

[Case Study] “Negative Prompting” for Code Review. Hype or Real?
An experiment comparing three prompting strategies on a real database migration

A few days ago, a post went viral in AI circles claiming that negative prompting (telling the LLM what not to do) dramatically outperforms traditional instruction-based prompts for code review.
The claim: bug detection jumped from 39% to 89% using a prompt built entirely on negations. “Inhibition shapes LLM behavior more reliably than instruction.”
The prompt was elegant:
Do not write code before stating assumptions.
Do not claim correctness you haven't verified.
Do not handle only the happy path.
Under what conditions does this work?I was intrigued. But I also knew there were other prompting strategies in the research literature that might perform differently:
Negative Prompting: “Here’s what NOT to do” (the viral approach)
Positive Prompting: “Here’s what TO do” (checklists, success criteria)
Contrastive Prompting: “Here’s what a correct review catches vs. what a naive review misses”
So I ran my own experiment. I built a Claude Code skill that executes all three strategies against the same code, then compares results.
The finding: Negative prompting came in last.
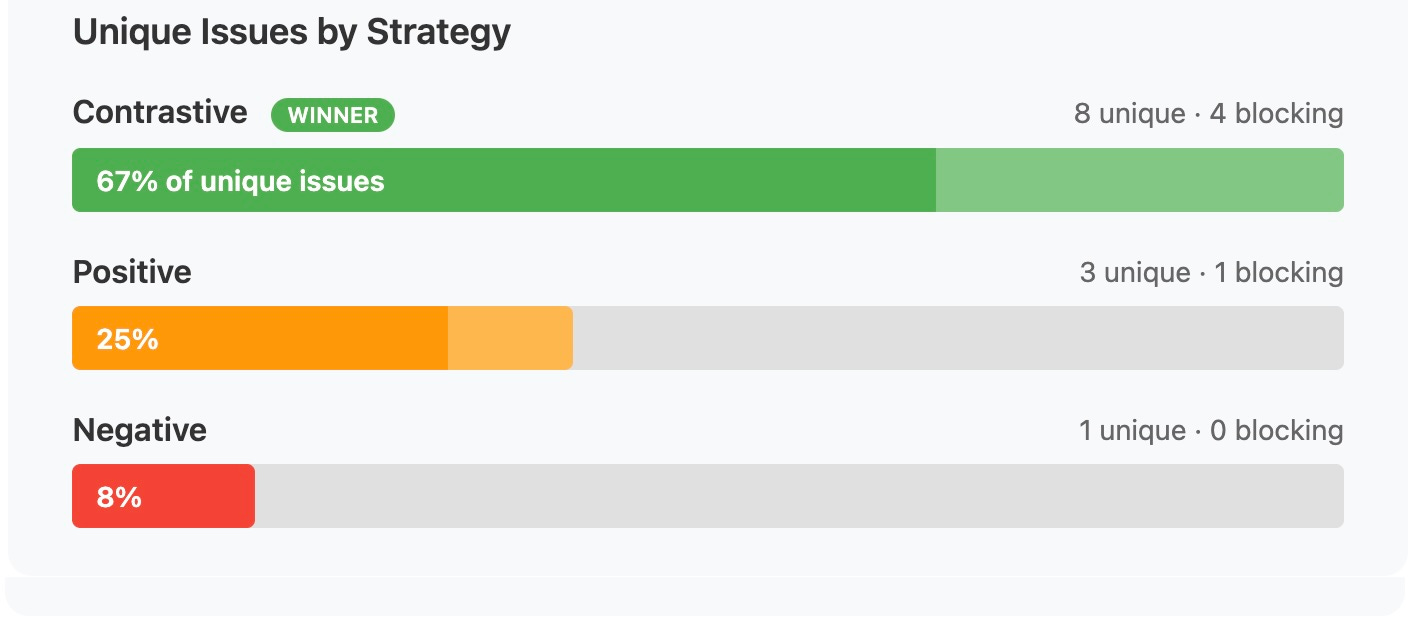
Contrastive prompting found 67% of the unique critical bugs. Negative found 8%.
Here’s what happened.
The Setup
The Test Subject
My implementation plan was genuinely risky:
Scope: Database migration + new graph architecture + GPU job queuing + multi-use-case extraction system
Data at risk: 48 clients, 102 contracts, 950 clauses (17MB total)
Constraint: Existing API consumers must work unchanged after migration
Length: 1,346 lines covering 7 phases over 9 weeks
If bugs made it to production, they could corrupt customer data or break integrations. A good test case for seeing whether prompting strategy matters.
The Three Strategies
Strategy 1: Contrastive Prompting
For each section of the plan, I had the model generate two reviews:
✅ “What a CORRECT review would catch”
❌ “What an INCORRECT/naive review would miss”
Then contrast the two to identify gaps.
Strategy 2: Positive Prompting
Create actionable checklists with explicit success criteria. Everything framed as “DO this” with specific verification steps.
Strategy 3: Negative Prompting
Establish hard boundaries with prohibited patterns. Show “wrong way” vs “right way” code examples.
Each strategy reviewed the same plan independently. Then a meta-analysis compared what each found.
The Results
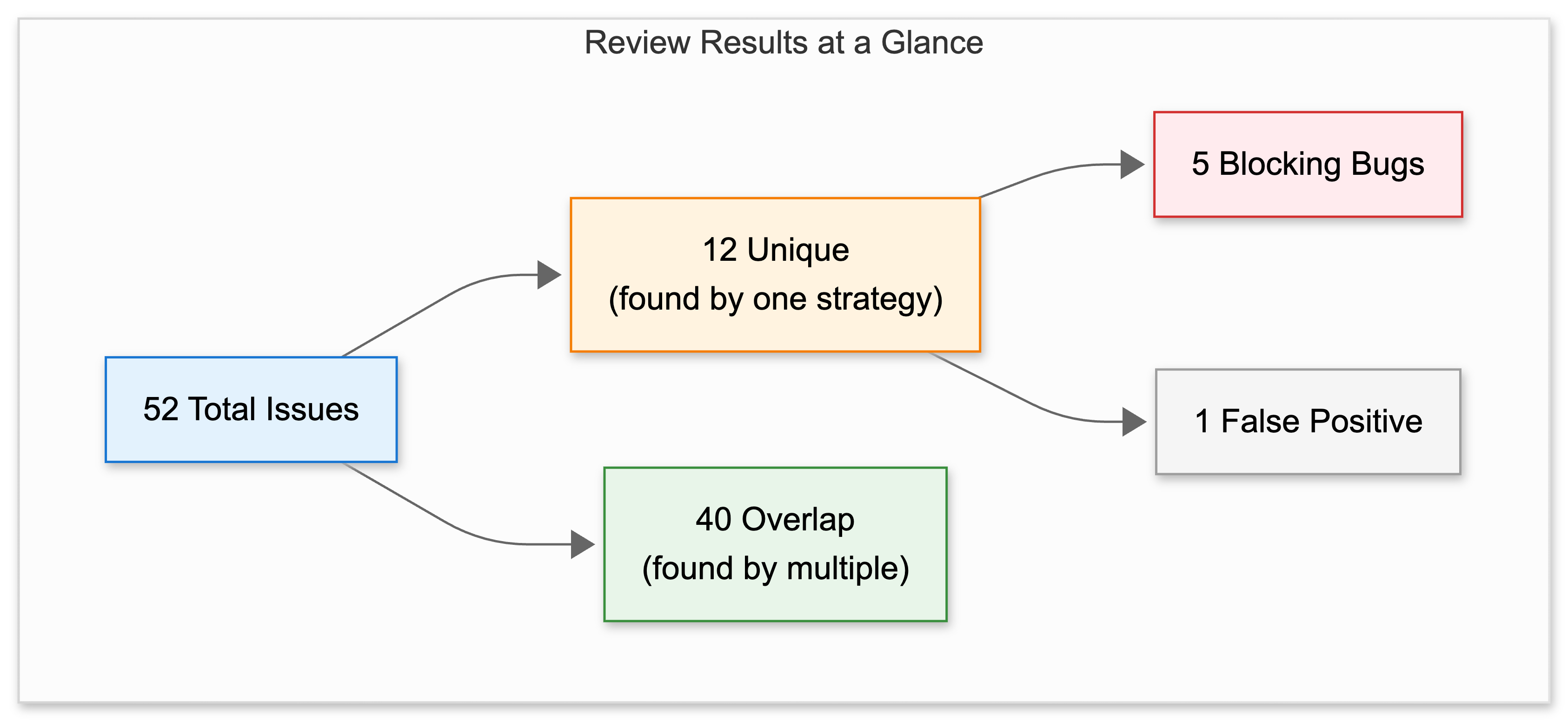
The three strategies flagged 52 issues total. Of those, 40 were found by multiple strategies (useful validation), but 12 were unique to a single approach. Five of those 12 would have broken production. Only one was a false positive.
Which Strategy Found What
Here’s where it gets interesting: Contrastive prompting found 8 of the 12 unique issues, including 4 of the 5 blocking bugs. Positive found 3 unique issues (1 blocking). Negative found just 1 unique issue (0 blocking).
That’s 67% of the unique critical findings from a single strategy.
The 40 overlapping issues are useful validation. When all three strategies flag the same thing, you can be confident it’s real. But the unique findings are where strategy choice actually matters.
The 5 Bugs That Would Have Broken Production
Let me walk through the blocking issues Contrastive found that the other strategies missed.
Bug 1: Silent Data Corruption
The plan’s original SQL:
UPDATE workspaces SET use_case_id = (SELECT id FROM use_cases WHERE name = 'contracts')
The problem Contrastive identified:
“A naive review assumes the subquery will always return a result. But if the use case doesn’t exist yet (migration order issue) or there’s a typo (’contract’ vs ‘contracts’), the subquery returns NULL. The UPDATE succeeds, setting ALL workspaces to use_case_id = NULL. No error. Silent data corruption.”
The fix:
SELECT id INTO STRICT contracts_id FROM use_cases WHERE name = 'contracts';
-- STRICT throws an exception if not exactly 1 row
This is the kind of bug that passes every test in staging (where the use case exists) and destroys production (where migration order might differ).
Bug 2: Migration Timeout Math
The plan called for:
for clause in clauses: # 950 clauses
await db.insert(clause) # Sequential inserts
Contrastive’s calculation:
“950 clauses × 50ms per insert = 47.5 seconds. Alembic’s default timeout is 30 seconds. This migration is mathematically guaranteed to timeout. Worse: it’ll fail mid-execution, leaving 600 clauses inserted. Retry hits unique constraint violations.”
Neither Positive nor Negative caught this. Positive generated a checklist item for “verify migration completes” but didn’t do the math. Negative prohibited “long-running transactions” but didn’t flag this specific pattern.
The fix: Bulk insert (950 rows in ~5 seconds instead of 47).
Bug 3: LLM Schema Hallucination
The system lets users generate extraction schemas via natural language. The plan included security validation (no code injection) and Pydantic validation (valid structure).
Contrastive identified the gap:
“User says ‘generate schema for medical records.’ LLM returns contract fields (parties, clauses, terms) because it’s been trained on lots of contract examples. Security validation passes (valid JSON). Pydantic passes (correct structure). But semantically? Garbage. User extracts 50 medical PDFs, gets contract fields, loses trust in the system.”
The fix: Add semantic validation that checks if schema fields match the stated use case.
Bug 4: Type Mismatch Across Services
The plan routed old use cases to the legacy service and new use cases to the new service:
if use_case_id == contracts_id:
result = old_service.process(...) # Returns ExtractionResult
else:
result = new_service.extract(...) # Returns ExtractionAuditTrail
return result # 💥 Different types!
Contrastive:
“Python’s type system allows this at compile time. Existing API consumers expect ExtractionResult with a
.datafield. ExtractionAuditTrail has.extraction_result. AttributeError in production. All contract extractions break.”
Bug 5: Retry Storm During Outages
if not success and retries < max_retries:
await asyncio.sleep(300) # Always 5 minutes
retry()
Contrastive’s scenario:
“GPU VM goes down for 1 hour. Job retries every 5 minutes: T+5, T+10, T+15... T+55. Twelve retry attempts, all during the outage window. GPU comes back at T+60, but job already exceeded max retries and failed. User has to resubmit manually.”
The fix: Exponential backoff with jitter.
What Negative Prompting Did Catch
To be fair, the Negative strategy wasn’t useless. It found one unique issue the others missed: encoded injection variants.
While Contrastive and Positive focused on the obvious __import__ injection pattern, Negative flagged that attackers could hex-encode or URL-encode the same payload to bypass naive string matching. That’s a real security insight.
Negative prompting excels at this: pattern-matching against known attack vectors. It just couldn’t reason about my specific architecture’s failure modes.
Why Did Contrastive Win (and Negative Lose)?
This contradicts the Code Field research, so I spent some time thinking about why.
The Code Field experiment tested code generation, not plan review.
Their 39% → 89% improvement was on bug detection in code the LLM was writing. The negative constraints (”do not handle only the happy path”) force the model to pause before generating, surface assumptions, and consider edge cases as it writes.
My experiment was different. I gave the model an existing 1,346-line plan and asked it to find bugs someone else wrote. That’s a review task, not a generation task.
For review, you need the model to reason adversarially, not just inhibit bad habits.
Negative prompting says “don’t do X.” That’s useful when the model is about to do X. But in review, the model isn’t generating code; it’s analyzing code. The failure mode isn’t “rushing to a solution.” It’s “not imagining how this could break.”
Contrastive prompting directly addresses this. When you ask “what would a naive review miss?”, you’re forcing adversarial reasoning. The model has to:
Imagine the naive reviewer’s assumptions
Identify what they’d skip
Explain why that matters
That’s a fundamentally different cognitive task than “don’t claim correctness you haven’t verified.”
Negative prompting caught known anti-patterns; Contrastive found novel failure modes.
The Negative strategy was excellent at flagging things like “don’t use raw SQL strings” or “don’t skip input validation.” These are patterns it’s seen before.
But it couldn’t do the timeout math (950 clauses × 50ms = guaranteed failure). It couldn’t reason about the semantic mismatch between “medical records” and contract extraction schemas. Those require domain-specific reasoning, not pattern matching against prohibited behaviors.
My takeaway: the right strategy depends on the task.
Writing code? Negative prompting helps you slow down and state assumptions.
Reviewing code for known vulnerabilities? Negative prompting catches anti-patterns.
Reviewing code for novel bugs in your specific domain? Contrastive prompting reasons about failure modes.
Honest Limitations
A few caveats before you run off to build your own Cerberus:
I only tested one plan. N=1 is not statistical significance. These results might not generalize.
The “blocking bugs” classification is my judgment. Would these have actually hit production? Maybe unit tests or staging would have caught some. I’m confident about the silent SQL failure and the timeout math. Less certain about the others.
I don’t know the false negative rate. The strategies found 12 unique issues. How many did all three miss? No idea.
Token costs are real but modest. Total: ~29,000 tokens across all strategies. At current Claude rates, that’s about $0.20 in API costs. The human time to review findings (~2.5 hours) is the real cost.
When Would I Use This?
Use all three strategies for:
Database migrations with production data at risk
Architecture changes affecting multiple services
Anything where a production failure costs more than a few hours of engineering time
Use just Contrastive for:
High-risk changes when you’re short on time
Security-sensitive code (combine with Negative for defense-in-depth)
Use just Positive for:
Pre-deployment checklists
Onboarding new team members to a codebase
When you need actionable steps, not bug-finding
Skip AI review entirely for:
Small bug fixes
Documentation changes
Anything where the review time exceeds the fix time
The Skill (If You Want to Try It)
I packaged this as a Claude Code skill called Cerberus. It:
Takes an implementation plan or code diff as input
Runs all three prompting strategies
Generates a meta-analysis comparing what each found
Outputs prioritized recommendations
To install:
git clone https://github.com/dp-pcs/claude-skills-public.git
cp -r claude-skills-public/cerberus ~/.claude/skills/The core insight isn’t the skill itself. It’s that prompting strategy matters for code review, and Contrastive prompting seems to find bugs the others miss.
If you try it on your own code, I’d be curious what you find. Does Contrastive still win? Are there domains where Negative or Positive outperform? Let me know.
Key Takeaways
Prompting strategy matters, but so does the task. The Code Field research showed negative prompting helps with code generation. My experiment suggests contrastive prompting works better for code review. Different cognitive tasks, different optimal approaches.
Contrastive prompting found 67% of unique critical issues by forcing the model to reason about what naive reviews miss. It’s not just “find bugs.” It’s “imagine the shortcuts someone would take and explain why they’re dangerous.”
Negative prompting excels at known anti-patterns. If you’re checking for SQL injection, input validation, or other well-documented vulnerabilities, negative constraints work well. For novel, domain-specific bugs? Less so.
Overlapping findings increase confidence. 40 issues flagged by multiple strategies = low false positive rate. When all three agree, it’s probably real.
The strategies compose well. My best results came from running all three: Contrastive for novel bugs, Positive for verification checklists, Negative for security boundaries. ~$0.20 in API costs for comprehensive coverage.
The Code Field research is worth reading. Their prompt design is clever and their results on code generation are solid. But “inhibition shapes behavior more reliably than instruction” might be task-dependent. For review, I’d bet on reasoning over inhibition.
I appreciate that you actually tested it out rather than just accept a Twitter narrative. Layering them makes sense, but even still, LLMs still allow a lot of defects pass through in the code they write. It's a constant battle.