

[Case Study] Engineering Determinism for Image Generation
A Multi-Stage Pipeline for Verifiable Generative AI


Engineering Consistency: A Deterministic Pipeline for Generative AI
We were recently tasked with a critical objective by senior technical leadership: deploy a generative image workflow capable of adhering to strict numerical constraints. The requirement was precise compositional fidelity—specifically, the ability to generate images with exact object counts every single time.
In our testing, standard generative workflows failed to meet this standard. We identified two distinct technical bottlenecks. First, Generative Hallucination, where diffusion models produce probabilistic approximations rather than exact counts. Second, Perceptual Blindness, where standard vision models fail to verify counts when objects are partially occluded or overlapping. To address these limitations, we moved beyond prompt engineering and architected a deterministic platform.
We decoupled generation from verification, treating the generative model as an unreliable component that must be audited by a separate, specialized Vision-Language Model.
The result is a system that transforms a probabilistic roll of the dice into a guaranteed output, often completing the entire validation cycle in seconds.
Part 1: Strategic Model Selection
Our analysis of the current VLM landscape revealed that no single model currently possesses both the high-fidelity generation capabilities and the spatial reasoning required for accurate verification. Consequently, we engineered a composite system selecting specialized models for each stage of the pipeline.
Optimized Generation
For the creative engine, we implemented a multi-provider strategy to balance speed, cost, and control.
Google’s Gemini 3 Pro Image Preview serves as our high-speed premium tier. In our internal benchmarks, this model demonstrated remarkable velocity, consistently generating high-fidelity assets in under 10 seconds. This speed allows us to run multiple generation attempts in the time it takes standard models to finish a single pass.
Recraft V3 (via Fal.ai) and GPT-Image-1 serve as our engines for modification. Unlike Gemini, which currently lacks a public editing endpoint, these models allow us to mask and modify existing images. This is a critical feature for consistency, as it allows the system to perform precise edits without discarding the original composition.
The Verification Layer
The most significant barrier to consistent counting is partial occlusion. Our research into the CAPTURe benchmark highlighted a critical gap. While human error on occluded counting tasks is merely 3.79%, top-tier generalist models often exhibit error rates approaching 15%. They frequently fail to apply amodal reasoning, the ability to infer the presence of a whole object from visible parts.
To mitigate this, we deployed Qwen3-VL (via OpenRouter) as our primary auditor. We specifically selected the qwen3-vl-235b-a22b-instruct variant because of its advanced architectural focus on spatial awareness. Unlike standard text-centric models, this model utilizes specialized positional encodings that distribute frequency information across time, height, and width, providing the superior localization required to resolve overlapping objects that confuse standard models.




Part 2: The Self-Healing Workflow
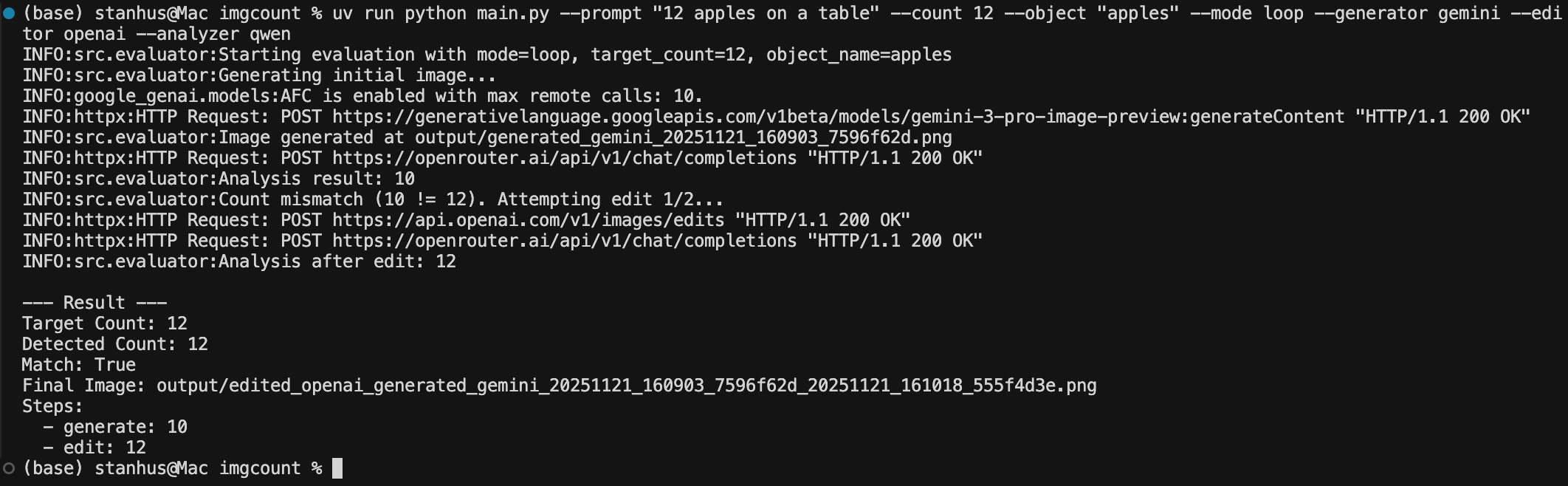
The true power of this platform lies in its automation. We implemented the solution as a modular harness designed to enforce determinism through a Generate > Analyze > Edit loop. This turns the pipeline into an autonomous agent that refuses to accept incorrect outputs.
The Audit Protocol
Once an image is generated, it is immediately passed to the Qwen3-VL auditor. Crucially, we do not rely on the VLM’s conversational text capabilities, which can be ambiguous and slow to parse. Instead, the system enforces a Hybrid Parsing Mechanism:
Primary: We instruct the model to return a strict JSON object containing the count.
Fallback: If the model deviates into conversation, a regex failsafe extracts the first integer found in the response.
This dual-layer approach ensures the audit step is both robust and adds negligible latency to the pipeline.
The best result was really the objects counter in the generated image, which was correct 100% of the time.
Autonomous Correction
If the detected count differs from the target, the system does not simply discard the image or alert a human. It engages Loop Mode.
In this state, the system constructs a targeted programmatic prompt and calls the OpenAI or Recraft editing endpoints. It acts with surgical precision, generating a new version of the asset with objects added or removed as needed. The loop updates its internal state to track this new file and re-submits it for verification. The cycle repeats until the verification passes or retries are exhausted.
Conclusion
By acknowledging the inherent limitations of current generative models regarding spatial reasoning and occlusion, we transitioned our workflow from a probabilistic process to a verified pipeline. This platform ensures that business requirements for compositional accuracy are met programmatically, auditing every asset before final delivery. Most importantly, with a very few iterations we could do the large-scale data generation and evaluation and see how it goes. It will probably be much better than anything that was tried before.
P.S. Want a detailed Deep Dive? Engage in the comments below and Leonardo Gonzalez will share his deeply technical and well-crafted benchmarks!