Technical progress in AI moves through two intertwined streams. Science discovers new knowledge. Engineering operationalizes that knowledge into tools, systems, and products. A strong research literacy bridges both streams.
This article offers a practical framework for reading modern AI papers, evaluating claims, and converting insights into working systems. It draws on examples like DeepSeek V3 and R1 (cover article in Nature yesterday, 8 months later), and Kimi K2, yet the guidance applies broadly.
See the accompanying podcast episode to this article:
Two lenses: science and engineering
Science asks what is true about the world. It seeks hypotheses, controlled experiments, analysis, and inference.
Engineering asks what works at scale. It values constraints, interfaces, cost, reliability, and speed.
When reading a paper, switch lenses as needed. With the science lens, ask whether the reasoning and evidence support the claims. With the engineering lens, ask whether the idea survives constraints like latency budgets, memory footprints, and operational risk.
Anatomy of a modern AI paper
Scientific publications tend to mirror the structure and flow of the scientific process. Use this map to stay oriented.
Title, abstract, figure 1 Quick triage. What is the claim. What shifts if the claim holds.
Introduction Problem context and motivation. What prior gaps does this fill.
Method Architecture, training procedure, data, objective, and algorithmic details.
Experiments Datasets, metrics, baselines, ablations, and qualitative analysis.
Discussion Limitations, failure modes, and scope of applicability.
Conclusion and references Implications and pointers for deeper study.
Artifacts Code, weights, model cards, data statements, and license.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Helpful habit: open the PDF and the project page or model card at the same time. Jump between abstract, figures, and artifacts as you read.
A first‑pass reading workflow
Goal: decide if the paper deserves a deep dive and what to verify.
Read the abstract and highlight the primary claim.
Scan the first figure. Note where the novelty sits in the pipeline.
Check for released artifacts. Are weights, code, or evaluation scripts available.
Skim the method section headers to locate the core mechanism.
Skim the main tables. Circle bold numbers to spot where the model leads or lags.
Skim limitations and future work. Note what the authors say the method cannot do yet.
Decide on an action: reproduce a small result, try the released weights, or park it.
This pass can take 10 to 20 minutes and filters the reading queue effectively.
Reproducibility and open artifacts
Reproducibility gives findings a life outside the originating lab. In practice:
Weights enable independent evaluation and product trials.
Code and scripts enable fair comparisons and ablations.
Model cards and data statements document scope, risks, and training signals.
When artifacts are partial, adapt expectations. You can still test claims through API access or compatible checkpoints, but record the gap.
Evidence ladder for claims
Paper only
Paper plus partial code or eval scripts
Paper plus weights and scripts that reproduce headline tables
Independent replication by a different group
Deployment evidence under realistic load and guardrails
Push up the ladder when possible.
Pretraining and post‑training in LLMs
Most recent LLM work fits into a two‑stage picture.
Pretraining builds general language competence. Objective signals include next‑token prediction or masked modeling. Design choices include dense vs Mixture of Experts, context length, tokenizer, and optimizer.
DeepSeek-V3 Technical Report
Post‑training aligns the model to instructions, tools, or reasoning styles. Common routes include supervised fine‑tuning on instruction data, direct preference optimization, and reinforcement learning from preferences or rewards. Variants like PPO, GRPO, and DPO differ in how they model feedback and update policies. Recent innovations include DAPO and GSPO
DeepSeek-V3 Technical Report
Reading tip: when a paper reports a leap in reasoning, track where that leap originates. Is it from the base model, the post‑training recipe, the reward model, the curation strategy, or inference‑time search. Each lever matters for application.
Benchmarks, reliability, and practical relevance
Benchmarks are a means, not an end. Use them wisely.
Pass@1 vs Pass@k Pass@1 measures first‑attempt success. Pass@k allows several attempts and credits any success. For production, prioritize Pass@1 and stability under distribution shifts.
Look for missing baselines Check which strong peers are absent. A fair picture considers models of similar size and release vintage.
Scan boldface Tables often bold the best numbers per row. Skim for patterns, then read the fine print.
Reliability over demos A one‑off success does not equal an operational win. Seek evidence for repeatability, tail behavior, and failure modes.
When an idea looks promising, define an application‑specific metric and test on your own workload.
Ablation studies: causal credit assignment
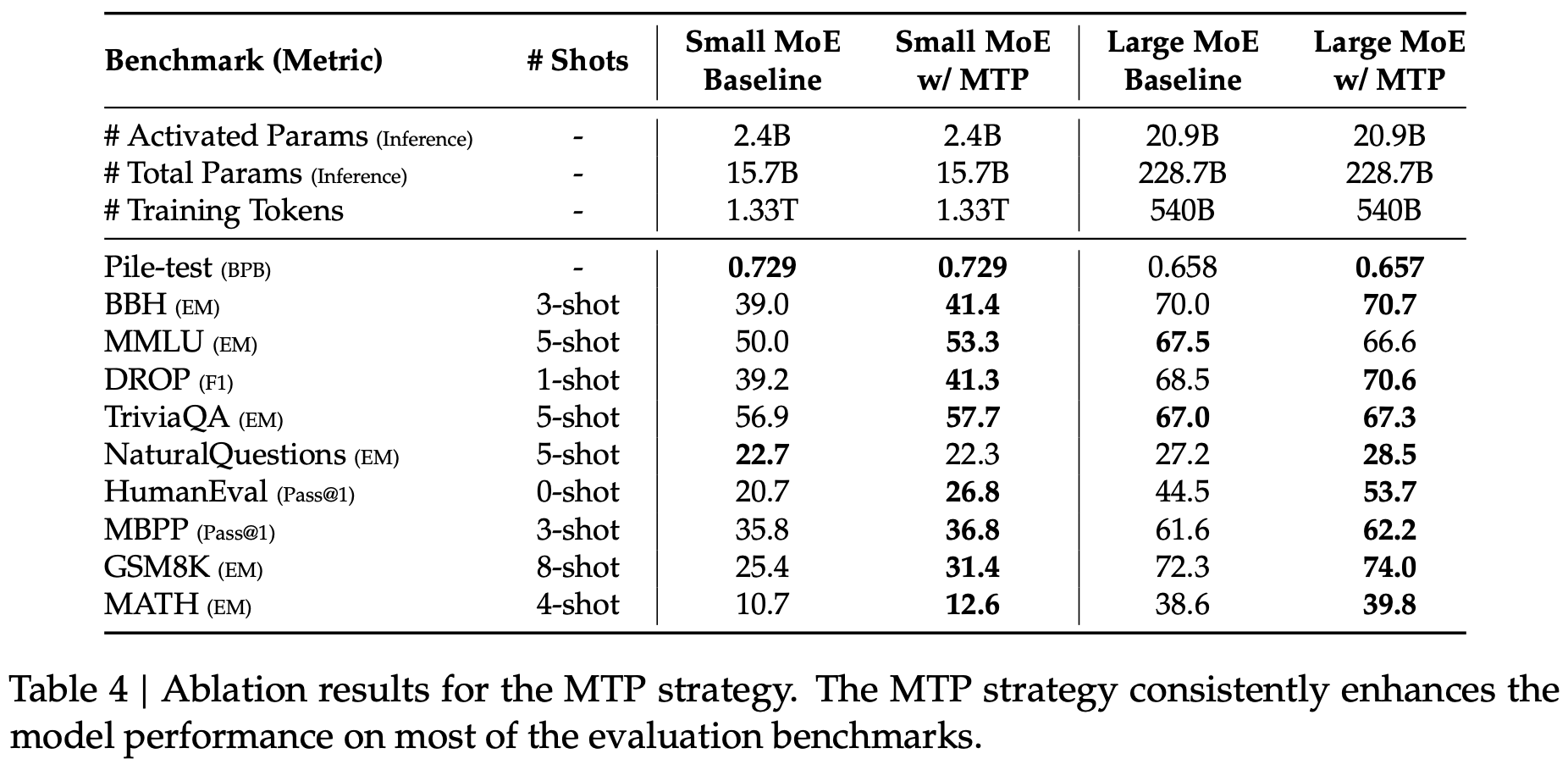
Ablations test the contribution of a component by removing or replacing it. Good ablations control for confounders such as compute budget and data size.
DeepSeek-V3 Technical Report
Checklist for reading ablations:
Is there a clear baseline that matches all else.
Are multiple random seeds reported for stability.
Are effects consistent across several tasks, not only one.
Do the deltas track the stated intuition.
Architecture and training notes
A few recurring ideas appear across recent LLMs.
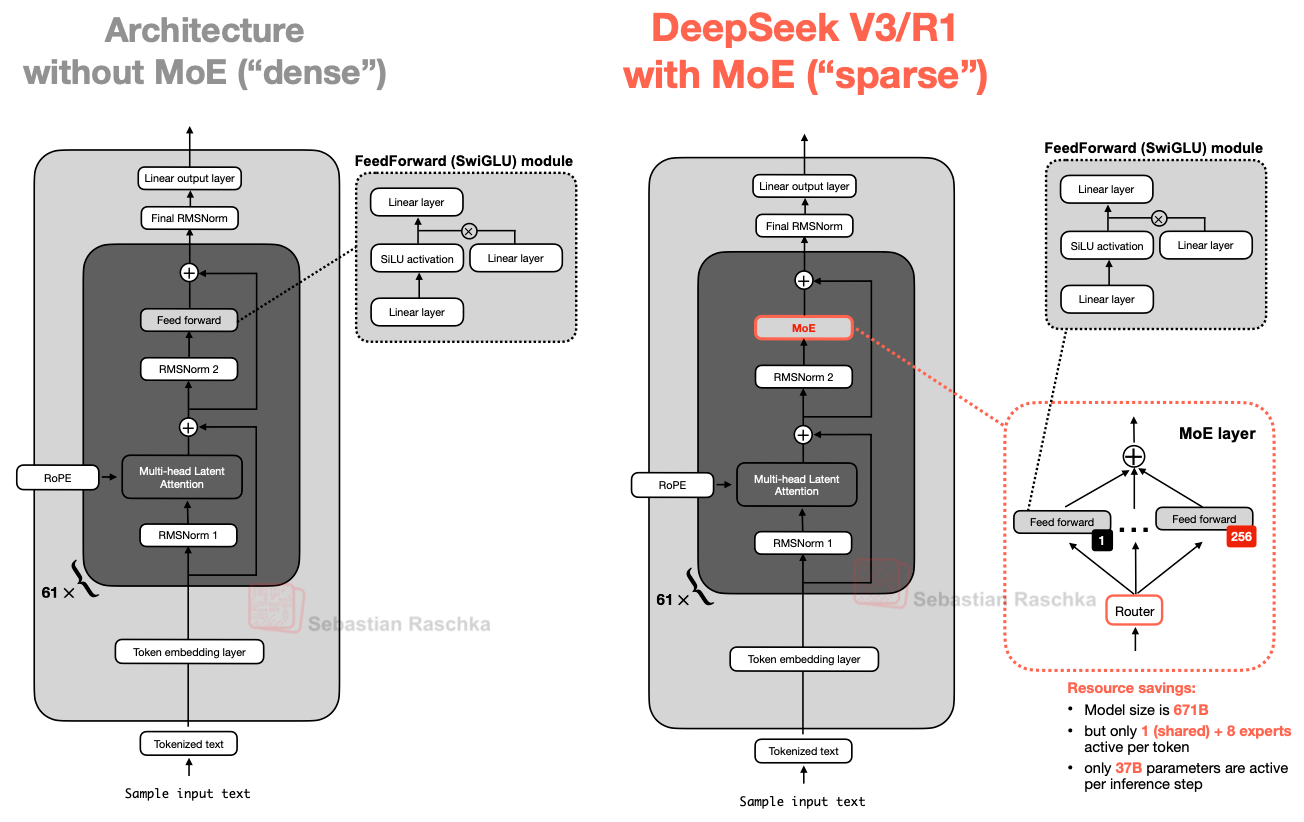
Mixture of Experts Many experts exist, only a few are active per token. Memory still holds the whole model, compute scales with active experts per step. This trade can deliver higher throughput at inference.
The Big LLM Architecture Comparison by Sebastian Raschka
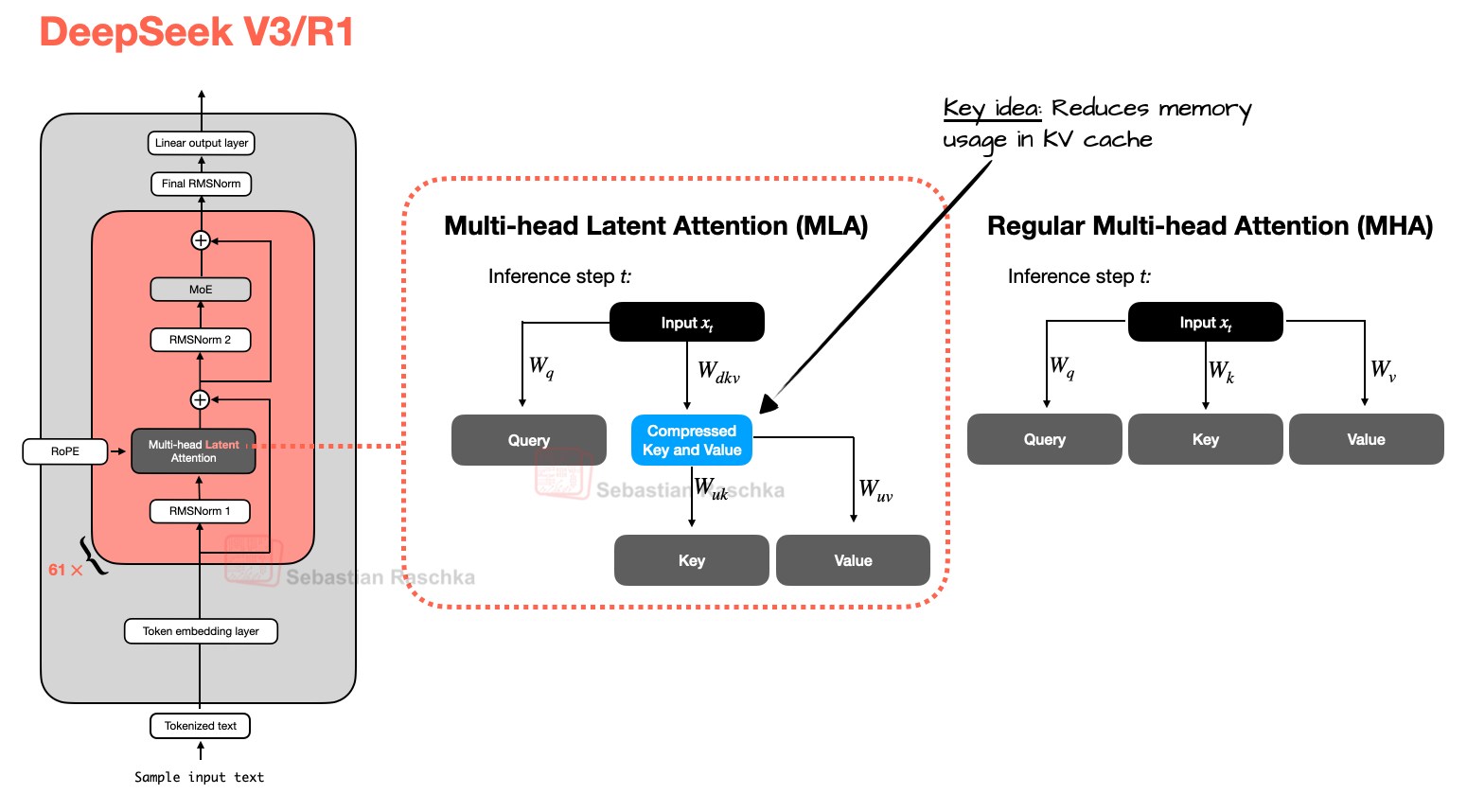
KV cache Attention layers cache keys and values to avoid recomputing past tokens. Efficient KV compression or reuse increases context length and reduces memory bandwidth.
The Big LLM Architecture Comparison by Sebastian Raschka
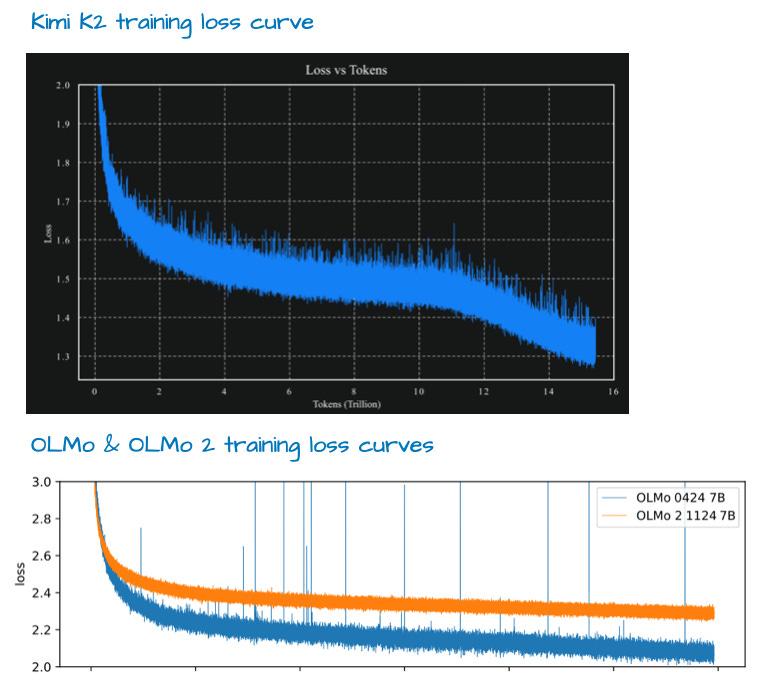
Training curves Smooth, monotonic curves suggest a stable recipe and consistent data curriculum. Spikes can flag optimizer instabilities or data issues. Read curves before tables.
The Big LLM Architecture Comparison by Sebastian Raschka
Case study patterns
These patterns help decode families of papers without memorizing details.
Base model plus post‑training A strong base model with a transparent post‑training recipe often transfers well. Track the data mixture, objective choice, and reward model.
Optimizer or stabilization focus Papers that introduce an optimizer variant or clipping recipe often target training stability and faster convergence. Inspect training curves and long‑context behavior.
Agentic evaluation When claims involve tool use or multi‑step reasoning, look for evaluations that include tool latency, tool accuracy, and end‑to‑end task success.
From paper to practice: a 3‑step adoption loop
Step 1. Verify a minimal claim Recreate a small table entry or a single plot with the provided weights or scripts. Use the same decoding, temperature, and prompt template.
Step 2. Test on your workload Design a compact evaluation set that captures your domain. Track Pass@1, cost per million tokens, latency percentiles, and safety guardrails. Run A vs B with the same budget.
Step 3. Integrate behind a feature flag Put the model behind a toggle. Collect telemetry on success, retries, timeouts, and refusal rates. Promote gradually.
This loop converts reading time into business value while preserving scientific rigor.
A note‑taking template you can reuse
Copy this into your notes for each paper.
Paper: title, venue, date, link to PDF and artifacts
Risks and limits: what the authors state, what you observe
Adoption plan: minimal verification, domain eval, feature flag plan
Open questions: for the author or your team
Reading critically in public
Scientific discourse thrives on shared norms.
Ask questions that target claims and evidence.
Cite clearly and credit artifacts.
Separate critique of methods from critique of people.
Share counter‑results with enough detail for others to reproduce.
Respect confidentiality boundaries when engaging with speakers from commercial labs. Focus the discussion on public methods and open releases.
Quick reference checklist
Identify the claim and where it sits in the pipeline.
Confirm what artifacts exist and what they allow you to test.
Prefer Pass@1 and reliability when planning adoption.
Read ablations for causal credit and portability.
Look for omissions in baselines and report dates.
Redraw the architecture and training loop to internalize it.
Move from paper to workload as much as possible.
Closing
Strong research literacy pays twice. It helps evaluate truth with care, and it helps ship systems that work under real constraints. Read with a scientist’s curiosity and an engineer’s pragmatism, and keep a bias toward small replications that climb the evidence ladder.
This is my first time reading LLM papers, and I like how it pushes me to explore new concepts. My habit has been to list all the unknown terms while reading, then study them separately before coming back to the paper. That way I can follow the main ideas first, and then go deeper into the technical side. Do you have any advice for beginners on balancing this cycle of ‘read, research, reread’ without getting overwhelmed or losing the flow?
Thanks for the article. I used it to analyze the DeepSeek-R1 paper, which presents a fascinating case study in LLM training. From it, I would like to highlight two key ideas:
The first, and perhaps most striking, is the concept of the "aha moment." This aligns perfectly with my experience as a mathematician and researcher: the Eureka moment that follows extended periods of contemplation and exploration. In the context of DeepSeek's training, this wasn't an explicitly programmed feature but an emergent capability. The model, through pure reinforcement learning without prior supervised fine-tuning, spontaneously learned to allocate more compute for challenging tasks and to self-reflect on its chain of thought. This demonstrates that RL, when applied at scale, can encourage models to develop sophisticated, meta-cognitive abilities. It suggests that the "thinking" process we value in human intelligence might not need to be hardcoded, but rather can emerge as a behavior that is incentivized and optimized for.
The second idea is distillation, which raises an important point about the transfer of knowledge. It is truly a marvel of engineering that we can leverage a massive, resource-intensive teacher model to train a more efficient student. However, distillation is not just about transferring knowledge; it is about transferring the teacher's entire probability distribution, including its inherent biases and limitations. The very "dark knowledge" that makes distillation so effective at preserving performance is also what makes it a potential vector for propagating harmful biases.
Through distillation, we could train other models so that they learn how to reason better, but we must remain vigilant about whether we are also teaching them harmful biases and adding limitations.






This is my first time reading LLM papers, and I like how it pushes me to explore new concepts. My habit has been to list all the unknown terms while reading, then study them separately before coming back to the paper. That way I can follow the main ideas first, and then go deeper into the technical side. Do you have any advice for beginners on balancing this cycle of ‘read, research, reread’ without getting overwhelmed or losing the flow?
Thanks for the article. I used it to analyze the DeepSeek-R1 paper, which presents a fascinating case study in LLM training. From it, I would like to highlight two key ideas:
The first, and perhaps most striking, is the concept of the "aha moment." This aligns perfectly with my experience as a mathematician and researcher: the Eureka moment that follows extended periods of contemplation and exploration. In the context of DeepSeek's training, this wasn't an explicitly programmed feature but an emergent capability. The model, through pure reinforcement learning without prior supervised fine-tuning, spontaneously learned to allocate more compute for challenging tasks and to self-reflect on its chain of thought. This demonstrates that RL, when applied at scale, can encourage models to develop sophisticated, meta-cognitive abilities. It suggests that the "thinking" process we value in human intelligence might not need to be hardcoded, but rather can emerge as a behavior that is incentivized and optimized for.
The second idea is distillation, which raises an important point about the transfer of knowledge. It is truly a marvel of engineering that we can leverage a massive, resource-intensive teacher model to train a more efficient student. However, distillation is not just about transferring knowledge; it is about transferring the teacher's entire probability distribution, including its inherent biases and limitations. The very "dark knowledge" that makes distillation so effective at preserving performance is also what makes it a potential vector for propagating harmful biases.
Through distillation, we could train other models so that they learn how to reason better, but we must remain vigilant about whether we are also teaching them harmful biases and adding limitations.