," allowing it to efficiently handle thousands of frames even on consumer-level hardware.
Furthermore, FramePack incorporates "FramePack Scheduling" for flexible context management and bi-directional "Anti-drifting Sampling" techniques. These features specifically target the common "drifting" problem (error accumulation) in next-frame prediction, significantly improving the coherence and quality of longer videos. This makes FramePack a practical solution for researchers and developers aiming to generate high-resolution, long-duration videos (including image-to-video) without requiring extensive computational resources, effectively democratizing access to advanced video generation capabilities.
CausVid

CausVid is an innovative video generation model designed to address the significant latency and lack of interactivity inherent in traditional bidirectional video diffusion models. Unlike its predecessors, which must process entire video sequences (including future frames) to generate a single frame, CausVid employs an autoregressive (causal) approach. This allows it to generate video frames sequentially, "on-the-fly," based only on past information, drastically reducing initial wait times and enabling real-time, streaming video generation.
The model achieves its speed and quality through several key technical contributions. It adapts a powerful pretrained bidirectional model into an autoregressive one and utilizes Distribution Matching Distillation (DMD), extended to video, to condense a many-step diffusion process into a few-step generator (e.g., 4 steps). A novel "asymmetric distillation" strategy, where the causal student learns from its bidirectional teacher, is crucial for maintaining high quality and preventing error accumulation, enabling the generation of long videos. Combined with efficient KV caching during inference, CausVid can generate video at impressive speeds (around 9.4 FPS) with minimal initial latency (1.3 seconds).
CausVid's significance lies in making high-quality, interactive video generation practical. It achieves state-of-the-art results on benchmarks like VBench-Long while being orders of magnitude faster than previous methods. Furthermore, it offers versatile zero-shot capabilities for tasks like video-to-video translation, image-to-video generation, and dynamic prompting, opening up new possibilities for dynamic content creation and interactive video applications.
Future Directions and Emerging Trends
Extended Duration: Research is rapidly advancing toward generating minutes-long coherent videos.
Interactive Editing: More granular control over generated content through intuitive interfaces.
Multi-Modal Integration: Combining text, image, audio, and video inputs for more precise generation.
Personalization: Fine-tuning models on specific characters or styles for consistent branded content.
Narrative Intelligence: Incorporating storytelling principles to create more engaging and coherent videos.
Ethical Frameworks: Developing robust safeguards against misuse and harmful content generation.
The Democratization of Video Creation
Text-to-video AI represents a fundamental shift in content creation, dramatically lowering barriers to producing high-quality video. As these technologies mature, we're witnessing the democratization of a medium that previously required significant technical skills, expensive equipment, and large teams.
The pace of advancement suggests that within the next year, text-to-video systems will approach professional production quality for many applications, transforming industries from marketing and education to entertainment and personal communication. At the same time, these technologies raise important questions about media authenticity, creative attribution, and the changing nature of visual storytelling.
For creators looking to harness these tools effectively, understanding the underlying principles, limitations, and techniques for optimal results will be crucial in navigating this rapidly evolving landscape. By combining technical knowledge with creative vision, users can push the boundaries of what's possible with these remarkable new tools.
References
Analytics India Magazine (2025). Alibaba Releases Open-Source Video Generation Model Wan 2.1, Outperforms OpenAI’s Sora
Ho, J., et al. (2022). Imagen Video: High Definition Video Generation with Diffusion Models
Singer, A., et al. (2024). Lumiere: A Space-Time Diffusion Model for Video Generation
Google DeepMind. (2024). Veo
Google Research. (2024). VideoPoet: A Large Language Model for Zero-Shot Video Generation
Ho, J., et al. (2022). Imagen Video: High Definition Video Generation with Diffusion Models
Meta AI. (2022). Make-A-Video
OpenAI. (2024). Sora
Peebles, W. and Xie, S. (2023). Scalable Diffusion Models with Transformers
Runway. (2024). Gen-4
Saito, M., et al. (2017). TGAN: Temporal Generative Adversarial Nets with Singular Value Clipping
Stability AI. (2023). Stable Video Diffusion
Tulyakov, S., et al. (2018). MoCoGAN: Decomposing Motion and Content for Video Generation
Yang., et al. (2024). CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer