

Frontier Code Intelligence
Code Intelligence Is Becoming Architectural Understanding

AI coding systems increasingly build repository models that index code, trace symbols, retrieve evidence, explain architecture, guide edits, and preserve development context.
The interface still looks familiar: a chat panel, an autocomplete box, a command palette, a diff view. The underlying system has become much larger than the UI suggests. Leading tools now combine background indexing, semantic retrieval, grep-style search, symbol navigation, generated documentation, repository maps, task memory, and execution environments.
That combination changes the job of a coding assistant. It has to locate behavior, explain dependencies, recover design context, identify safe edit points, modify code, run checks, and leave useful memory behind.
“AI coding assistant” is becoming too small a name for the category. These systems are becoming architecture intelligence tools: software that builds and maintains an operational model of a codebase for humans and agents.
Repository models are replacing isolated snippets
Early AI coding products centered on inline completion and local explanation. Current systems work across repositories, issues, branches, documentation, tests, command output, and commit history. The unit of value has expanded from a suggested line of code to a model of how the software works.
Cognition’s public Devin materials show this clearly, although the product names need careful separation.
Public DeepWiki, available through DeepWiki.com and Devin’s DeepWiki documentation, is a repository-level documentation system. It indexes repositories and generates wiki-style pages with architecture diagrams, codebase summaries, source links, and structured documentation. Ask Devin can use the wiki as part of its codebase understanding. DeepWiki can also be steered with a .devin/wiki.json file that supplies repository notes and explicit page definitions. For public repositories, DeepWiki provides a lightweight way to inspect unfamiliar open-source codebases through generated documentation and Q&A: just replace github.com/org/repo with deepwiki.com/org/repo in the URL.
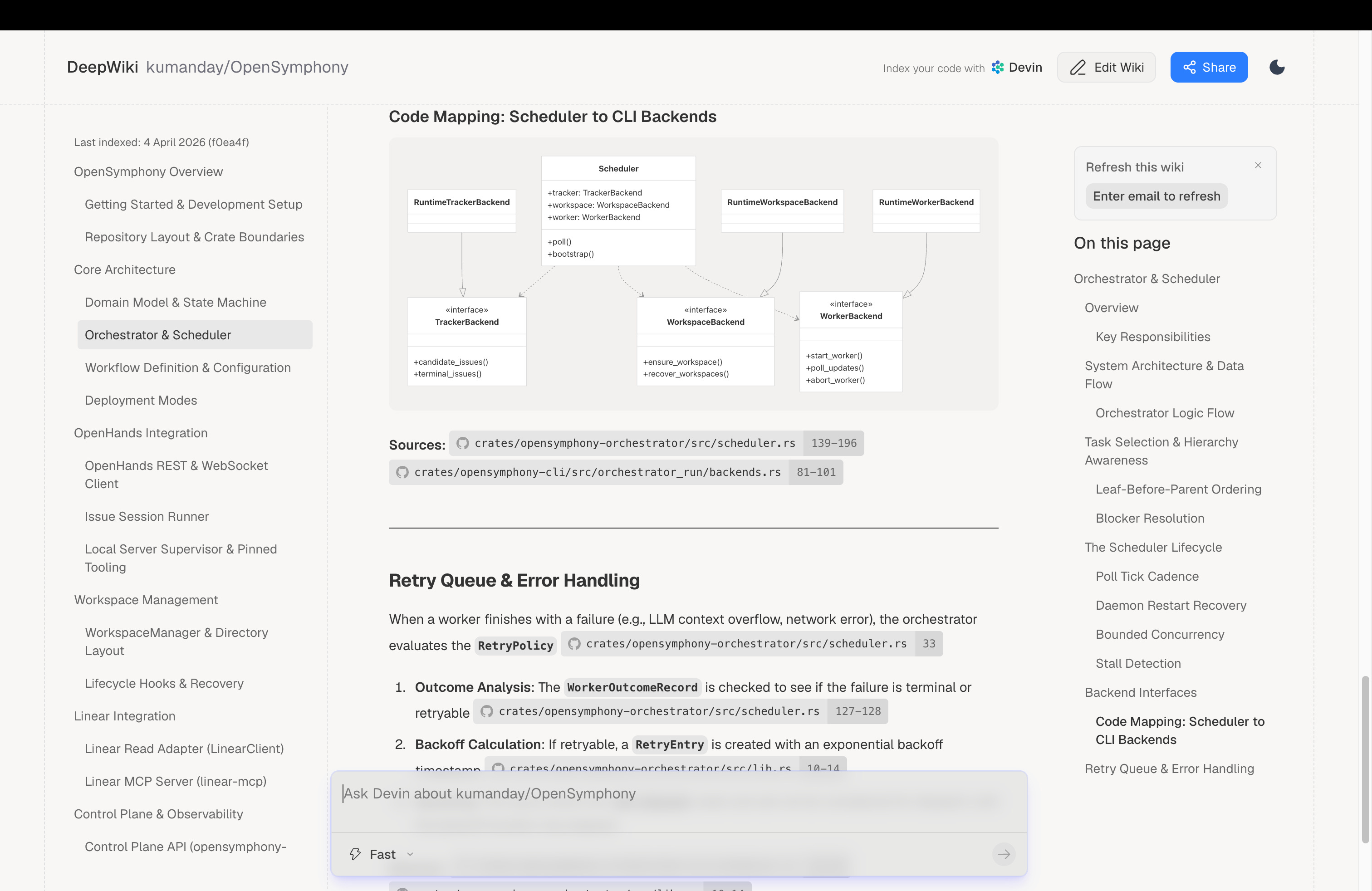
DeepWiki MCP exposes that repository documentation through tools. An AI client can read the wiki structure, read wiki contents, and ask questions about a public repository. This expands public DeepWiki from a web site to a documentation and retrieval substrate.
Devin Desktop DeepWiki is a different surface with the same name. It belongs to the Devin Desktop IDE lineage that came from Windsurf. In that context, DeepWiki explains code symbols inside the editor. A developer can hover over functions, variables, and classes to get AI-powered explanations of unfamiliar code. The granularity is local and symbol-centered.
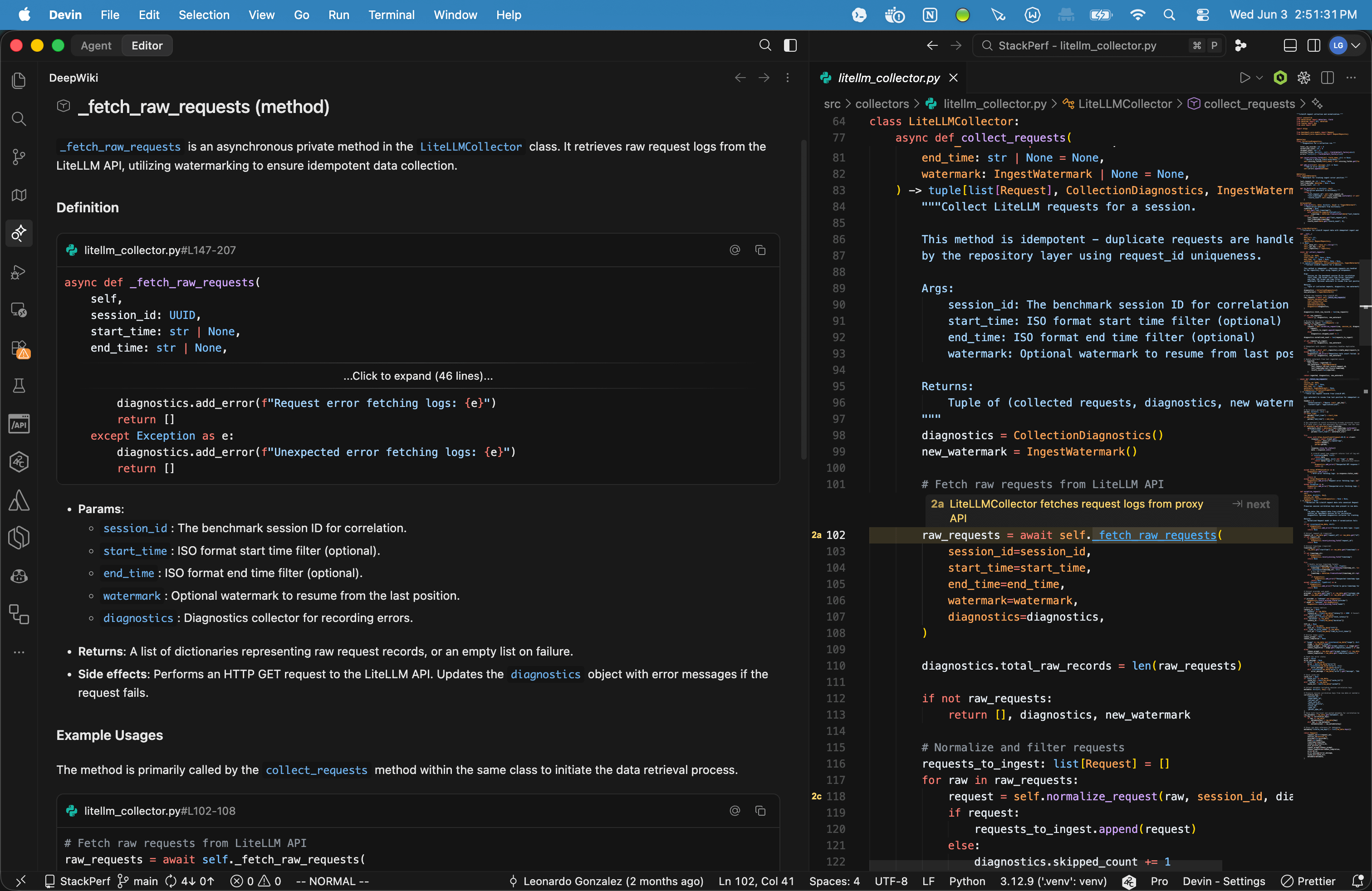
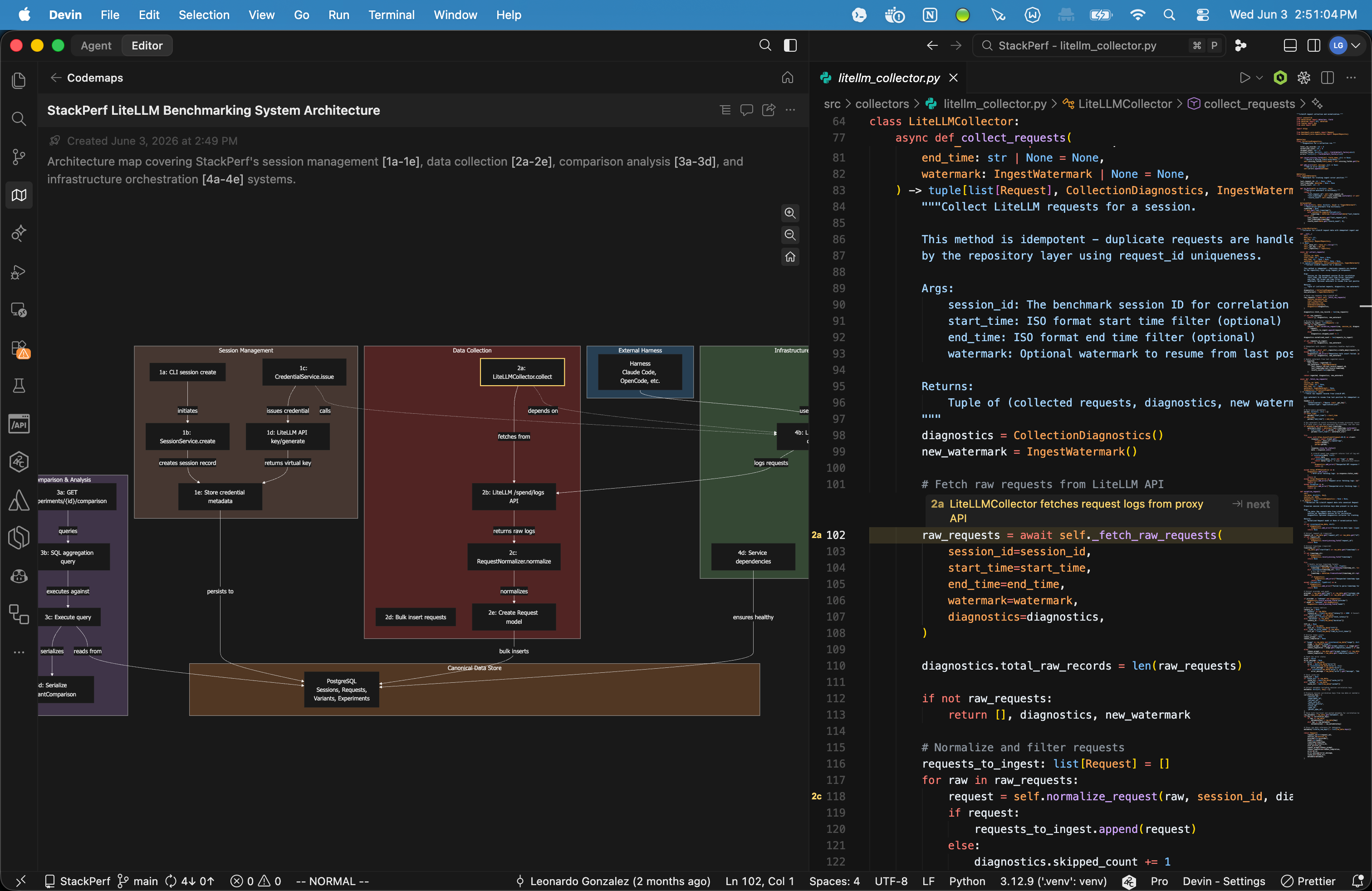
Codemaps are separate again. They create shareable hierarchical maps of code execution flow and component relationships. A Codemap communicates how a path through the repository works. Public DeepWiki communicates repository architecture as generated documentation. Devin Desktop DeepWiki explains individual symbols during active coding.
This taxonomy clarifies the Cognition stack:
Ask Devin is the codebase Q&A and planning surface.
Public DeepWiki is repository-level generated documentation and Q&A.
DeepWiki MCP exposes public DeepWiki to external AI clients.
Devin Desktop DeepWiki provides symbol-level explanations in the IDE.
Codemaps provide flow-oriented maps of code execution and component relationships.
Fast Context retrieves relevant code through a specialized retrieval subagent.
Cognition’s acquisition of Windsurf adds context to the product layout. Current Devin docs place many former Windsurf IDE capabilities under Devin Desktop: Cascade, Fast Context, Codemaps, context awareness, and the in-editor DeepWiki feature. The product language can be confusing because “DeepWiki” names both the public repository wiki and the Devin Desktop symbol-explanation feature. For architecture analysis, the useful split is simple: public DeepWiki is closer to generated architectural documentation, Codemaps are closer to execution-flow maps, and Devin Desktop DeepWiki is closer to symbol comprehension.
Augment Code frames the same general problem as context infrastructure. Its Context Engine maintains codebase understanding across local files, remote repositories, services, history, and external sources. Public docs describe local indexing for active work, remote indexing for team repositories, workspace indexing, context compression, and an MCP mode that lets other agents call Augment as a semantic context service. Augment’s Project Home Page also turns index data into a codebase summary with file stats and language breakdowns.
Cursor and Devin Desktop expose the retrieval side inside the IDE. Cursor documents semantic and agentic search, codebase indexing, dynamic context discovery, and fast regex search. Its public engineering posts describe systems work around syntactic chunking, caching, cryptographic content proofs, and local exact search for read-your-writes behavior. Devin Desktop documents a RAG-based context engine, local and remote indexing, Fast Context, SWE-grep models, public DeepWiki access through MCP, Devin Desktop DeepWiki, and Codemaps. Fast Context is especially useful as a product signal because it treats code retrieval as a specialized subproblem with its own subagent and tool budget.
Sourcegraph brings a longer code intelligence lineage. Its platform combines large-scale code search, code navigation, code graph infrastructure, embeddings, and SCIP-based symbol indexing. Cody uses repository context from Sourcegraph search and code intelligence. Continue provides a useful open reference point for code RAG, local indexing, embeddings, keyword search, and reranking.
Zed, Claude Code, Codex, and OpenHands all contribute additional surfaces around agent execution, command use, file inspection, patching, and context assembly. The ecosystem pattern is consistent. Search, chat, edit, and documentation are becoming different views over the same project representation.
Agentic search is a reasoning process
Repository understanding usually requires several searches. A developer asks where authorization is enforced. A useful agent may search for policy names, grep for tenant_id, inspect middleware, follow references, read tests, and check recent changes. The final answer may cite a controller, a service module, a database constraint, and a fixture. A single top-k retrieval call rarely captures that path.
Modern agentic search has a practical loop:
Interpret the task.
Generate a search plan.
Run semantic search, exact search, symbol search, and file search.
Read promising files.
Follow definitions, references, imports, and tests.
Revise the search based on evidence.
Pack the final context for answering or editing.
Save the useful trace.
The trace matters. It records what the agent tried, which files it inspected, which symbols it followed, and why the selected evidence matters. That gives a human something to audit. It also gives the next agent a starting point.
Devin Desktop’s Fast Context and SWE-grep work points toward a useful architectural split. Retrieval can have its own subagent, model, and tool restrictions. Code generation and code search have different performance profiles. Search wants parallel grep, reads, globbing, and early pruning. Code editing wants coherent synthesis, tests, and patch control.
Cursor’s search architecture reaches a similar conclusion through product engineering. Fast local regex search handles exact, fresh, local evidence. Semantic search handles broader recall. Agentic exploration connects the two. The system can pick the search mode that fits the current uncertainty.
A strong code intelligence system should expose this search process. The user should see the search intent, queries, files read, symbols traversed, evidence selected, and assumptions carried forward. That turns search from a hidden retrieval step into an inspectable development artifact.
Retrieval needs several layers
Code retrieval has a harder job than document retrieval. Identifiers matter. File paths matter. Runtime entry points matter. Generated code can distract. Tests can reveal behavior better than implementation files. Comments, docstrings, migrations, configs, and issue text can all contain decisive evidence.
A useful retrieval stack needs several layers:
exact search for identifiers, error strings, config keys, and local edits
semantic retrieval for natural-language questions and conceptual matches
symbol indexing for definitions, references, implementations, and imports
dependency expansion for callers, callees, tests, and related modules
reranking for evidence selection
context packing for model input
freshness logic for branches, rebases, file changes, and generated artifacts
Sparse lexical search remains essential. Codebases contain rare names that embeddings can blur: AuthzPolicy, stripe_webhook_secret, ERR_INVALID_STATE, onConnectionLost, TenantScopedSession. Exact search finds these directly. Regex search adds structural flexibility and local speed.
Dense retrieval adds recall. It can connect “retry failed subscription billing event” with webhook processors, queue handlers, dead-letter jobs, and reconciliation tests even when the query shares few words with the code.
Symbol and graph layers add precision. A function named authorize may appear in production middleware, a test fixture, and a mock adapter. Symbol intelligence distinguishes definitions, imports, references, and implementations. Dependency graphs help decide whether a file is central or incidental.
Freshness is a product requirement. A code index that lags behind a branch switch can mislead an agent. Cursor’s public discussion of local regex indexing and read-your-writes behavior addresses this directly. Augment’s real-time per-developer indexing makes a similar point. Large shared indexes help with enterprise scale, and local or incremental paths keep the current task grounded.
Context packing is the other hard problem. Large model windows reduce pressure, yet dumping excessive files into context still creates noise. The system has to choose evidence. It should include the relevant source snippets, summaries, tests, dependency edges, and recent changes. It should leave enough trace for audit.
Multi-vector retrieval fits code
Most dense retrieval systems compress each chunk into one vector. That compression can blur exactly the signals that matter in code: rare identifiers, API names, error strings, config keys, domain nouns, and call-site roles.
ColBERT-style late interaction keeps token-level representations and scores query-document matches through fine-grained token similarity. ColBERTv2 adds compression to reduce the storage cost. SLIM and newer late-interaction tooling explore ways to bring multi-vector retrieval closer to scalable search infrastructure.
Late Interaction: ColBERT to Wholembed v3

Late-interaction retrieval has become a product question, and Wholembed v3 arrives just as Google ships Gemini Embedding 2 and multimodal search turns into everyday engineering.
This family of methods fits several code intelligence problems:
matching stack traces to handlers and tests
retrieving call sites that use the right API in the right role
connecting domain language to code, docs, configs, and migrations
ranking mixed evidence from source files, tests, comments, and issue text
preserving rare identifiers during semantic retrieval
supporting polyglot repositories where one concept appears across languages
The cost profile is real. Multi-vector retrieval uses more storage, heavier indexing, and more expensive query-time scoring than ordinary dense retrieval. A practical system should use it selectively. Exact search should handle identifiers and fresh local edits. Dense retrieval should handle broad semantic recall. Multi-vector retrieval should target relationship-heavy questions where token-level matches change rankings. Static structure should expand from retrieved units to definitions, callers, imports, tests, and documentation.
The best near-term design is a staged retrieval pipeline: lexical search, dense or multi-vector retrieval, structural expansion, reranking, and context packing. Multi-vector search becomes most valuable when code questions mix conceptual language with exact evidence, such as “where do we convert external billing state into internal entitlements?” or “which path turns this failed webhook into a retry event?”
Static analysis grounds agent reasoning
Embeddings answer one kind of question: what looks relevant? Static analysis answers another: what is this symbol, where is it defined, who calls it, and what depends on it?
Tree-sitter, LSPs, SCIP, AST parsers, type checkers, and language servers give agents durable handles. They identify functions, classes, imports, exports, references, implementations, and syntax boundaries. They also help update indexes incrementally as files change.
Static analysis is strongest at concrete structure:
definitions and references
imports and exports
function and class boundaries
interface implementations
type relationships
build entry points
test locations
structural search patterns
Intent often lives in other artifacts: issues, reviews, planning notes, incident reports, migration comments, release notes, and prior agent traces. Runtime behavior can also escape static structure when services interact through queues, APIs, feature flags, or configuration. That is why static analysis works best as a grounding layer inside a broader retrieval and memory system.
A robust agent should use structure to narrow the search space, retrieval to surface relevant evidence, and documentation to preserve the reasoning context. The agent’s confidence should increase when these layers agree: a semantic result points to a file, the symbol graph shows the function is on the active path, tests cover the behavior, and documentation explains the design constraint.
Documentation becomes operational memory
Generated repository documentation is becoming part of the active code intelligence system.
DeepWiki is the clearest public example at repository-documentation scale. It is generated from indexed repositories, linked to source, shaped by repository configuration, used by Ask Devin, and exposed through MCP. Its output resembles a generated architecture handbook with navigable pages and source-grounded explanations.
Codemaps add a different architecture view. They map execution flow and component relationships. A developer can use a Codemap to understand how a path through the codebase works, then share that map with teammates or hand it to an agent as context.
Augment’s project summaries turn indexed context into a workspace overview. Continue’s documentation automation shows how diffs and agent workflows can update docs as code changes. This turns documentation into a retrieval substrate. A wiki page, repository map, symbol explanation, issue summary, review note, and agent search trace can all become context for future work.
The timing matters. Documentation written only at the end of implementation often loses the useful parts of the decision process: rejected approaches, review concerns, compatibility constraints, validation evidence, and known risks. Those details appear during planning, coding, testing, and review. They should be captured while they are still attached to the work.
OpenSymphony makes this idea explicit. Its memory architecture converts completed Linear work into durable development context. It captures issue narrative, workpad content, hierarchy, milestones, PR descriptions, reviews, checks, and source references. It writes private issue capsules, updates a DuckDB index, evolves a learned memory.yaml, and syncs stable subsystem knowledge into public docs.
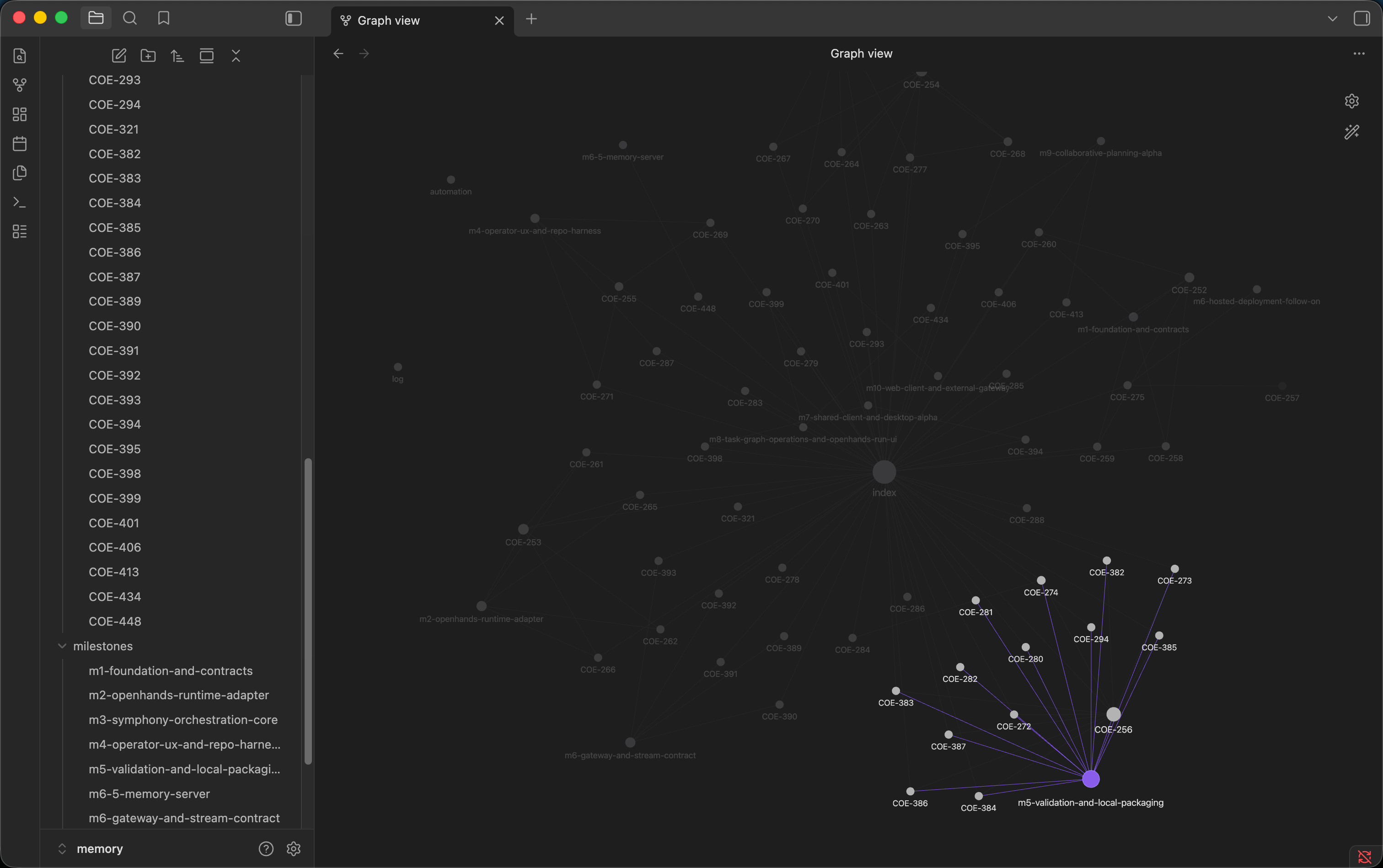
The issue capsule is the important unit. It records what changed, why it changed, which decisions mattered, how the work was validated, which review comments influenced the result, and what follow-up work remains. Topic docs then describe the stable state of a subsystem: current design, invariants, gotchas, and recent changes.
That split is useful for governance. Issue capsules can preserve detailed development context with source references. Topic docs can publish cleaner subsystem knowledge. A memory-docs sync process can keep stable docs aligned with completed work.
This is the right direction for long-running agentic software projects. Each task should leave behind searchable memory. Each subsystem should accumulate updated documentation. Each future agent should inherit the useful context from prior work.
The architecture stack
A modern code intelligence system needs a layered architecture.
At the bottom, it needs fast local search: grep, regex, glob, file reads, and exact matching. This layer gives agents speed and freshness.
Above that, it needs semantic retrieval: embeddings, query expansion, reranking, and possibly late-interaction retrieval for high-value cases. This layer gives agents recall across natural language, comments, tests, and code.
The structural layer adds ASTs, symbols, type information, imports, dependency graphs, call graphs, and test relationships. This layer gives agents precise handles.
The repository-map layer summarizes modules, execution paths, components, and architectural boundaries. Public DeepWiki and Codemaps occupy different parts of this layer. Public DeepWiki turns repository structure into generated documentation. Codemaps turn code paths and component relationships into shareable maps.
The symbol-explanation layer helps developers during active reading. Devin Desktop DeepWiki belongs here, along with code lenses, hover explanations, and editor-local comprehension tools.
The documentation layer includes generated wikis, human-written docs, ADRs, subsystem notes, and searchable knowledge bases. This layer stores stable project knowledge.
The memory layer captures issue-level work: plans, traces, review decisions, diffs, validation, risks, and follow-ups. This layer carries context across tasks.
The execution layer edits code, runs tests, opens changes, records outcomes, and updates memory.
The quality of the system depends on information flow between these layers. Search should feed docs. Docs should feed search. Issues should feed memory. Memory should update docs. Static analysis should constrain retrieval. Execution should produce traces. Traces should become durable context.
Product strategy
The main product opportunity is repository representation. The interface can be chat, IDE, CLI, cloud agent, or documentation portal. The durable advantage comes from the project model underneath.
A strong product should do five things well.
First, it should keep context fresh. Local edits, branch switches, rebases, generated files, and remote commits all affect agent quality.
Second, it should expose evidence. Answers and patches should show files, symbols, searches, tests, and assumptions.
Third, it should preserve development memory. Completed work should produce issue capsules and subsystem doc updates.
Fourth, it should combine retrieval modes. Exact search, semantic retrieval, static structure, repository documentation, flow maps, and symbol explanations solve different parts of the problem.
Fifth, it should manage memory governance. Teams need visibility boundaries, source references, review workflows, expiration rules, and stale-memory detection.
The next generation of code intelligence will be judged by the quality of its repository model. The best systems will find code, explain architecture, guide edits, validate changes, and remember why the system evolved.