

Qwen 3 Redefines Open‑Source AI Power
Meet the Three Musketeers of coding, reasoning, and instruction

Alibaba's Qwen team just dropped a bomb on the AI world, and the shockwaves are still rattling the servers. They released a trio of new Qwen3 models that are a strategic realignment of the entire AI landscape. We're talking about open-source models that go toe-to-toe with the big proprietary players, and they're doing it on the cheap.
Let's break down what they unleashed and why it matters.

The Three Musketeers of Qwen3
Alibaba didn't just release one model; they dropped a specialized crew for different jobs:
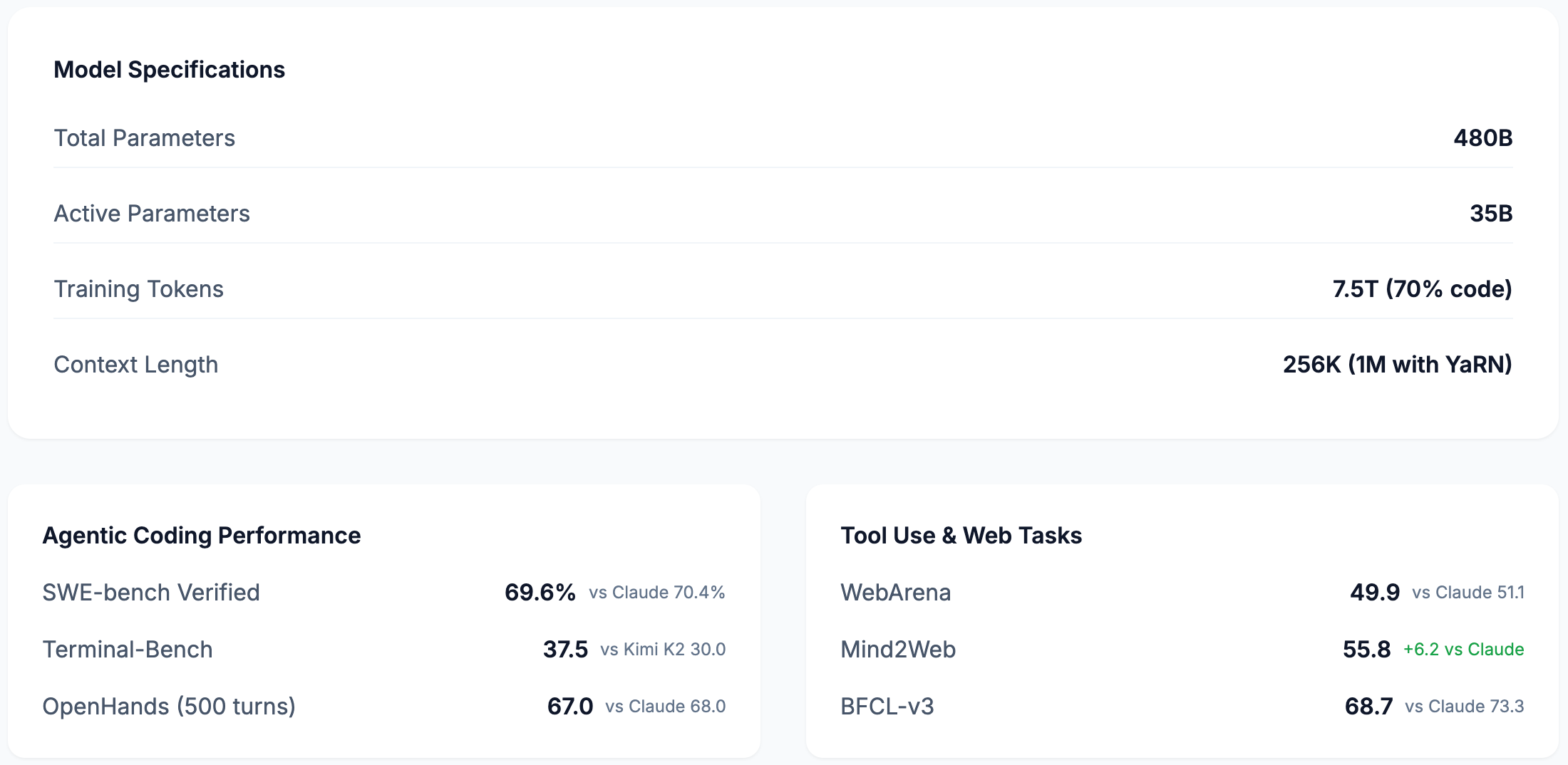
Qwen3-Coder-480B-A35B-Instruct: The heavyweight coding specialist. It's a massive 480-billion parameter model trained on a diet of 70% code.

Qwen3-235B-A22B-Thinking-2507: The deep thinker. This one is built for complex, step-by-step reasoning. It literally outputs its thought process in
<think>tags so you can see how it got to the answer.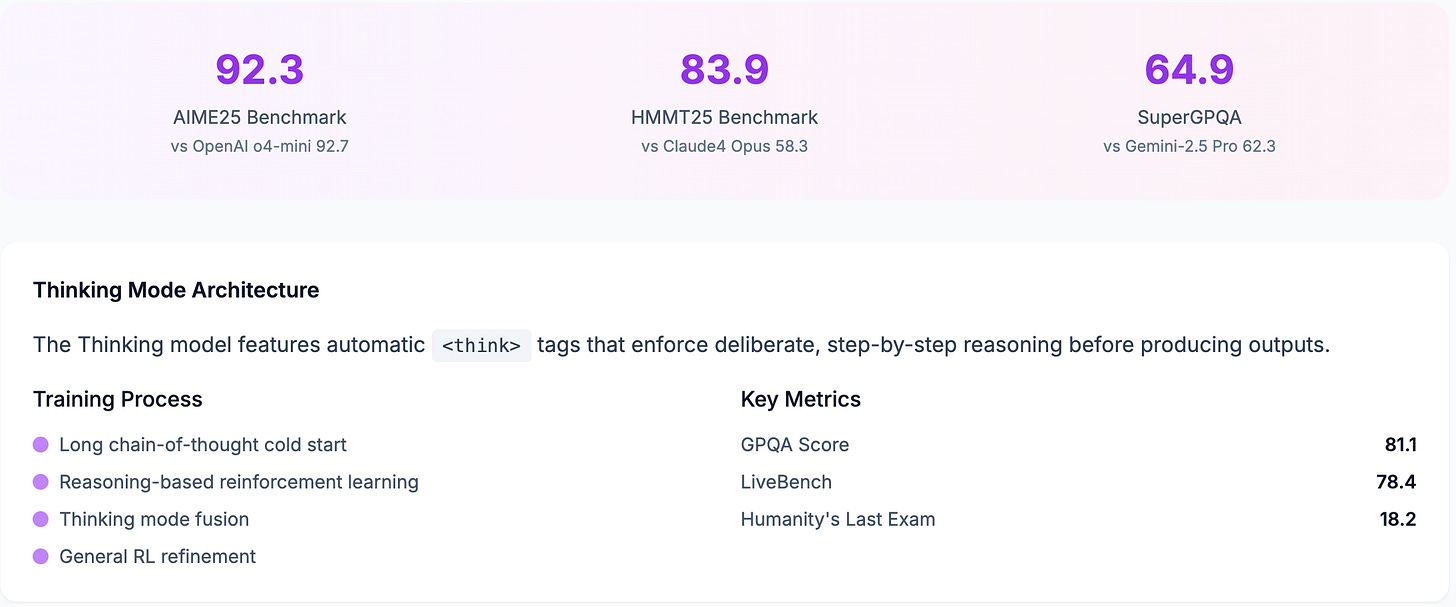
Qwen3-235B-A22B-Instruct-2507: The fast-talking generalist. It's built for quick, direct answers without the pensive deliberation of its sibling.



The Tech Guts: What Makes Them Tick
The real magic here is under the hood. The Qwen team made some smart architectural choices that have massive implications.
Mixture-of-Experts (MoE) on a Diet: All three models use an MoE architecture. Think of it like a massive library with hundreds of specialist librarians. When you ask a question, only the relevant experts (8 of them, in this case) get involved. So, while Qwen3-Coder has 480 billion parameters in total, it only uses about 35 billion for any single task. The 235B models only activate 22 billion. This means you get the knowledge of a huge model with the inference cost of a much smaller one. It's a massive efficiency win.


A Context Window That Swallows Repositories: All these models have a native context window of 262,144 tokens. And with a technique called YaRN, the Coder model can stretch that to a cool 1 million tokens. It can practically ingest your entire codebase in one go, which is a huge deal for complex software tasks.


Splitting Personalities (On Purpose): The move to create separate Thinking and Instruct models is genius. Instead of a clunky toggle, you pick the right tool for the job. Need a quick answer? Use Instruct. Need to solve a complex math problem? Unleash the Thinker.
Multilingual Training Data: The model was trained on a vast 119 languages, with a major focus on non-Latin scripts and code-switching. So when your users start mixing languages mid-sentence, the model can adapt. This makes it ready for prime time in global markets, and its translation skills are top-tier.


The Smackdown: How They Stack Up
Okay, so the tech is neat. But can they fight? Oh yeah.
Qwen3-Coder vs. The World: This thing is a beast. On the SWE-Bench Verified benchmark, a tough test of real-world software engineering, it scored 69.6%. That's right up there with Claude Sonnet 4 (70.4%) and leaves many others in the dust. It's an open model performing at the proprietary frontier.
Qwen3-Instruct, The All-Rounder: The generalist model holds its own, too. On knowledge benchmarks like MMLU-Pro, it scores 83.0%, beating GPT-4o's 81.1%. It proves you don't need to sacrifice general smarts for speed.
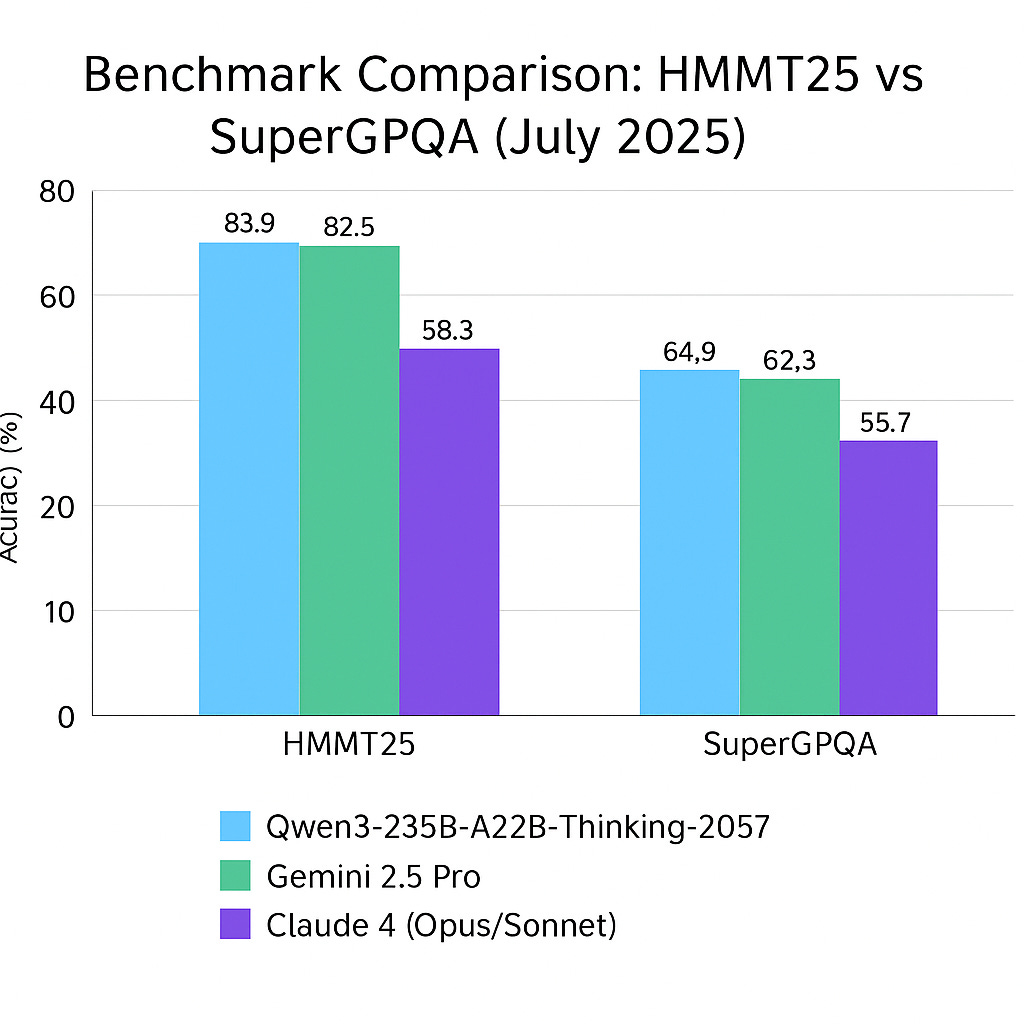
Qwen3-Thinking, The Mathlete: This model is acing tests that make other AIs sweat. On the AIME25 math and logic exam, it scored 92.3, essentially tying with OpenAI's o4-mini (92.7) and beating Gemini-2.5 Pro (88.0). It's the open-source math nerd we've been waiting for. There are another couple of important benchmarks (SuperGPQA and HMMT25) where this Qwen model beats Gemini 2.5 Pro and Claude 4 Opus & Sonnet. I’ll call them out here so we can compare the pricing between these models next:
The Price Tag: This Changes Everything
Here's where it gets wild. All these models are released under the Apache 2.0 license. That means they're free for commercial use. No licensing fees, no vendor lock-in. You can download them and run them on your own iron.
Thanks to the MoE architecture and INT4 quantization, you can run the 235B models on a machine with less than 60GB of VRAM. You don't need a national supercomputer anymore.
Now if you want to use them via an API, the pricing is just insane. Here are the rates from OpenRouter:
Qwen3-Thinking: $0.118 per million tokens (input AND output!)
Qwen3-Coder: $0.30 / $1.20 per million tokens (input/output)
Qwen3-Instruct: $0.12 / $0.59 per million tokens (input/output)
These prices are dirt cheap. We're talking 0.15% to 1% of the cost of the big proprietary players. It's hard to appreciate the price difference for API-based inference just reading the numbers, so here is a bar chart:
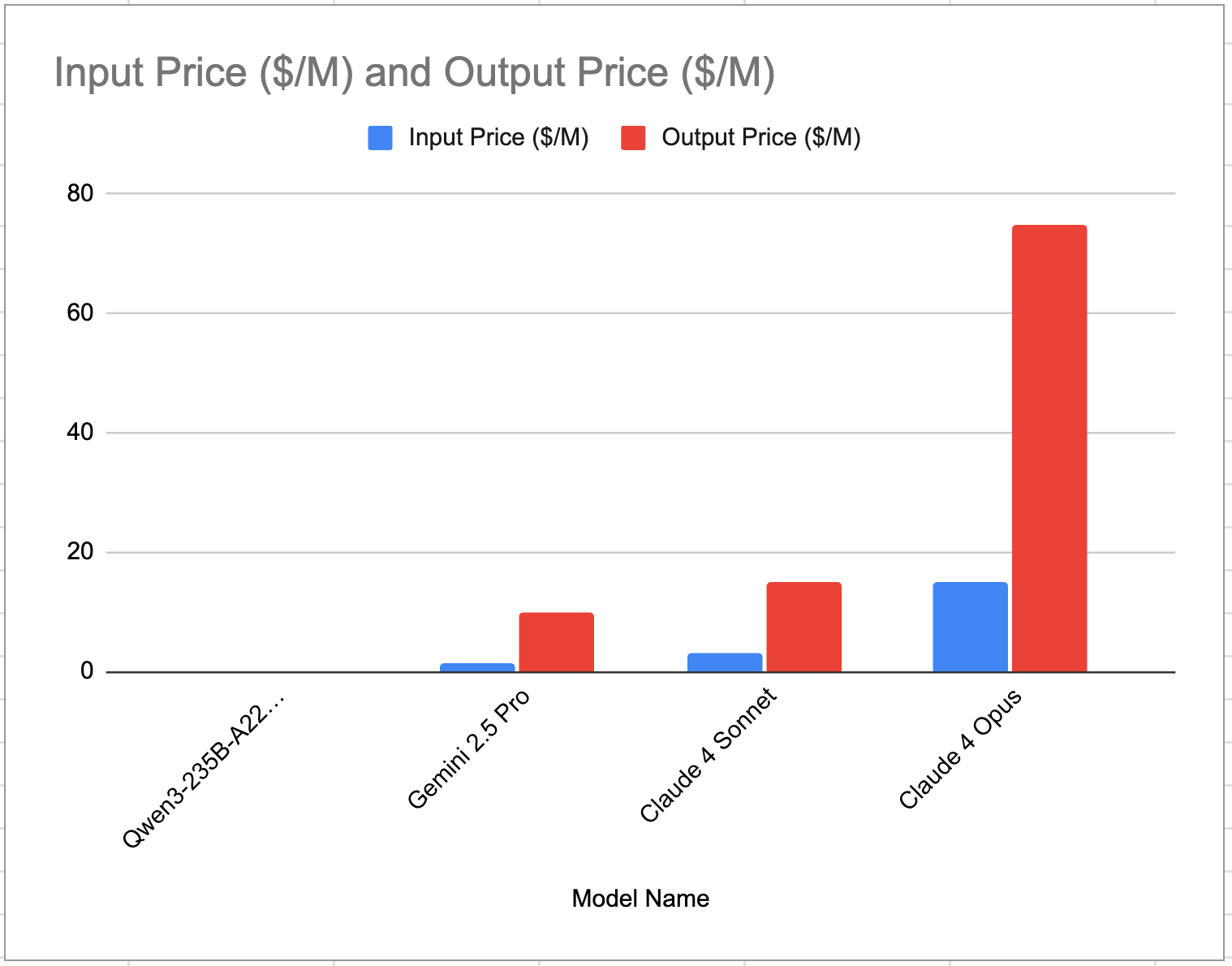
That's right: the Qwen3-235B-A22B-Thinking-2507 model (the one beating these other models in the previous bar chart) is so cheap, the price is practically zero! Let's remove Claude 4 Opus since its outrageous pricing is throwing off our y-axis:
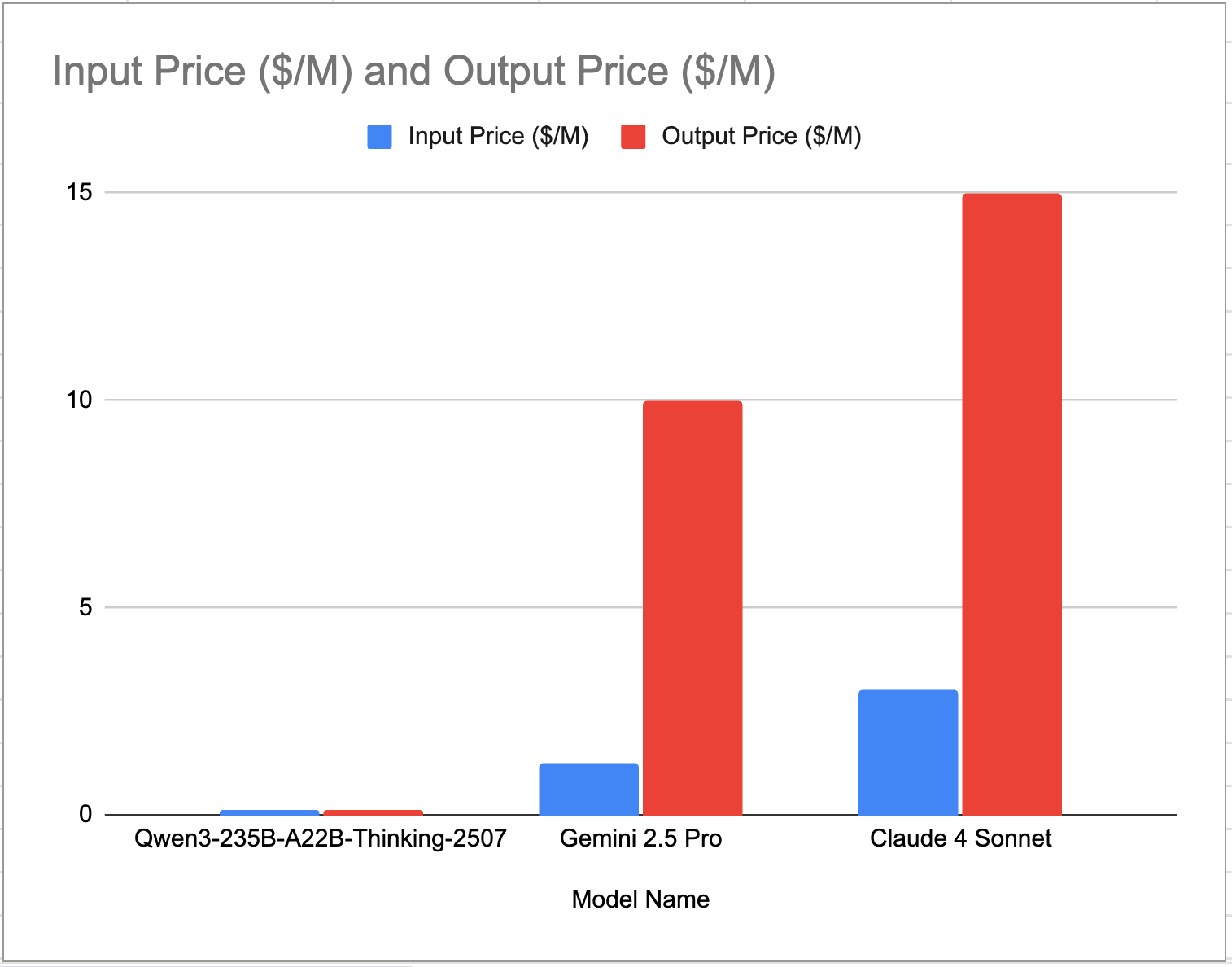
It's still almost invisible. Now do you understand the economic impact?
The Aftermath: A Geopolitical Power Play
Beyond just code and benchmarks, this is a geopolitical move. For years, the US has dominated frontier AI. China's response wasn't to build a better walled garden, but to kick the doors open for everyone.
By releasing these powerful models as open source, Alibaba is:
Bypassing Tech Restrictions: You can't put export controls on a model that anyone can download from Hugging Face.
Building Global Influence: Developers and companies worldwide, especially in emerging markets, now have access to top-tier AI. They'll build ecosystems around Qwen, creating soft power and dependence.
Forcing the West's Hand: Proprietary AI companies now have to justify their sky-high prices when an open model is performing this well for pennies on the dollar.
The revolution that DeepSeek R1 started, and Kimi K2 continued is now coming to head with Qwen 3. The game has officially changed. Open source is no longer just playing catch-up. It's at the front, setting the pace and rewriting the rules of the AI race. Your move, Silicon Valley.