


Introduction
In our previous blog post, "LLM Evaluation Frameworks," we discussed the evolving landscape of evaluating Large Language Models (LLMs), highlighting Opik as a preferred framework due to its exceptional adaptability, particularly for reference-free metrics like G-Eval. This article expands upon that discussion by delving deeper into a pivotal innovation: the creation of custom datasets specifically optimized for LLM-based evaluation – G-Eval. By harnessing advanced LLM’s sophisticated, context-aware reasoning capabilities, these datasets enable richer, reference-free evaluations, setting the stage for even more accurate and insightful assessments of complex language tasks.
Recent advancements have ushered in a transformative shift toward employing LLMs themselves as evaluators. Moving beyond the constraints of traditional reference-dependent methods, LLM-based evaluators analyze the intrinsic qualities of responses, guided solely by contextual understanding and inherent knowledge.
LLM-as-a-Judge and Reference-Free Evaluation
In recent years, a quiet revolution has unfolded in the way we evaluate text generation tasks. Traditional evaluation methods, relying on metrics like BLEU and ROUGE, seemed reliable on the surface but often stumbled when it came to capturing the subtle creativity and diversity in language. Enter the era of "LLM-as-a-Judge," where Large Language Models (LLMs) step in as thoughtful, autonomous evaluators, leaving behind the constraints of conventional, reference-bound assessments.
Imagine a judge who doesn't compare an answer to an expected gold standard but instead thoughtfully analyzes the quality of a response based solely on context and inherent knowledge. That's precisely how LLM-based evaluators operate. They evaluate on the fly, assessing coherence, accuracy, and even subtle nuances as naturally as a human might.
A compelling example of this transformative approach is G-Eval: a novel framework that leverages the remarkable capabilities of GPT-4. With nothing more than a task description and clear evaluation criteria, the LLM meticulously deliberates through structured reasoning steps, eventually delivering a precise, form-filled judgment, complete with nuanced scores. It's a meticulous, transparent process that mimics human judgment, providing clarity and simplicity in evaluating complex, multi-dimensional tasks.
And the results speak volumes. When tested on tasks like text summarization, G-Eval demonstrated impressive alignment with human judgment, achieving a Spearman correlation of 0.514—far surpassing the performance of traditional overlap metrics. Simply put, the LLM's evaluations resonated more authentically with human perception than conventional methods ever could.
However, as with all groundbreaking advancements, there are caveats. Researchers acknowledge that these AI judges can occasionally exhibit biases, subtly favoring texts generated by other LLMs. Despite these limitations, the power of LLM-as-a-judge methods like G-Eval lies in their flexibility and their ability to assess texts without rigid reference points, paving the way toward more nuanced, robust, and genuinely insightful evaluations.
Building on this innovation, our approach introduces enhancements beyond the original G-Eval, incorporating even more powerful reasoning LLMs and a multi-model evaluation strategy. This combination reduces biases and further refines assessment accuracy, ensuring more robust, reliable, and nuanced evaluations, free from the constraints of traditional methods.
LLM-Based vs. Traditional Evaluation Approaches
The shift from traditional text evaluation methods to LLM-based evaluation is sparking an intriguing transformation in the field of NLP. Traditional metrics like BLEU, ROUGE, and METEOR have long relied on rigid, reference-bound comparisons, limiting their effectiveness in open-ended or creative tasks. These methods often miss the nuances of language—capturing surface similarity while overlooking deeper qualities like coherence, logical correctness, or creativity.
In contrast, the emergence of LLM-as-a-Judge offers a compelling alternative. These AI judges assess the quality of text independently, guided only by prompts or criteria, much like a human evaluator would. They navigate complexity effortlessly, weighing attributes like accuracy, relevance, and even style.
This innovative approach has demonstrated remarkable alignment with human judgments. For instance, LLM-based evaluations through G-Eval showed a significantly stronger correlation with human preferences compared to traditional metrics. Further advancements, including the use of even more powerful models and multi-model evaluation strategies, continue to enhance accuracy, reduce biases, and provide nuanced assessments.
Yet, the journey toward this flexible and dynamic method is not without challenges. LLM-based judges, driven by learned behavior, can carry inherent biases or exhibit subtle favoritism toward specific styles, AI-generated text, or models of the same architecture. Computationally, these models can also be resource-intensive compared to simpler overlap metrics, though ongoing developments promise to gradually mitigate costs.
The emergence of LLM-based evaluation raises the question: how do these AI judges compare to traditional evaluation methods? There are some clear contrasts:
Dependence on References: Traditional metrics require ground-truth reference outputs for comparison. Metrics such as BLEU, ROUGE, and METEOR strictly evaluate how closely a model’s output matches a human-written reference text. In tasks where many different answers could be correct (open-ended questions, dialogues, creative writing), this is a severe limitation – the reference might capture only one valid solution. LLM-based evaluators, in contrast, operate reference-free: they can judge an answer's quality based on criteria or prompts alone, without needing a fixed correct answer. This makes them far more flexible for evaluating open-ended generation and novel tasks.
Qualitative Nuance: Overlap metrics over-emphasize surface similarity and often miss nuances of meaning, logical correctness, or style. They struggle when an answer is fluent but incorrect, or when it is correct but phrased very differently from the reference. LLM judges, however, evaluate outputs more holistically like a human would – considering coherence, factual accuracy, relevance, and other subtle attributes as instructed. They excel in scenarios where multiple valid answers exist or creativity is required, providing a more nuanced assessment than a single-number metric based on n-gram overlap.
Correlation with Human Judgment: LLM-based metrics have shown significantly better alignment with human preferences on complex tasks. In the G-Eval study, GPT-4’s evaluations had a much higher correlation with human judgment of summaries than ROUGE did. Likewise, JudgeLM’s fine-tuned evaluator matched GPT-4 (and thereby human consensus) over 90% of the time. Traditional metrics often have only moderate correlation with humans in such settings, as noted in many studies. By effectively learning the human criteria from data (even synthetic data), LLM evaluators can outperform rigid metrics by a large margin in matching what humans consider “good” output.
Adaptability: Each traditional metric is generally built for a specific domain (e.g. BLEU for translation, ROUGE for summarization). Adapting it to new domains or criteria requires developing new benchmarks and often cannot capture things like factual accuracy or ethical considerations. An LLM judge, on the other hand, is essentially task-agnostic – it can be re-prompted or fine-tuned with new evaluation instructions to handle different domains or aspects. For instance, one can prompt an LLM to judge dialogue responses for empathy, or code answers for correctness, without collecting reference outputs for each case. This prompt-based adaptability is a huge advantage: evaluation can keep pace with evolving tasks by leveraging the general knowledge in LLMs.
Speed and Cost: Automatic metrics are fast and cheap to compute (just string matching or embedding comparison), whereas using large LLMs and/or reasoning LLMs as judges can be computationally costly. Fine-tuned smaller judge models (like JudgeLM-7B) offer a middle ground, running locally and judging thousands of samples in minutes. Over time, as open-source evaluators improve, the cost of LLM-based evaluation is expected to decrease. Currently, there is a trade-off: LLM-based methods are more powerful but can be slower/expensive, so they might be used selectively (e.g., to evaluate final results or difficult cases, while traditional metrics might still be used for quick approximate checks).
Potential Biases: Because LLM judges are learned, they can exhibit biases or errors not present in deterministic metrics. For example, an LLM judge might be more lenient to outputs written in a style similar to its training data, or it might have an “ego bias” where it favors text it generated or from its own model family. Recent work indeed found that LLM evaluators can have inflated opinions of AI-generated text (“narcissistic” evaluators) if not properly calibrated. Traditional metrics, while limited, are at least consistent and not prone to such favoritism. To address this, researchers introduce calibration techniques and debiasing data to improve fairness. Thus, trusting LLM-based evaluation requires careful validation – often by comparing back to human judgments on a sample – whereas traditional metrics, if imperfect, won’t deviate from their formula.
We address potential biases in part by using different models for generation vs. evaluation, and/or combining several models for both the dataset generation and for the evaluation.
Ultimately, the best path forward combines the nuanced power of LLM-based evaluations with the speed and consistency of traditional methods. By using AI judges selectively for critical assessments, alongside traditional metrics for quick checks, this hybrid approach ensures thorough, reliable evaluation at scale, narrowing the gap between automated methods and genuine human judgment.
Key Strategies for Synthetic Data Generation
Creating high-quality synthetic datasets for reference-free evaluation is both challenging and critical. In developing datasets specifically tailored for G-Eval, we focused exclusively on generating rich, diverse inputs—such as prompts, questions, and texts—without relying on reference outputs, answers, or labels.
One particularly effective strategy we've adopted is Diverse Prompting and Role-Play. Rather than using static or repetitive prompts, we encouraged the LLM to adopt varied roles and perspectives. This approach ensured our dataset captured a wide range of interpretive nuances and contexts, reflecting the diversity one would encounter in real-world evaluation scenarios.
Chain-of-Thought Prompting was another valuable method, though adapted to our reference-free context. By crafting prompts that explicitly asked models to consider step-by-step thought processes or multiple angles, we generated data rich in complexity and depth, enhancing the model’s ability to evaluate nuanced tasks without needing explicit reference answers.
Although approaches like Contrastive Output Pairing, Swap and Order Augmentation, and Reference Injection and Removal are not directly applicable to our dataset—since our reference-free datasets do not include answers or outputs—they remain influential prior work. These methods highlight important challenges such as positional bias or reference dependence, providing valuable insights for best practices in dataset generation.
Similarly, while Iterative Self-Improvement is not part of our current data creation strategy, it offers inspiration for future dataset development, suggesting how iterative refinement of input prompts could further improve dataset quality.
By carefully selecting and adapting these methods, we've successfully crafted reference-free datasets that enable robust and nuanced evaluation with G-Eval, setting a strong foundation for scalable and human-aligned automated assessment.
Detailed Evaluation Tasks, Metrics, and Dataset Criteria
Chat Evaluation
Overview: Evaluating conversational responses covering emotional, technical, and factual dimensions.
Metrics:
Toxicity: Measures harmful or inappropriate content.
Technical Nuance: Assesses precision and deep knowledge.
Empathy: Evaluates emotional supportiveness and sensitivity.
Fluency: Assesses readability, grammar, and coherence.
Dataset Criteria:
Topics range from quantum computing and TCP protocols to poetry and personal stress.
Includes potentially harmful requests, sensitive emotional content, and multi-turn discussions to ensure consistency and accuracy.
Question Answering (QA) Evaluation
Overview: Questions varying from simple facts to complex multi-step reasoning.
Metrics:
Multistep Reasoning & Reasoning Quality: Logical clarity and thoroughness in reasoning.
Technical Nuance: Correct use of domain-specific terms.
Empathy: Emotional understanding in sensitive contexts.
Factual Accuracy: Accurate and verifiable information.
Dataset Criteria:
Ranges from basic questions to deliberately tricky queries.
Incorporates emotional sensitivity, domain-specific precision, and subjective opinion questions.
Summarization Evaluation
Overview: Testing summarization quality across diverse content lengths and domains.
Metrics:
Summary Quality: Technical accuracy, completeness, conciseness, clarity.
Technical Nuance & Factual Accuracy: Precise representation of complex information.
Dataset Criteria:
Texts ranging from short to extensive.
Diverse topics including technical (AI, quantum mechanics) and non-technical (history, social issues).
Varied structures (essays, bullet points) and implicit vs explicit information to test summarization robustness.
Integrating Datasets with Evaluation Frameworks
Once you have a solid synthetic evaluation set, the next step is to integrate it into your evaluation pipeline. Modern tools like Opik make it easy to evaluate model outputs on multiple metrics using such datasets. Here’s how integration and multi-dimensional evaluation can be achieved, and why it’s so powerful:
Logging the Synthetic Dataset: Opik allows you to import or log your evaluation dataset (questions, model answers, etc.) into its system. Each data point can include all relevant info: prompt, the model’s response, the reference or expected “ideal” response if you have one, and any metadata. With your synthetic dataset loaded, you essentially have a reusable test bench for your LLM applications.
Defining Multi-Dimensional Metrics: The real strength of frameworks like Opik is handling multiple evaluation dimensions simultaneously. You can configure pre-built metrics or custom metrics for each aspect you care about. For instance, we set up a “Technical Nuance score”, a “Factual Accuracy score”, and a “Multistep Reasoning” metric. These can be powered by LLM judges under the hood. In fact, Opik comes with built-in LLM-based evaluators for complex aspects like hallucination detection, factual accuracy, or content moderation. So you could specify that for each response in the dataset, the system should call an LLM based judge to rate factuality and another to rate harmful content, etc. This means with one sweep over your synthetic data, you get a multi-dimensional report: how does the model perform on each criterion across all the examples?
One Dataset, Many Insights: By integrating the synthetic set into such a platform, you ensure that evaluation is consistent and repeatable. Every time your model changes (say you fine-tune a new version), you can re-run the same synthetic tests and see how the scores shift. Perhaps your new model is more factual (factuality score improves) but a bit less concise (relevance or coherence drops on some summaries) – multi-metric evaluation will catch that. The synthetic dataset’s breadth comes into play here: because you included diverse and challenging cases, the metrics will reveal strengths and weaknesses across different scenarios. This is much more informative than a single aggregate metric. It’s a true dashboard of performance.
Visualization and Analysis: Once the data and metrics are in Opik (or a similar framework), you typically get nice visualization tools. You can slice the results by category, look at specific examples where the model failed, and so on. For instance, you might filter to all the synthetic questions about math in your dataset and see if the correctness metric is lower there, indicating a weakness. This analysis can guide further dataset generation (maybe you’ll add more math questions) or model improvements. Essentially, integrating with a framework turns your synthetic dataset into a living benchmark that not only scores models but also guides development decisions.
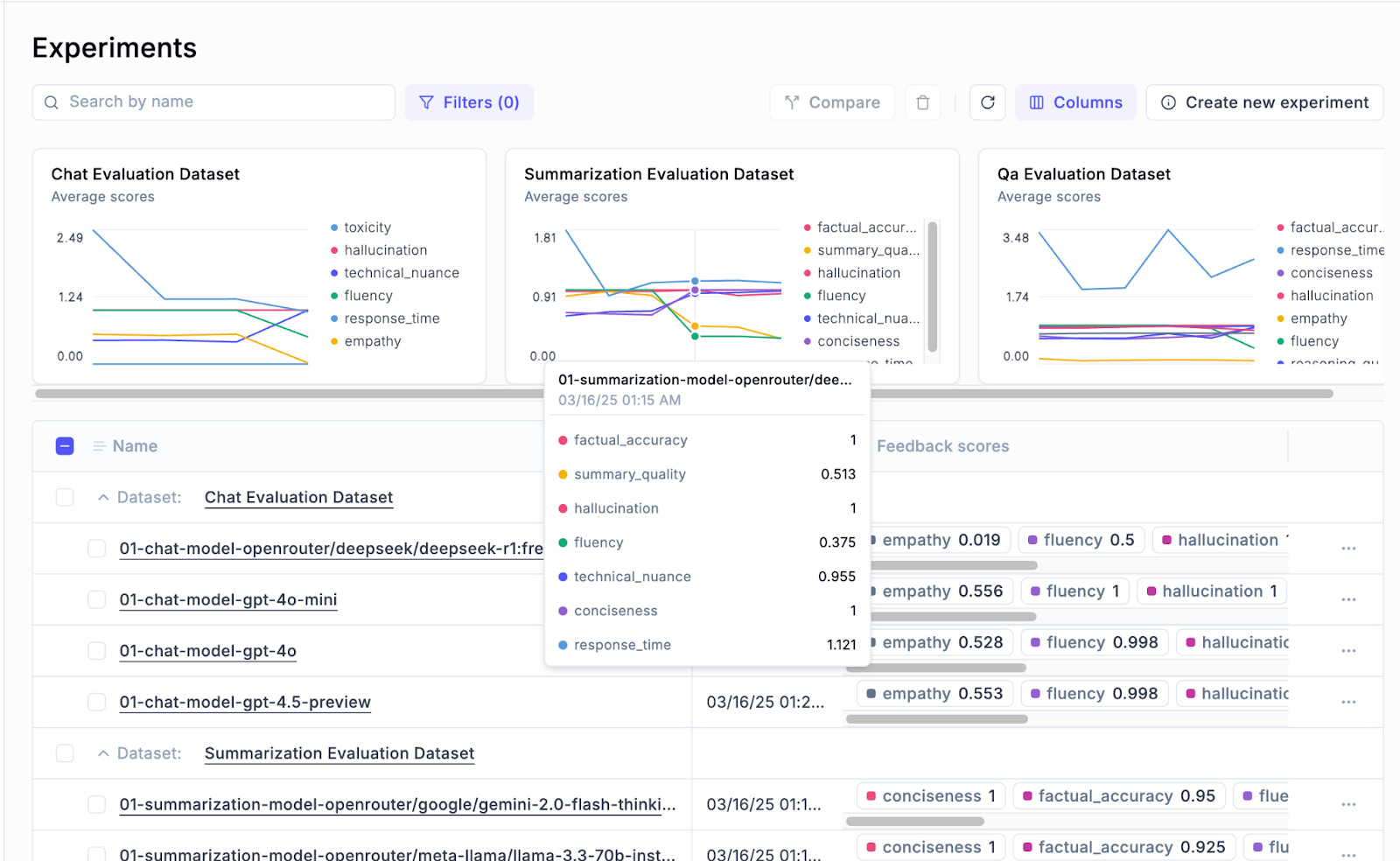
In summary, integrating your synthetic evaluation set with a multi-dimensional framework like Opik supercharges your evaluation process. It ensures that all the hard work you put into crafting diverse, relevant test cases pays off by yielding clear, structured insights. You get the benefits of automation (LLM judges doing the heavy lifting) combined with rich analysis (multi-metric
Repository and Community Engagement
The datasets and the evaluation suite are openly accessible to the community. Practitioners are encouraged to explore, provide feedback, and contribute:
Conclusion and Future Directions
Our journey into reference-free evaluation with G-Eval has opened up exciting new possibilities in automated text assessment. By crafting high-quality, diverse datasets that rely solely on rich, nuanced inputs—without needing reference outputs—we've demonstrated that evaluation can be both scalable and insightful, closely aligned with human judgment.
Throughout this work, techniques like Diverse Prompting and Chain-of-Thought have been particularly valuable in building comprehensive, context-rich datasets. However, recent insights suggest that future improvements might come from evolving the Chain-of-Thought prompting approach for both dataset generation and model response evaluation. Specifically, shifting from detailed chain-of-thought requests—as currently implemented in the original G-Eval and Opik’s implementation – to a more streamlined "Chain-of-Draft" reasoning process could enhance evaluation performance significantly while maintaining evaluation quality.
Looking forward, exploring iterative self-improvement methodologies and applying innovative variations like Chain-of-Draft will help ensure that G-Eval metrics become even more robust and aligned with nuanced human preferences. We will also explore expanding the scope to multimodal data. Our ongoing goal remains clear: continuously improving synthetic data generation techniques to provide flexible, powerful, and accurate evaluations for an ever-growing range of complex tasks.
References
Sher Badshah and Hassan Sajjad. Reference-Guided Verdict: LLMs-as-Judges in Automatic Evaluation of Free-Form Text.
Cheng-Han Chiang and Hung-yi Lee. A Closer Look into Automatic Evaluation Using Large Language Models.
Leonardo Gonzalez. LLM Evaluation Frameworks.
Li et al., From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge.
Li et al., Preference Leakage: A Contamination Problem in LLM-as-a-judge
Li et al., Awesome-LLM-as-a-judge: A Survey.
Liu et al., G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Wang et al., Self-Taught Evaluators.
Wu et al., Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge.
Xu et al., Large Language Models Are Active Critics in NLG Evaluation.
Xu et al., Chain of Draft: Thinking Faster by Writing Less.
Zhu et al., JudgeLM: Fine-tuned Large Language Models are Scalable Judges