

How the Machines Finally Learned to Draw
OpenAI's GPT Image 2 didn't just get sharper. It got smart — by abandoning the way image models used to work.

The week OpenAI shipped GPT-4o’s native image generator in March 2025, Sam Altman tweeted that the company’s GPUs were “literally melting.” Within seven days, 130 million people had made over 700 million pictures. You could feel it: every tech conference badge, every Substack header, every memed restaurant menu suddenly had the same warm-paper, hand-painted, eerily readable look.
Then, in April 2026, OpenAI replaced it. The new model — gpt-image-2 — landed at #1 on every category of the LM Arena image leaderboard with an Elo of 1512 in text-to-image and 1513 in editing. On LM Arena, the next-best model, Google’s Nano-banana-2 (Gemini 3.1 Flash Image), trailed by 242 Elo points at launch, which in head-to-head blind testing translates to roughly an 80% win rate. Other public boards show a tighter spread, but the directional verdict is the same: it’s not a step. It’s a gulf.
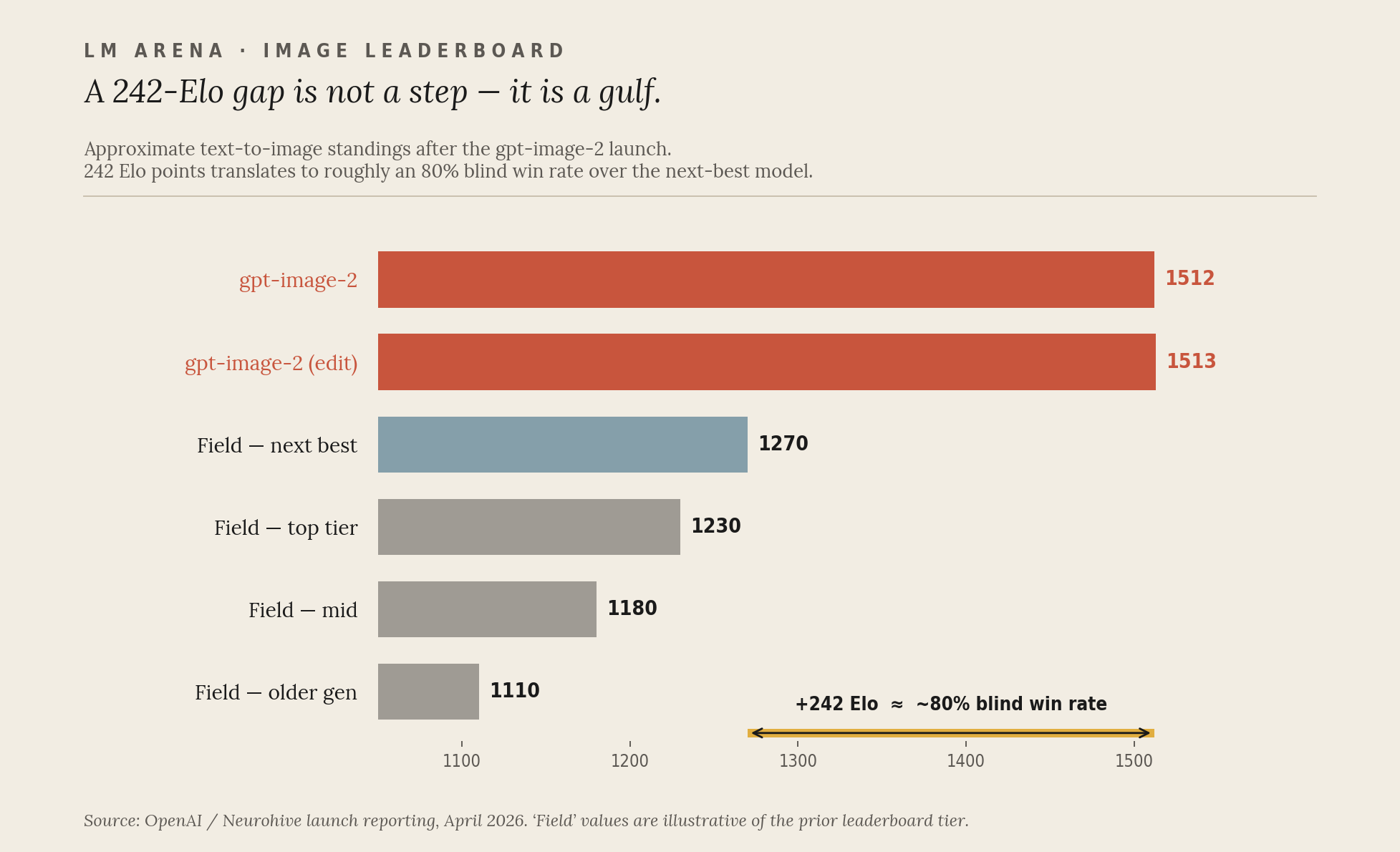
If you have been watching this space casually, the obvious question is: how on earth did a year of work produce a leap that big? The answer is that under the hood, the field has been quietly switching engines.
The old way: sculpt the picture out of noise
For most of the last five years, “AI image generation” basically meant diffusion. Stable Diffusion, Midjourney, Adobe Firefly, the original DALL·E 2 and DALL·E 3, they all worked roughly the same way. You start the model on a screen of pure television-static random noise. You hand it a prompt. And then it asks itself, over and over, the same question: given everything I know about real images, what flecks of noise should I subtract right now to make this look slightly more like the thing the prompt described?
Repeat that thirty or fifty times and the static resolves into a cat, a city, a corporate logo. Diffusion is a strange, beautiful, and deeply iterative process, sculpting an image out of fog. It made the modern wave of generative art possible (the canonical paper, “Denoising Diffusion Probabilistic Models” by Ho, Jain & Abbeel, dropped in 2020). But it has weaknesses, and they are exactly the ones every casual user has cursed at: garbled text, mangled hands, prompts that ask for “six apples” and produce eight, or three, or, somehow, a pear.
The reason is that diffusion doesn’t really plan. It paints. It has no separate, structured representation of “there should be six discrete apple-objects here.” It just shapes pixels until the pixels feel right.
The new way: write the picture, one piece at a time
GPT-4o’s image generator in 2025, and now gpt-image-2, do something different. They treat an image the way GPT-4 treats a sentence: as a sequence of tokens to be predicted, one after another. Each “visual token” is a compressed chunk of image content; the transformer stares at the prompt and at all the tokens it has already written, and predicts what the next one should be. Then a small diffusion decoder at the end paints those tokens into actual pixels.
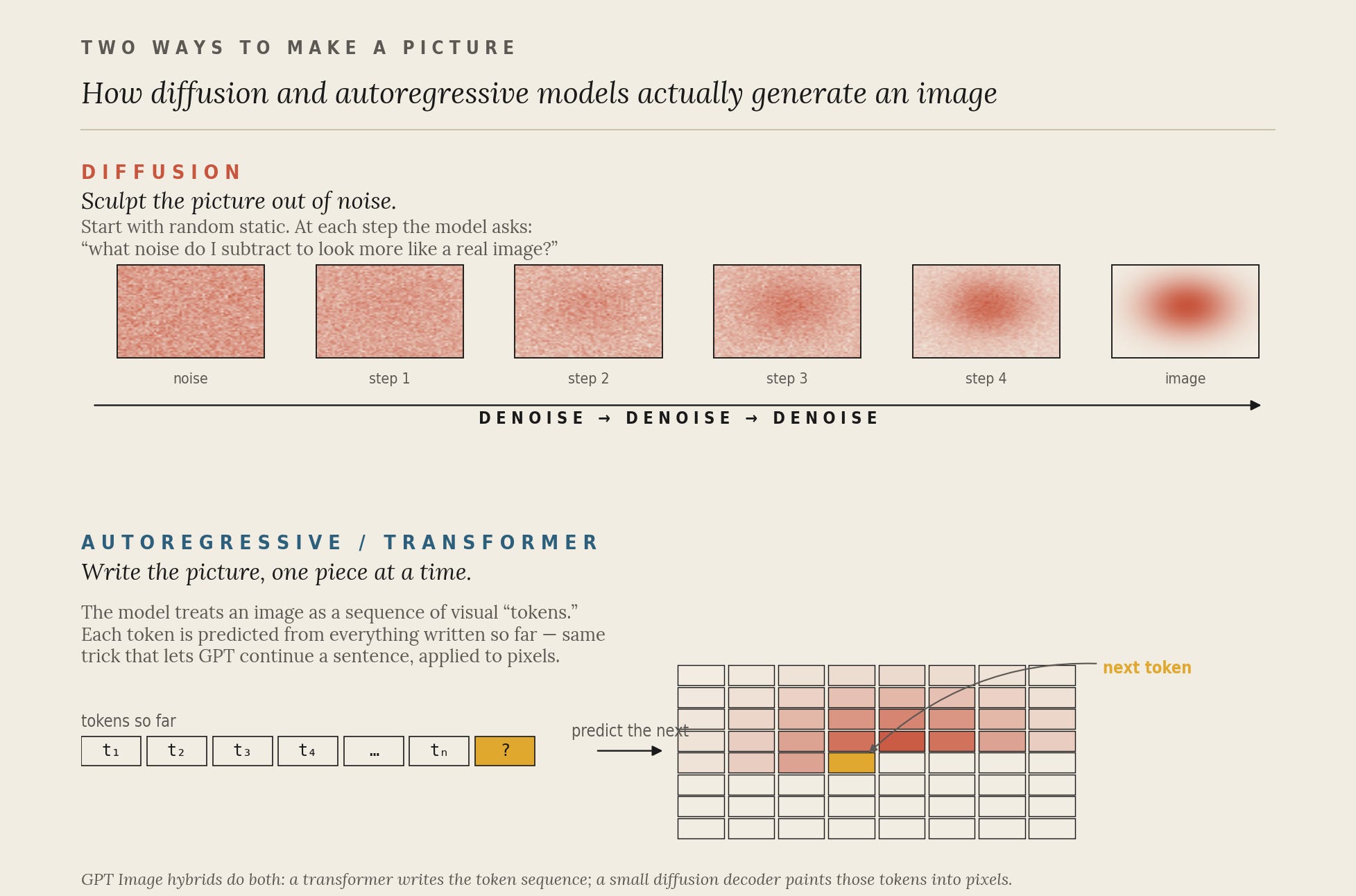
This hybrid, sometimes called the Transfusion architecture in the research literature (Zhou et al., Meta AI, 2024), is the central conceptual shift. It means an image model can use the same machinery that makes language models good at logic, counting, and following multi-step instructions. It can reason about its own output before any pixel exists.
The architecture was revamped from scratch.
— Reported comments from OpenAI’sgpt-image-2research team
That phrase is not marketing fluff. It explains the leaderboard.
What "thinking" buys you
The headline feature of gpt-image-2 is that it is the first image model with native reasoning. You can dial it: low, medium, or high. At higher settings, the model plans the composition, counts the objects it has committed to, checks the prompt’s constraints against what it has drafted, and, if it decides it needs current information, runs a web search mid-generation.
This sounds like a small thing. It is not.

Older diffusion models start to fall apart somewhere around five to eight distinct objects in a scene; GPT-4o’s image stack pushed that ceiling to ten or twenty (rough heuristic, not a benchmarked number). More importantly, because the model is reasoning over a structured token stream rather than blurring fog, it can finally render text. Higgsfield, a third-party platform that integrated the new model on day one, claims its accuracy crosses 95%, including small Cyrillic, Chinese, Japanese and Korean characters on curved surfaces, inside dense layouts. If you have ever watched an AI try to write the word “OPEN” on a coffee shop sign, you understand what is happening here.
The other spec jumps follow from the same core change.

Those headline numbers are best read as the cumulative gap from gpt-image-1 to gpt-image-2, OpenAI shipped an interim gpt-image-1.5 in between, and several of the resolution, aspect-ratio, and multilingual-text gains landed in that release. The genuinely new thing in gpt-image-2 is native reasoning. Maximum resolution went from 1024 to 2000 pixels on the long edge. Aspect-ratio presets went from three to seven. You can request up to ten style-consistent images in a single call instead of one. The knowledge cutoff jumped from April 2024 to December 2025. At the API level, a high-quality 1024×1024 image runs roughly $0.21, meaningfully more than its predecessors, which the people running it can charge because the output is roughly twice as good and much harder to redo by hand.
The day the API stack changed
The clearest signal that something structural has happened is who shipped support on day one. Figma, Canva, Adobe Firefly, and fal all integrated gpt-image-2 immediately on launch. The other tell came months earlier: in November 2025, OpenAI announced that DALL·E 2 and DALL·E 3 would be retired on May 12, 2026. Read together, those two moves are a company telling you: the diffusion-only era is over, and we are not running two pipelines.
The most interesting systemic implication is that image generation is starting to function as a frontend for coding agents.
— Neurohive, on developer reactions togpt-image-2
Read that quote twice. It captures something most consumer coverage missed. When an image model can reason, follow specs, render perfect text in any script, and produce ten visually consistent variants in one shot, it stops being an “AI art tool” and starts being infrastructure for design, the Figma plugin, the slide template generator, the auto-built dashboard mockup, the icon set for your half-built side project. The thing you used to need a junior designer for.
What's coming next
The frontier is already moving past stills. OpenAI shut down the original Sora consumer app on April 26, 2026, with the legacy Sora API following on September 24, but the underlying model line lived on as Sora 2, which now competes with Google’s Veo 3.1, Kuaishou’s Kling 3.0, and ByteDance’s Seedance 1.5 Pro. All four now generate native synchronized audio, with Kling running at native 4K up to 60 fps. On Vivideo, one of the larger aggregators, Veo 3.1 captured roughly 96% of all video-generation orders in early 2026, while monthly orders on that platform grew fivefold from December to January.
The pattern in stills is repeating in motion. The frontier consensus, looking forward, is roughly: hyper-niche models trained for architecture, fashion, and medical imaging; real-time interactive generation you can drag around like a Figma canvas; and fully editable scenes you can rewrite by typing, “make it dusk, lose the second person, move the building closer.” None of that is possible if your model is just denoising random fog.
The takeaway
Two things are worth holding on to.
First, the reason gpt-image-2 is so much better than what came before is not “more compute” or “more data.” It is a different theory of what an image is. Diffusion treats an image as a noisy soup to be cleaned up. Autoregressive transformers, with a small diffusion decoder bolted on, treat it as a structured sentence to be composed. The second view turns out to be much closer to how humans think when we draw, plan, then mark, then check.
Second, if you are a writer, a designer, a small-business owner, or a developer wondering whether to keep paying for stock illustration, brand assets, or visual one-offs: the answer is now, basically, no. The garbled-text problem is solved. The “five apples” problem is mostly solved. The DALL·E era is being switched off in May. Whatever your workflow looked like a year ago, it is worth rebuilding it around a model that can read, count, and render, because everyone else is about to.
David Proctor is VP of AI at Trilogy. He writes about AI infrastructure, agent protocols, and what actually works in production.