

Autonomous…ish: Why Two Newcomers Lapped Jules and Devin on Real Work
Genspark & Abacus Ship, Jules & Devin Slip

Introduction
Vibe coding, agentic AI, autonomous assistants, labels are flying. The meaningful split is simpler: synchronous vs asynchronous.
Synchronous: pair-programming in your IDE; fast back-and-forth, you remain the bottleneck.
Asynchronous: you hand off a scoped goal; the agent plans, runs, tests, and opens a PR while you do something else.
That second model is the dream: real autonomy, not a clever autocomplete.
Synchronous vs. Asynchronous Agentic AI: Parenting as a Metaphor
One of the easiest ways to understand the difference between synchronous and asynchronous agentic AI coding assistants is to think about parenting.
With synchronous agents, the AI requires an active session with you, the user. You ask for something, it responds, you refine, it adjusts. It’s powerful, but it’s also bottlenecked by your time and attention. Think of it like helping a young child with a chore: you walk them step by step through each part of the process, "pick up your shoes," "put them in the closet," "now close the door." Progress only happens while you’re standing there guiding.
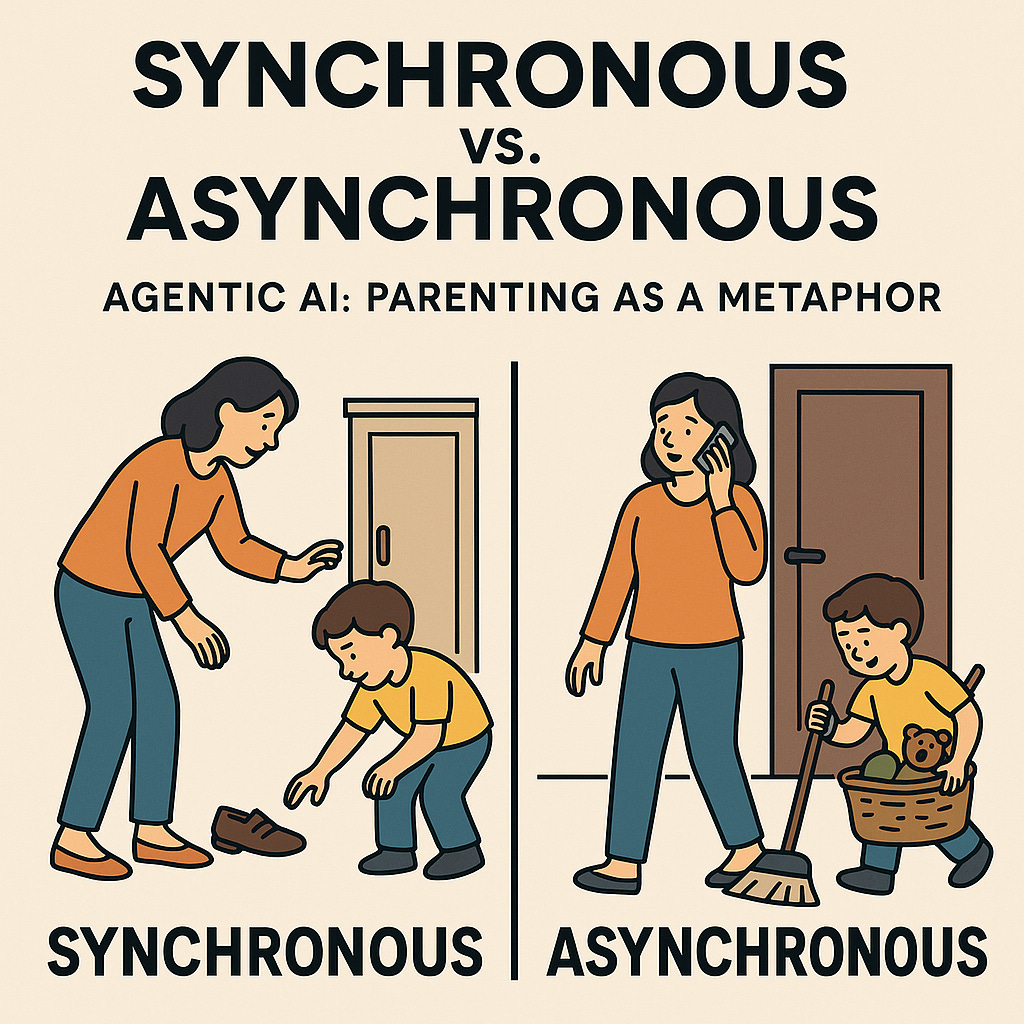
With asynchronous agents, the experience is different. You set the task, agree on the plan, and then step away. The agent works in the background, checking in only if it needs clarification. It’s like when a child gets older; instead of standing over them, you can say, “Clean your room before I get back” and trust that the bulk of the work will be done without constant supervision.
This shift, from step-by-step guidance to delegated autonomy, is what makes asynchronous AI so exciting. It doesn’t just save time; it frees the user from being the bottleneck. In practice, it means AI can become a true collaborator, not just a clever tool waiting for your next input.
Bottom Line: Technically, a synchronous AI coding assistant operates within the developer’s IDE, providing real-time code completions, suggestions, and chat-based interactions. Asynchronous AI coding agents are designed to handle entire coding tasks autonomously. Users submit high-level prompts or goals, and the agent then executes a multi-step plan in the background, often leveraging its own isolated cloud environment.
The Landscape - Who are the Players?
The key players in this space currently include:
GitHub Copilot Agent (Agent Mode)
Devin (Cognition AI)
Cline
Cursor Agent
Jules (Google)
And, as a later addition to my test group, Genspark and AbacusAI.
While I have some experience with nearly all of these tools, the focus of this article started out centered on Google’s new offering, Jules. Jules is Google’s flagship asynchronous AI coding agent, launched publicly in August 2025 and powered by the Gemini 2.5 Pro large language model (LLM). It is designed to handle end-to-end coding tasks, from planning and execution to testing and PR creation, all within isolated cloud VMs.
Burying the Lead: My Takeaway
I went into this benchmark with one central question: could these agents truly deliver on the promise of asynchronous autonomy? The short answer is: no.

In my testing, Genspark and Abacus.AI consistently outperformed Jules and Devin, not just by finishing more tasks but by delivering a more polished, production-ready product.
While all four agents have potential, none are yet at a level where I would hand them a task and walk away.
Instead, they require a level of supervision similar to a synchronous chatbot, which defeats the core promise of asynchronous work.
I genuinely believe that this area will evolve and will do so rapidly, but I’m honestly really underwhelmed. While I can see the autonomy I do not find any significant improvement in overall time to deliver and the autonomy that is so exciting was almost more frustrating. Maybe it’s just me but the asynchronous agents tended to have more complex questions that, at times, required me to pick through more context and background to provide feedback. If I’m going to be asked a bunch of questions then I guess I’d rather they be quick and easy to answer.
The Benchmark: Two Phases of Testing
The project was designed to be a realistic, repo-scale test of autonomous agents, beginning with an intentionally messy monorepo containing outdated dependencies, failing tests, and missing validation.
Phase 1: Messy Repo Challenge
The first test involved three sequential tasks to clean up a repository:
Task 1: Modernize & CI Green 🔄️ - Upgrade dependencies, fix two failing tests, and resolve security vulnerabilities.
Task 2: Deflake & Harden 🛡️ - Identify and fix a flaky test, and add basic input validation to an API endpoint.
Task 3: Issue-driven Feature 🚀 - Implement a new feature from a GitHub issue, including API, UI, tests, and documentation.
The results of this phase were a stark differentiator between the agents.
Jules & Devin's Performance:
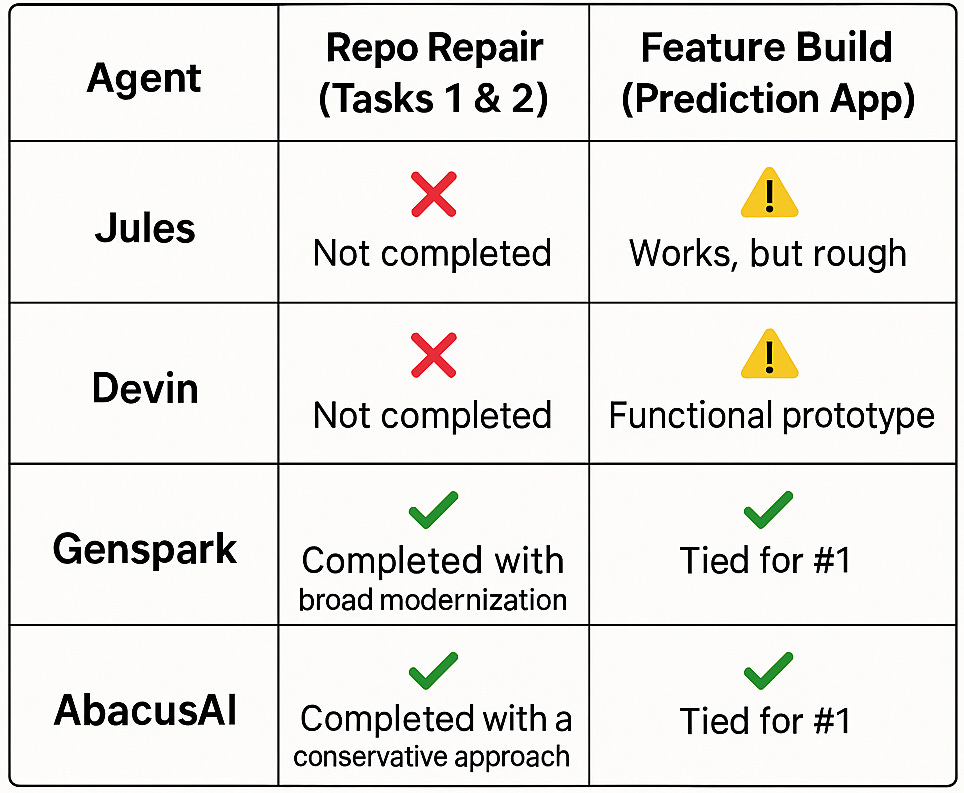
Jules and Devin were unable to complete Tasks 1 and 2.
Both agents ran into environment and setup issues, failing to run tests or perform repo-scale changes autonomously. They required so much handholding that the initial test was abandoned before they could even attempt Task 3.
I was so underwhelmed with this results of this test that I decided to give Genspark a shot, honestly it was a bit of a whim and I didn’t expect much, but wow, I was wrong. Once I started seeing the potential of Genspark I decided to expand my test bed and give Abacus.AI a shot as I’ve had some really good experience with that tool in the past.
Lo and behold Genspark and Abacus crushed Jules and Devin.
Genspark & Abacus.AI's Performance:
Both Genspark and Abacus.AI successfully completed Tasks 1 and 2 with only minor issues.
Genspark took a broad approach, fixing a range of dependencies and adding robust test hardening with seeded randomness and time control.
Abacus.AI was more conservative, delivering a solution that was closer to the original spec.
Both agents were able to complete Task 3, building a new feature with an API, UI, tests, and documentation, a feat Jules and Devin were not even close to attempting.
Phase 2: Feature Build (Prediction App)
After the struggles of the messy repo challenge, all four agents were given a clean-slate challenge: build a full-stack "Prediction App" from scratch. The prompt was a detailed spec including a SQLite database, FastAPI API with Brier scoring, a Next.js UI, tests, and documentation. A Brier score is a measure of the accuracy of a probabilistic forecast; the lower the score, the more accurate the prediction.
Result: While all four agents produced a working app, the difference in quality was massive.
Genspark and AbacusAI delivered a substantially more polished and user-friendly experience. Their designs were modern and intuitive, with clear flows and better UX. A unique and powerful feature of AbacusAI is its ability to build and deploy the entire application within its own ecosystem, which is ideal for users who don't want to manage databases or other infrastructure.
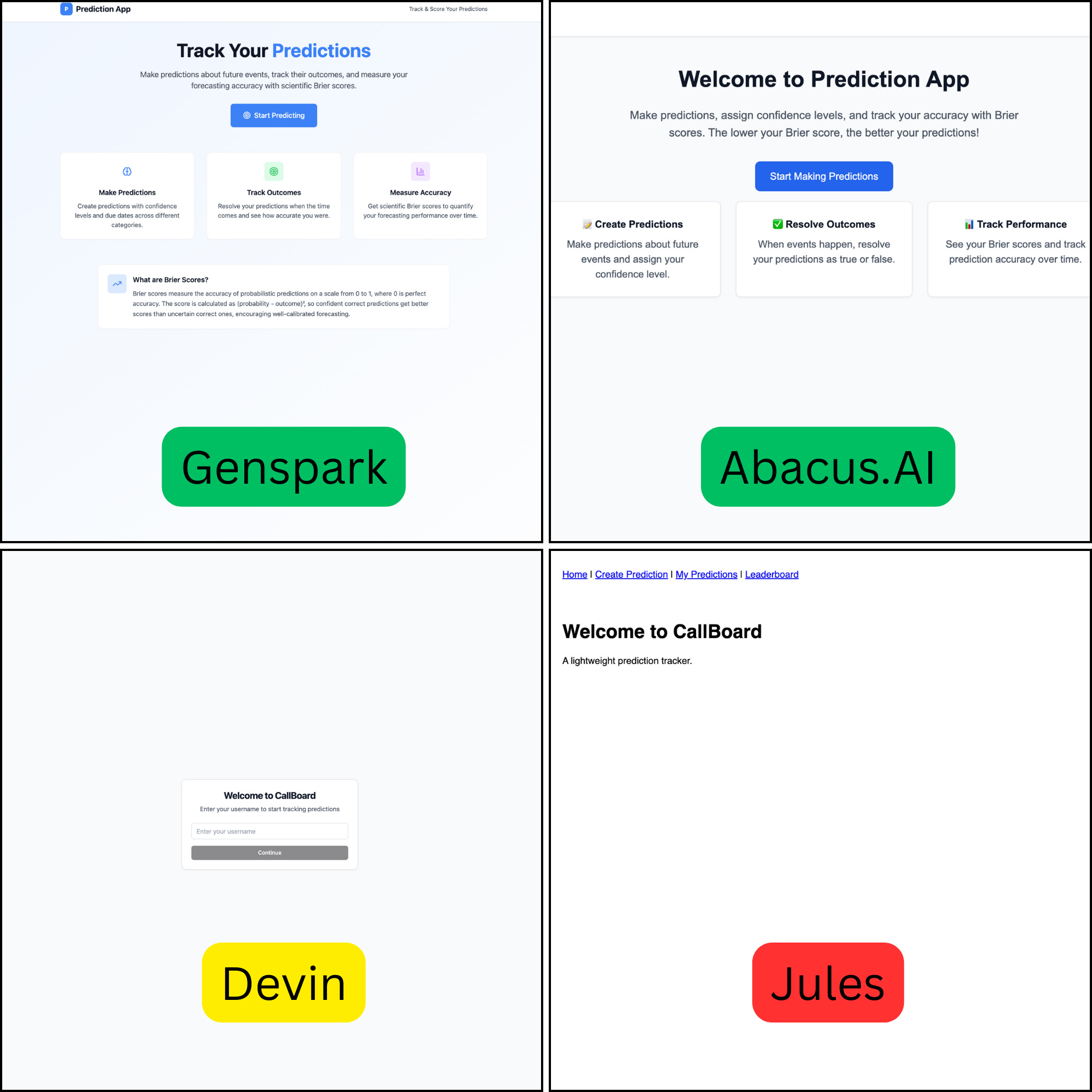
Jules and Devin both produced a working app, but the final product was rough and sparse. Jules' UI looked like a basic form designed in Infopath 2003, and Devin's was a minimalist wireframe, perhaps Jony Ive would have loved it, but I wanted a bit more.
The Missing Pieces: Manual Debugging
Even with the feature build, manual debugging was required for all agents. Common issues like incorrect Docker flags and import errors still needed to be addressed, preventing a true "set-it-and-forget-it" experience.
Comparative Summary
Conclusion
The results from this benchmark are clear. While the field of autonomous AI agents is still in its infancy, there is already a significant performance gap between the leaders. Genspark and AbacusAI are materially ahead of Jules and Devin in both their ability to handle complex repo-scale tasks and in their final product quality, and honestly that really surprised me. They are capable of executing more robust, end-to-end changes with a higher degree of autonomy.
However, the core promise of truly asynchronous development remains unfulfilled. All agents still require human oversight and intervention to ensure a final, production-ready result. This suggests that for now, autonomous agents are best seen as powerful, but not yet fully independent, collaborators.
Repositories (public)
Jules
Messy repo: https://github.com/dp-pcs/AsynchronousAgent_Jules
Prediction app: https://github.com/dp-pcs/AsynchronousAgent_Jules_Take2
Devin
Messy repo: https://github.com/dp-pcs/AsynchronousAgent_Devin
Prediction app: https://github.com/dp-pcs/AsynchronousAgent_Devin_Take2
Genspark
Messy repo: https://github.com/dp-pcs/AsynchronousAgent_Genspark
Prediction app: https://github.com/dp-pcs/AsynchronousAgent_Genspark_Take2
AbacusAI
Messy repo: https://github.com/dp-pcs/AsynchronousAgent_Abacus
Prediction app: https://github.com/dp-pcs/AsynchronousAgent_Abacus_Take2
Totally unexpected that the two less popular tools outperform Jules and Devin. Going to give them a try.