

[Deep-Dive] One Document, Three Truths
Multi-Tenant Extraction That Adapts to Each Team

How do you transform a single-user prototype into a multi-tenant platform where Legal, Procurement, and HR teams can all use the same system, viewing the same documents but extracting different insights, without seeing each other’s data?
This is the deep dive into the workspace architecture that powers our contract intelligence platform’s multi-tenant transformation.
Why This Matters
Multi-tenancy isn’t just about “add a user_id column.” It’s about:
Data isolation: Legal can’t see HR salaries
Custom behavior: Same PDF, different extractions per team
Resource sharing: One database, one codebase, many tenants
Scalable onboarding: Add teams without code changes
Get it wrong and you either compromise security (data leakage) or scalability (database per tenant). Get it right and you have a platform that grows with demand.
Conceptual Model
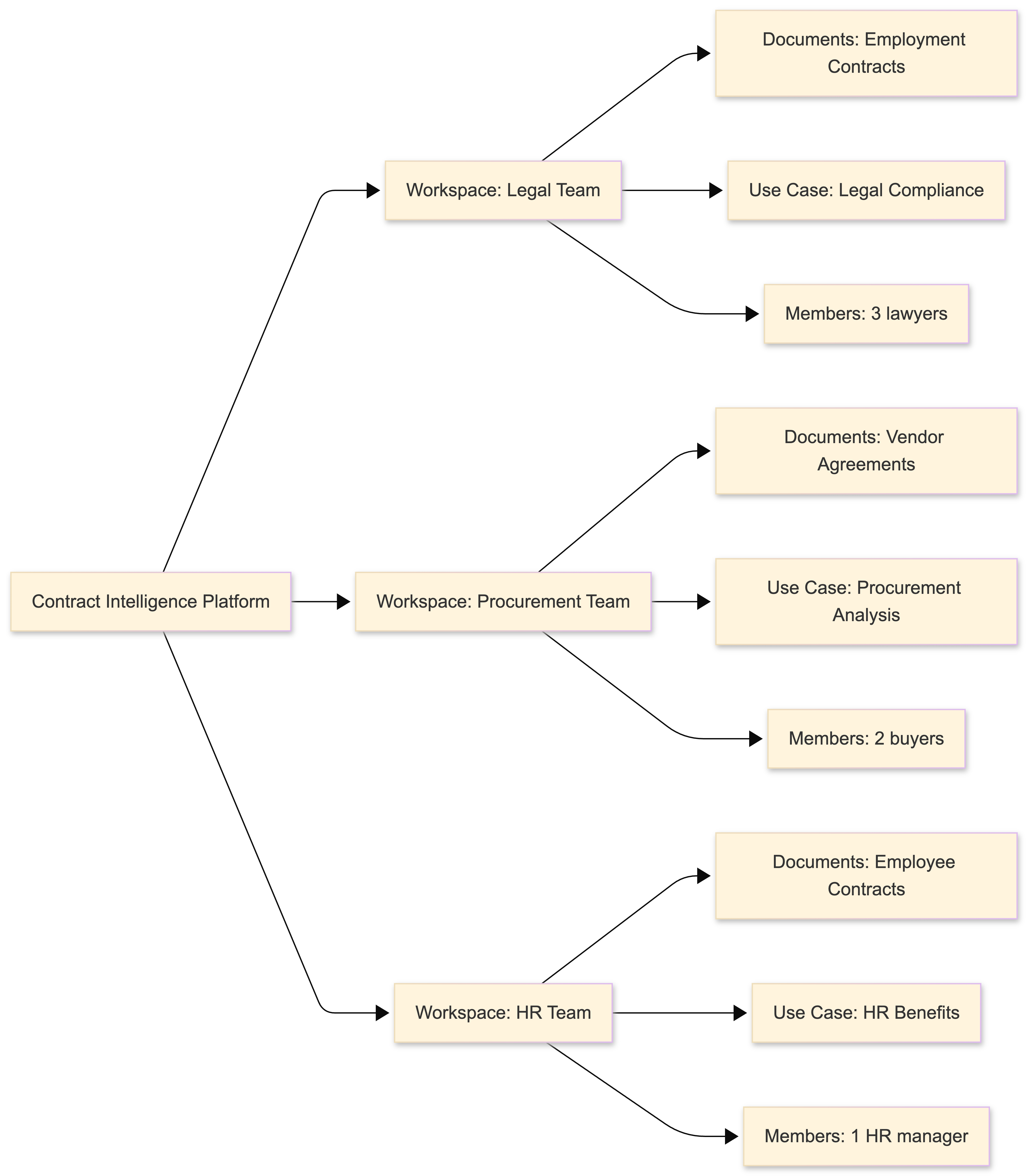
The Workspace Abstraction
A workspace is a logical container representing a team’s isolated environment for document analysis. Think “Slack workspace” or “Notion workspace”, separate data, separate members, separate settings.
Key properties:
Isolation: Data in Workspace A is invisible to Workspace B
Customization: Each workspace defines its extraction focus
Membership: Users belong to one or more workspaces with roles
Shared infrastructure: All workspaces use the same database and services
Use Cases: Beyond One-Size-Fits-All
The breakthrough insight: different teams want different extractions from the same document.
Consider an employment contract PDF containing:
Compensation details (salary, equity, bonuses)
Legal compliance clauses (arbitration, non-compete)
Benefits information (health, retirement, PTO)
Legal team cares about compliance clauses and risk assessment.
HR team cares about compensation structures and benefits.
Neither needs to see what the other extracts.
Use cases define this focus:
{
"legal": {
"name": "Legal Compliance Review",
"focus_areas": ["compliance", "liability", "termination", "confidentiality"],
"extraction_schema": {
"clauses": true,
"obligations": true,
"deadlines": true,
"risk_assessment": true,
"compensation": false // HR's domain
},
"chunk_strategy": "clause_boundary",
"embedding_focus": "legal_terminology"
},
"procurement": {
"name": "Vendor Contract Analysis",
"focus_areas": ["pricing", "sla", "payment_terms", "penalties"],
"extraction_schema": {
"tables": true,
"financial_terms": true,
"service_levels": true,
"vendors": true,
"compliance": false // Legal's domain
},
"chunk_strategy": "table_aware",
"embedding_focus": "financial_terminology"
},
"hr": {
"name": "Employment Terms Tracking",
"focus_areas": ["compensation", "benefits", "equity", "performance"],
"extraction_schema": {
"salary_bands": true,
"benefit_tables": true,
"vesting_schedules": true,
"pto_policies": true,
"legal_clauses": false // Legal's domain
},
"chunk_strategy": "table_aware",
"embedding_focus": "hr_terminology"
}
}The dynamic schema generator reads the workspace’s use case and adapts extraction accordingly.
Architecture
Database Schema Design
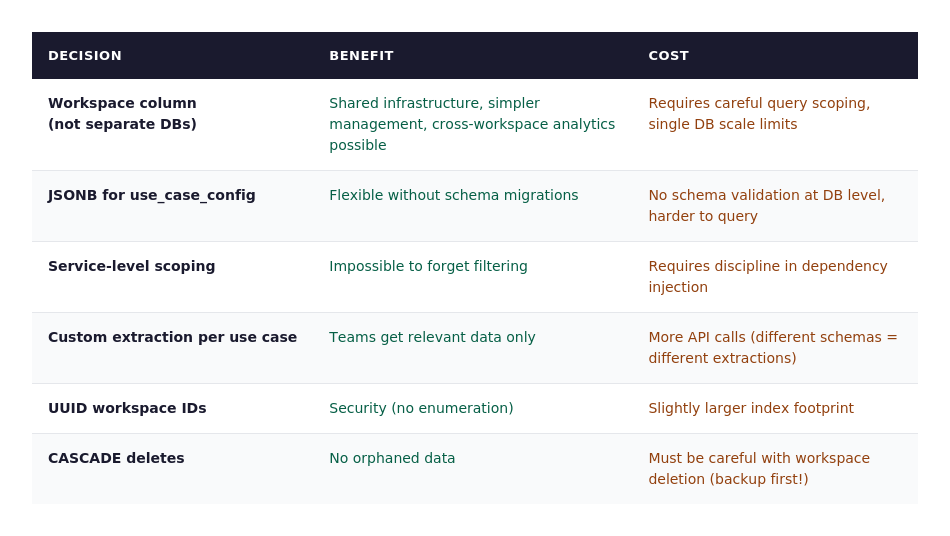
The core decision: workspace isolation via foreign keys, not separate databases.
-- ============================================
-- WORKSPACE TABLES
-- ============================================
CREATE TABLE workspaces (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name TEXT NOT NULL,
slug TEXT UNIQUE NOT NULL, -- URL-safe identifier
use_case_type TEXT NOT NULL, -- 'legal', 'procurement', 'hr', 'custom'
use_case_config JSONB, -- Custom extraction settings
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW(),
is_active BOOLEAN DEFAULT true
);
CREATE TABLE workspace_members (
workspace_id UUID REFERENCES workspaces(id) ON DELETE CASCADE,
user_id UUID REFERENCES users(id) ON DELETE CASCADE,
role TEXT NOT NULL, -- 'owner', 'admin', 'editor', 'viewer'
joined_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (workspace_id, user_id)
);
-- ============================================
-- MODIFIED CORE TABLES (add workspace_id)
-- ============================================
-- Documents
ALTER TABLE documents
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);
CREATE INDEX idx_documents_workspace
ON documents(workspace_id);
-- Graph entities
ALTER TABLE graph_clients
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);
ALTER TABLE graph_contracts
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);
ALTER TABLE graph_clauses
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);
-- RAG chunks
ALTER TABLE rag_chunks
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);
CREATE INDEX idx_rag_chunks_workspace
ON rag_chunks(workspace_id);
-- Extraction results
ALTER TABLE extraction_results
ADD COLUMN workspace_id UUID REFERENCES workspaces(id);Key design decisions:
UUID for workspace_id: Prevents enumeration attacks, allows distributed ID generation
ON DELETE CASCADE: When workspace deleted, all related data automatically removed (no orphaned records)
Indexed foreign keys: Every
workspace_idcolumn has an index for fast filteringJSONB for use_case_config: Flexible schema allows custom extraction parameters without schema migrations
Data Isolation Enforcement
Every database query MUST filter by workspace_id. We enforce this at the service layer, not the application layer.
❌ Bad (application-level filtering):
# In the route handler
@router.get("/documents")
def get_documents(workspace_id: UUID):
# Application code must remember to filter
docs = db.query(Document).filter(Document.workspace_id == workspace_id).all()
return docsProblem: Every route must remember to add the filter. Easy to forget = data leakage.
✅ Good (service-level scoping):
class WorkspaceService:
def __init__(self, db: Session, workspace_id: UUID):
self.db = db
self.workspace_id = workspace_id
def get_documents(self):
# Workspace scoping is automatic
return self.db.query(Document)\
.filter(Document.workspace_id == self.workspace_id)\
.all()
def get_contracts(self):
# Every method automatically scoped
return self.db.query(Contract)\
.filter(Contract.workspace_id == self.workspace_id)\
.all()Dependency injection pattern:
from fastapi import Depends
def get_workspace_service(
workspace_id: UUID, # From path or header
db: Session = Depends(get_db)
) -> WorkspaceService:
return WorkspaceService(db, workspace_id)
@router.get("/api/v1/workspaces/{workspace_id}/documents")
def get_documents(
service: WorkspaceService = Depends(get_workspace_service)
):
# Service is pre-scoped to workspace_id
return service.get_documents()Benefits:
Impossible to forget workspace filtering (it’s in the service constructor)
Route handlers are workspace-agnostic
Easy to test (mock the service with a test workspace_id)
Centralized authorization logic
Use Case Customization Implementation
When a workspace uploads a document, the extraction pipeline reads the use case configuration:
class DynamicSchemaGenerator:
def generate_schema(
self,
document_structure: dict,
use_case_config: dict
) -> dict:
"""
Generate extraction schema based on:
1. Document structure (discovery phase)
2. Workspace use case (what team cares about)
"""
base_schema = self._get_base_schema()
# Filter fields based on use case
focus_areas = use_case_config.get("focus_areas", [])
extraction_config = use_case_config.get("extraction_schema", {})
schema = {}
# Always include metadata
schema["metadata"] = base_schema["metadata"]
# Conditionally include extraction types
if extraction_config.get("clauses", False):
schema["clauses"] = self._generate_clause_schema(
document_structure,
focus_categories=focus_areas
)
if extraction_config.get("tables", False):
schema["tables"] = self._generate_table_schema(
document_structure,
focus_types=["pricing", "sla"] if "pricing" in focus_areas else None
)
if extraction_config.get("salary_bands", False):
# HR-specific extraction
schema["salary_bands"] = {
"type": "array",
"items": {
"role": "string",
"min_salary": "number",
"max_salary": "number",
"currency": "string"
}
}
return schemaExample: Legal workspace analyzing employment contract
Document structure (from discovery):
{
"tables_found": [
{"name": "Compensation Schedule", "columns": ["Role", "Salary Range", "Equity"]},
{"name": "Arbitration Procedures", "columns": ["Step", "Timeline", "Outcome"]}
],
"sections_found": [
{"title": "Non-Compete Agreement", "type": "legal"},
{"title": "Benefits Summary", "type": "hr"}
]
}Legal use case config:
{
"focus_areas": ["legal", "compliance"],
"extraction_schema": {
"clauses": true,
"tables": false,
"salary_bands": false
}
}Generated schema (Legal workspace):
{
"metadata": {...},
"clauses": [
{
"title": "Non-Compete Agreement",
"text": "Full clause text...",
"category": "legal",
"risk_level": "high"
}
]
// Compensation table NOT extracted (HR's concern, not Legal's)
}HR use case config:
{
"focus_areas": ["compensation", "benefits"],
"extraction_schema": {
"clauses": false,
"tables": true,
"salary_bands": true
}
}Generated schema (HR workspace):
{
"metadata": {...},
"tables": [
{
"name": "Compensation Schedule",
"rows": [...]
}
],
"salary_bands": [...]
// Non-Compete clause NOT extracted (Legal's concern, not HR's)
}Same document, different extractions based on workspace use case.
GraphRAG Workspace Scoping
The GraphRAG knowledge graph also respects workspace boundaries:
class GraphRAGService:
def __init__(self, db: Session, workspace_id: UUID):
self.db = db
self.workspace_id = workspace_id
def add_client(self, name: str, industry: str) -> str:
"""Add client to THIS workspace's graph"""
client = GraphClient(
name=name,
industry=industry,
workspace_id=self.workspace_id # Automatic scoping
)
self.db.add(client)
self.db.commit()
return client.id
def get_client_contracts(self, client_id: str) -> List[Contract]:
"""Get contracts for client in THIS workspace"""
return self.db.query(GraphContract)\
.filter(
GraphContract.client_id == client_id,
GraphContract.workspace_id == self.workspace_id # Isolated
)\
.all()
def search_clauses(self, query: str, top_k: int = 10) -> List[Clause]:
"""Semantic search across THIS workspace's clauses"""
query_embedding = self.embedding_service.generate(query)
results = self.db.query(GraphClause)\
.filter(GraphClause.workspace_id == self.workspace_id) # Scoped
.order_by(
GraphClause.embedding.cosine_distance(query_embedding)
)\
.limit(top_k)\
.all()
return resultsResult: Legal team’s graph contains legal clients and compliance clauses. HR team’s graph contains employees and compensation structures. No cross-contamination.
Trade-offs & Limitations
Performance Characteristics
Query Performance
With workspace filtering on every query, we added indexes:
-- Before: full table scan for every query
SELECT * FROM rag_chunks WHERE workspace_id = 'abc123...';
-- Seq Scan on rag_chunks (cost=0.00..15234.56 rows=82180)
-- After: indexed lookup
CREATE INDEX idx_rag_chunks_workspace ON rag_chunks(workspace_id);
-- Index Scan using idx_rag_chunks_workspace (cost=0.42..234.56 rows=27394)Impact: Query times reduced from ~2.5s to ~80ms for workspace-scoped chunk retrieval (82K chunks, 3 workspaces).
Embedding Generation
Different use cases generate different embeddings from the same text:
Legal workspace: “Non-Compete Agreement” → embedding focuses on legal terminology
HR workspace: “Compensation Schedule” → embedding focuses on HR terminology
We achieve this by prepending use case context to the text before embedding:
def generate_embedding(self, text: str, workspace_id: UUID) -> List[float]:
workspace = self.db.query(Workspace).get(workspace_id)
use_case = workspace.use_case_type
# Context-aware embedding
contextualized_text = f"[{use_case}] {text}"
return self.embedding_provider.embed(contextualized_text)Result: Semantically similar clauses cluster by use case, improving retrieval precision.
Implications
What This Enables
Rapid team onboarding: Add a workspace, define use case, start uploading no code changes
Role-based access: Legal sees legal contracts, HR sees employment agreements, no overlap
Custom extraction without custom code: Use case config drives schema generation
Cross-workspace insights (when authorized): Platform admins can analyze patterns across all workspaces
A/B testing extraction strategies: Create two workspaces with different use case configs, compare results
What This Blocks
Unlimited workspace creation: Each workspace increases query complexity (more data to filter)
Cross-workspace queries (without explicit permission): Can’t easily ask “show me ALL contracts in the platform”
Database-level encryption per workspace: Would require separate databases
Key Takeaways
Multi-tenancy is a spectrum: We chose workspace columns (light isolation) over separate databases (heavy isolation). Right choice for our scale.
Service-layer scoping prevents data leakage: Dependency injection with workspace-scoped services makes unauthorized access structurally impossible.
Use cases enable customization without custom code: JSON configuration drives schema generation, no per-team deployments needed.
Indexes are non-negotiable: Workspace filtering on every query requires indexed foreign keys or performance suffers.
Same document, different value: Dynamic extraction based on use case means teams extract what they need, not what we guessed.
Previously: Part 1 - From OCR to Intelligence
Next: Part 3 - Deploying Multi-Tenant Document Intelligence at Scale (deployment guide, migration scripts, ECS setup, production gotchas)