

[News Brief] Three Significant Open Releases for AI
DeepSeek’s Math Model, Prime Intellect’s RL Stack, and Ai2’s Fully Open Model Flow

The past week brought three significant releases to the open AI community: DeepSeek unveiled DeepSeekMath-V2 on November 27, the first openly available model to achieve gold-medal performance at the International Mathematical Olympiad; Prime Intellect released INTELLECT-3 the same day, a 106-billion parameter model with its complete training infrastructure; and the Allen Institute for AI launched OLMo 3 on November 20, introducing what it calls the complete “model flow” with unprecedented transparency into training data and processes. Together, these releases represent different philosophies about what “open” means in AI development.
DeepSeekMath-V2:
Self-Verifiable Mathematical Reasoning
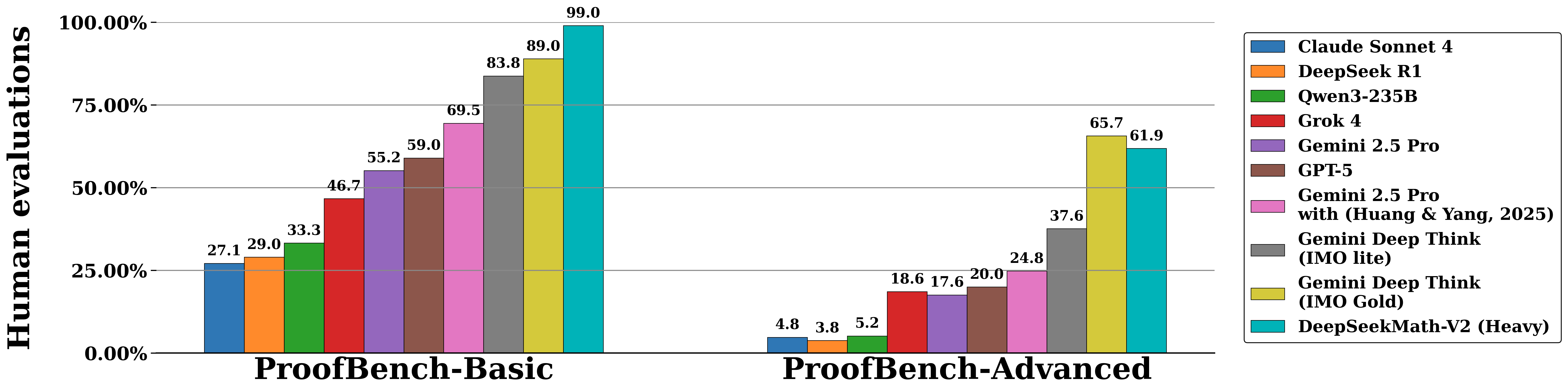
DeepSeekMath-V2 becomes the first publicly downloadable model to match the International Mathematical Olympiad gold-medal performance previously achieved only by closed experimental systems from OpenAI and Google DeepMind.
DeepSeek’s latest mathematical model tackles what the team identifies as a fundamental limitation in current AI reasoning systems: achieving correct final answers through incorrect reasoning. While recent models have improved dramatically on quantitative benchmarks like AIME and HMMT, the DeepSeek team argues that this progress masks a deeper problem.
Unlike rival systems hidden behind APIs, DeepSeek has released the weights publicly, allowing researchers to inspect its logic directly. The model is built on top of DeepSeek-V3.2-Exp-Base and released under the Apache 2.0 license.
Competition Results
DeepSeekMath-V2 achieved notable benchmark performance:
On the William Lowell Putnam Mathematical Competition, the preeminent mathematics competition for undergraduate college students in the United States and Canada, the model scored 118 out of 120, surpassing the top human score of 90.
At the International Mathematical Olympiad 2025, the model solved 5 of 6 problems, achieving gold-medal status. This places DeepSeekMath-V2 alongside experimental systems from OpenAI and Google DeepMind that achieved similar results earlier this year on the same competition.
The model also performed strongly on IMO-ProofBench, a benchmark developed by the Google DeepMind team, reaching an accuracy of nearly 99% on the Basic subset and coming close to Gemini DeepThink on the more difficult Advanced subset.
Technical Approach
DeepSeekMath-V2’s architecture centers on training both a proof generator and a verifier model that work in tandem. The verifier serves as a reward model during training, and the generator is incentivized to identify and resolve issues in its own proofs before finalizing them.
A key challenge is maintaining what the team calls the “generation-verification gap.” As the generator improves, the verifier must keep pace. DeepSeekMath-V2 solves this through dynamic scaling of verification compute, automatically labeling difficult proofs to create new training data for the verifier.
In its most powerful configuration, Math-V2 generates 64 candidate proofs, runs 64 independent verifications on each, and repeats this refinement cycle up to 16 times. This computational intensity has practical implications for deployment costs.
Limitations and Context
The system provides no formal guarantees; unlike proof assistants that mathematically verify correctness, Math-V2 operates in natural language where an LLM verifier can still err. The model is also highly specialized for mathematical theorem proving and is not designed as a general-purpose assistant.
Questions also persist about potential training data overlap with benchmark problems, a concern that applies broadly across the field of mathematical AI systems.
INTELLECT-3:
Open Infrastructure for Large-Scale RL
Prime Intellect’s release takes a different approach, focusing on providing not just model weights but the complete infrastructure stack used to create them. INTELLECT-3 is a 106-billion parameter Mixture-of-Experts model (with 12 billion active parameters) trained using supervised fine-tuning and reinforcement learning on top of the GLM-4.5-Air base model.
Benchmark Performance
The model achieves strong results across reasoning benchmarks:

The team reports that evaluation curves had not plateaued by the end of training, suggesting potential for continued improvement with additional compute.
Infrastructure Stack
Prime Intellect open-sourced several components alongside the model:
prime-rl is an asynchronous reinforcement learning framework designed for scale. The architecture separates training and inference across different GPU pools, enabling continuous batching and in-flight weight updates. Traditional RL systems often stall inference while waiting for training updates; prime-rl allows rollout generation to continue asynchronously.
Verifiers and the Environments Hub provide a standardized interface for RL environments. The Environments Hub hosts over 500 tasks across math, code, science, logic, deep research, and software engineering domains. Environments are packaged as standalone Python modules that can be versioned and shared independently of training code.
Prime Sandboxes handles secure code execution for thousands of concurrent rollouts. The team found that standard Kubernetes orchestration patterns created unacceptable latency at scale, with execution times spiking to 2.5 seconds per command due to API server saturation. Their solution bypasses the Kubernetes control plane for the critical execution path, communicating directly with pods through headless services.
Training Details
INTELLECT-3 was trained on 512 NVIDIA H200 GPUs across 64 nodes over two months. Training proceeded in two stages: a general reasoning SFT stage using datasets from NVIDIA’s Nemotron-Post-Training-Dataset and AM-DeepSeek-R1-0528-Distilled, followed by an agentic SFT stage focused on tool use and long-horizon tasks.
The RL stage used a mix of environments across math (21.2K problems), code (8.6K examples), science (29.3K problems), logic (11.6K problems), deep research, and software engineering. Online difficulty filtering dynamically adjusted task difficulty during training, removing problems with 100% solve rates that would provide no learning signal.
The team adopted token-level importance sampling with double-sided masking to address training-inference mismatches that could cause training instability. They note that even when inference and training use the same model parameters, different implementations can produce significantly different token probabilities.
Infrastructure Challenges
Several technical challenges emerged during training:
Scaling sequence length required activation offloading to CPU, enabling 72K context lengths where standard approaches only supported 48K. Context parallelism was explored but exhibited accuracy degradation.
Distributing the Muon optimizer across nodes required custom implementations. Standard approaches using overlapping round-robin gather operations caused InfiniBand congestion at scale; the team adopted all-to-all collectives instead.
MoE layer efficiency depended heavily on workload characteristics. The team found that expert parallelism actually reduced throughput in their setting because their sequence lengths and hidden dimensions already saturated the grouped gemm kernels.
OLMo 3:
The Complete Model Flow
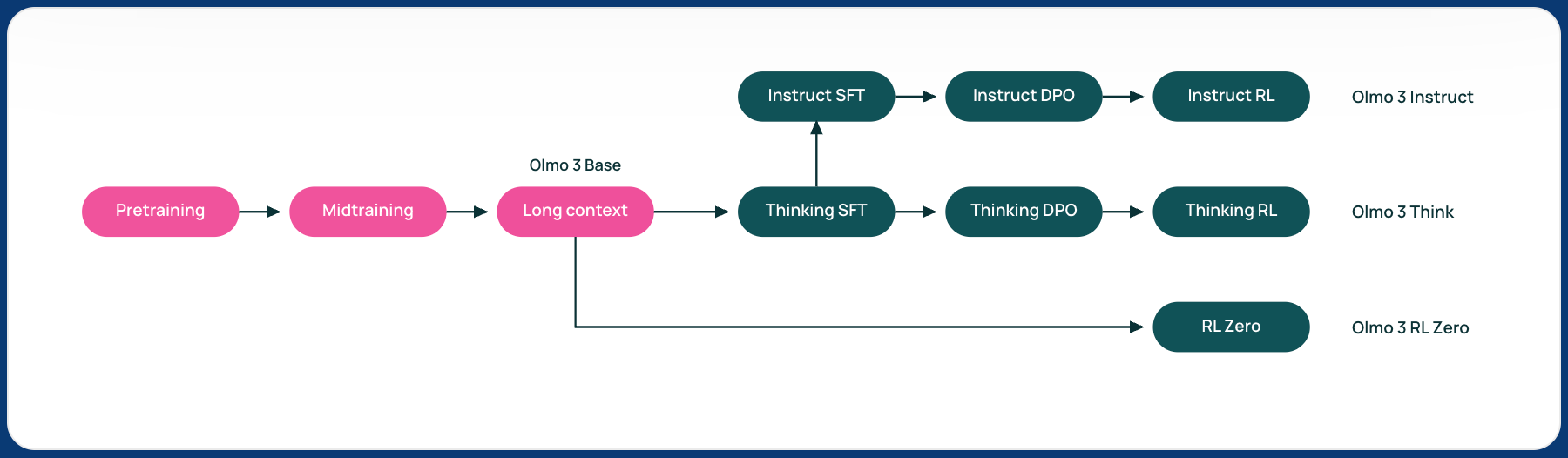
The Allen Institute for AI (Ai2) released a new generation of its flagship large language models, designed to compete more squarely with industry and academic heavyweights. Where DeepSeek and Prime Intellect release weights and infrastructure respectively, Ai2 emphasizes what it calls the “model flow”: the full lifecycle of an LM: every stage, checkpoint, dataset, and dependency required to create and modify it.
Model Family
Ai2 is releasing Olmo 3 in multiple versions: Olmo 3 Base (the core foundation model); Olmo 3 Instruct (tuned to follow user directions); Olmo 3 Think (designed to show more explicit reasoning); and Olmo 3 RL Zero (an experimental model trained with reinforcement learning).
The models come in 7B and 32B parameter sizes, with the release including the first-ever fully open 32B thinking model that generates explicit reasoning-chain-style content.
Benchmark Results
On the challenging MATH benchmark, OLMo 3-Think (32B) achieved a score of 96.1%, surpassing both Qwen 3 32B (95.4%) and DeepSeek R1 Distill 32B (92.6%). In the HumanEvalPlus evaluation, which tests for robust code generation, the model scored 91.4%, again leading the field against comparable open-weight models.
On math benchmarks, Olmo 3-Think (7B) matches Qwen 3 8B on MATH and comes within a few points on AIME 2024 and 2025, and also leads all comparison models on HumanEvalPlus for coding.
Training Efficiency
In terms of energy and cost efficiency, Ai2 says the new Olmo base model is 2.5 times more efficient to train than Meta’s Llama 3.1 (based on GPU-hours per token, comparing Olmo 3 Base to Meta’s 8B post-trained model). Much of this gain comes from training Olmo 3 on far fewer tokens than comparable systems, in some cases six times fewer than rival models.
Data Transparency
Olmo 3 is pretrained on Dolma 3, a new approximately 9.3-trillion-token corpus drawn from web pages, science PDFs processed with olmOCR, codebases, math problems and solutions, and encyclopedic text.
The staged training curriculum uses three data mixes: Dolma 3 Mix for main pretraining, Dolma 3 Dolmino Mix (100B tokens emphasizing math, code, and instruction following) for mid-training, and Dolma 3 Longmino Mix for long-context extension.
OlmoTrace
A distinctive feature of the release is OlmoTrace, a tool for tracing model outputs back to training data. In the Ai2 Playground, you can ask Olmo 3-Think (32B) to answer a general-knowledge question, then use OlmoTrace to inspect where and how the model may have learned to generate parts of its response.
This addresses a concern raised by Ai2 researcher Nathan Lambert in his post about the release: Researchers can study the interaction between the reasoning traces we include at midtraining and the downstream model behavior. This helps answer questions that have plagued RLVR results on Qwen models, hinting at forms of data contamination particularly on math and reasoning benchmarks.
The RL Zero Variant
OLMo 3-RL Zero is designed specifically for researchers studying reinforcement learning on language models. It is built as a fully open RL pathway on top of Olmo 3-Base and uses Dolci RL Zero datasets that are decontaminated with respect to Dolma 3. This separation between pretraining data and RL data allows cleaner study of what RL contributes to model capabilities.
Three Definitions of “Open”
These releases illustrate different interpretations of openness in AI development.
DeepSeekMath-V2 represents specialized excellence with open weights. The model achieves competition-level mathematical reasoning through a focused architecture, and anyone can download and run it. The training data and methodology are described in a paper but not released.
INTELLECT-3 prioritizes infrastructure reproducibility. Prime Intellect releases not just weights but the complete training framework, environment definitions, and orchestration code. The focus is on enabling others to train similar models, with the Environments Hub providing a growing collection of RL tasks.
OLMo 3 emphasizes data transparency and traceability. Most “open” models today are effectively black boxes with public handles; developers can use them but cannot audit how they were built. AI2 seeks to reverse this trend by releasing Dolma 3, a massive pretraining dataset, alongside Dolci, a specialized corpus for post-training instruction tuning.
The practical implications differ:
For researchers studying mathematical reasoning at the frontier, DeepSeekMath-V2 provides a capable system to probe and analyze. For teams wanting to train their own RL models, Prime Intellect’s stack offers production-tested infrastructure. For those concerned with understanding model behavior and potential contamination, OLMo 3’s data transparency enables audit and verification.
Evaluating the Claims
All three releases warrant careful evaluation.
DeepSeekMath-V2’s mathematical olympiad performance, while impressive, represents narrow capability. The computational requirements for peak performance (64 proofs × 64 verifications × 16 refinement cycles) illustrate a tension: the most capable configurations may be impractical for routine use. The system also operates in natural language rather than formal proof languages, meaning verification is probabilistic rather than guaranteed.
INTELLECT-3’s benchmark comparisons use evaluations run through Prime Intellect’s own standardized implementations. While this ensures consistency across models tested, it may produce results that differ from evaluations run by other teams. The technical report acknowledges that their observed scores for some models differ from those in official model cards.
OLMo 3 makes strong efficiency claims (2.5x more efficient than Llama 3.1, training on 6x fewer tokens than rivals) that depend on specific comparison points. Despite being open source, the vendor’s largest model has 32B parameters, whereas other open model providers offer models that are larger. For example, Meta Llama 3.1-405B. The 32B scale is practical for many researchers but may limit applications requiring larger models.
The data contamination concern that OLMo 3 aims to address with transparency applies broadly. As Nathan Lambert noted, questions about benchmark contamination “have plagued RLVR results on Qwen models,” and having fully open training data allows researchers to verify whether specific benchmark problems appeared during training.
Industry Context
These releases arrive amid ongoing debate about the value and sustainability of open AI development.
Earlier versions of Olmo were framed mainly as scientific tools for understanding how AI models are built. With Olmo 3, Ai2 is expanding its focus, positioning the models as powerful, efficient, and transparent systems suitable for real-world use, including commercial applications.
DeepSeek’s decision to release such a capable model as open source also highlights an ongoing tension in AI development between proprietary and open approaches. While Western labs have increasingly kept their most advanced systems closed, Chinese companies like DeepSeek have been more willing to release state-of-the-art models publicly.
Prime Intellect explicitly frames its work as democratization: the technical report states that “Prime Intellect is building the open superintelligence stack, putting the tools to train frontier models into your hands. INTELLECT-3 serves as an example that you don’t need to be from the big labs to train models that compete in the big leagues.”
Open models have been gaining traction with startups and businesses that want more control over costs and data, along with clearer visibility into how the technology works. These three releases, each in their own way, expand what’s available to organizations preferring open alternatives to API-only frontier models.
Availability
DeepSeekMath-V2 weights are available on HuggingFace under the Apache 2.0 license. Inference requires the DeepSeek-V3.2-Exp infrastructure, with support documentation available in the GitHub repository.
INTELLECT-3 weights, the prime-rl framework, the verifiers library, and all training environments are available through HuggingFace and GitHub. The Environments Hub provides access to the task collections used for training and evaluation.
OLMo 3 models are available on HuggingFace under the Apache 2.0 license. The release includes Dolma 3, a 9.3-trillion-token corpus, and Dolci, a post-training dataset suite for reasoning, tool use, and instruction-following tasks. Models can be accessed through the Ai2 Playground or via OpenRouter.
Brilliant breakdown of how these three releases embody fundamentally different interpretations of openness in AI. What stands out most is Prime Intellect's decision to address the infrastructure reproducability gap specifically around RL at scale. The token-level importance sampling with double-sided masking to handle training-inference mismatches is particularly clever, since this problem quietly undermines so many RL efforts. One aspect worth exploring further is whether DeepSeek's generation-verification gap management could be adapted to other domains beyond math proofs. The dynamic scaling of verification compute seems like a pattern that might generalize to any task where you can formulate a verificaiton signal, though the computational overhead could be prohibitive outside specialized domains.