

Analyzing Large Datasets with LLMs
How to Tame Context Limits, Retrieve Structured Data, and Build Reasoning Agents for Enterprise-Scale Insights

Introduction: Why LLMs Struggle with Real-World Data
LLMs are great with words, but weak with math and worse with scale. That’s a problem when your job involves analyzing millions of rows of structured data, for example financial ledgers.
Even small mistakes in reasoning can have big consequences in domains like finance. Hallucinations, missed joins, or fuzzy logic just don’t cut it when accuracy is non-negotiable.
In this study, I explored practical strategies for using LLMs in high-stakes, structured-data environments - especially SQL-based financial systems.
Why SQL and Structured Data Matter
For this research, the focus is on structured data, specifically, datasets stored and accessed via SQL.
SQL remains the most common interface for querying data across industries. Financial systems, in particular, rely on relational databases to store everything from transactions and time-series prices to ledger entries and customer data. Whether it's Postgres, Oracle, or Snowflake, the language of business data is SQL.
So rather than tackling unstructured or document-based pipelines, I zeroed in on two tightly linked challenges:
Text-to-SQL: Can an LLM correctly translate a user’s question into a valid, accurate SQL query?
Post-retrieval analysis: Once the data is retrieved, can the LLM interpret, analyze, and explain it with clarity and factual accuracy?
Core Challenges: Why This Isn’t Just Prompt Engineering
Applying LLMs to structured, large-scale data isn’t a simple case of writing a better prompt. There are two core problems that must be addressed:
Context Window Limits
LLMs can’t "see" full datasets. Even with large context models (like gemini-2.5), enterprise data typically far exceeds what fits in a single prompt. Feeding raw tables or query results directly into the model isn’t viable at scale.
Probabilistic Reasoning
LLMs generate answers based on patterns, not guarantees. That means:
Inaccurate SQL: Incorrect joins, column names, or logic
Factual errors: Misinterpreting retrieved data
Fluff: Generic or vague analysis that sounds good but adds no value
Together, these make financial analysis especially tricky. You need to ensure the model gets the right data and says the right things about it.
Two Problems, One Pipeline
The problem can be generally broken down into two buckets:

1: Text-to-SQL - Getting the Right Data
The first challenge is translation. Can the LLM turn a natural language question like:
“What was the average transaction size for customers in the North region in 2023?”
…into a valid, accurate SQL query that respects the schema, joins, and filters.
Common failure modes:
Missing or incorrect table/column names
Invalid joins due to missing foreign keys
Misunderstood business logic (“active customer” ≠ “non-null login date”)
2: Post-Retrieval Analysis – Making It Mean Something
Once the right data is fetched, the next challenge is interpretation. Can the LLM:
Summarize or compare results meaningfully?
Spot trends, anomalies, or outliers?
Context size management
Avoid hallucinating explanations or inventing metrics?
This is where many models default to surface-level fluff: generic phrasing, vague conclusions, or shallow interpretations. In finance, that’s not just unhelpful; it’s actually risky.
Both steps need to work together. Retrieval without analysis is just reporting. Analysis without accurate retrieval is fiction.
🛠️ End-to-End Candidate Tool: PandasAI
One quick way to implement the entire pipeline is with PandasAI. It allows you to ask questions in natural language about a Pandas DataFrame. Under the hood:
The LLM translates the question into SQL
The code is executed on your full dataset, and filters down the required data
The library outputs results into charts and text
While I had looked separately into Text-SQL conversion, I wanted to evaluate this tool from the Y-combinator backed startup.
To test this approach, I used:
Backend LLM: OpenAI GPT-4o
Data: Cleaned version of the Oklahoma State General Ledger
Evaluation Set: 300 natural language questions requiring descriptive or comparative analytics
Each result was reviewed for accuracy of output against the evaluation dataset:



Pandas-AI Results Summary

The results were inconsistent, with outputs varying widely from run to run on the same data.
While this open source tool has a simple API and is interesting to play with, it can hardly be used for rigorous datascience use cases with this kind of variability in output
To gain better control over output accuracy, we dig into the two problems separately
Problem 1: Text to SQL
I ran a series of experiments to find an effective text to SQL setup, and used two different benchmark datasets:
Benchmark 1: Book SQL - Finance Dataset, Text-to-SQL
BookSQL is a large-scale (100K) Text-to-SQL dataset focused on the finance and accounting domain, designed to train systems that can handle diverse accounting databases across 27 industries.
Ledger-style relational schemas (e.g.,
accounts,entries,transactions)Business-style queries like "What was the total income in Q4 for account type X?"
Complex joins and temporal filters typical of finance systems
It should be noted that Book SQL is a research-only dataset, offered by the Association for Computational Linguistics, Mexico
Benchmark 2: Oklahoma General Ledger - FY 2024
This is an open dataset, containing a general ledger for the state of Oklahoma. For the purpose of this evaluation, I merged the quarterly datasets for the year into a single one, with a row count of 1.27M.
Text-to-SQL Eval Setup 1: BookSQL with XiYanSQL
The first evaluation uses a state of the art open source model for text to SQL.
Dataset: Book SQL
Model: XiYanSQL, a fine tuning on the QwenCoder-32B LLM
Base model: QwenCoder-32B, a code-centric LLM with structural reasoning strength
Fine-tuned on large-scale SQL generation datasets including Spider, Bird, and BookSQL
The model has a leaderboard-topping performance on Spider, and was expected to generalize well.
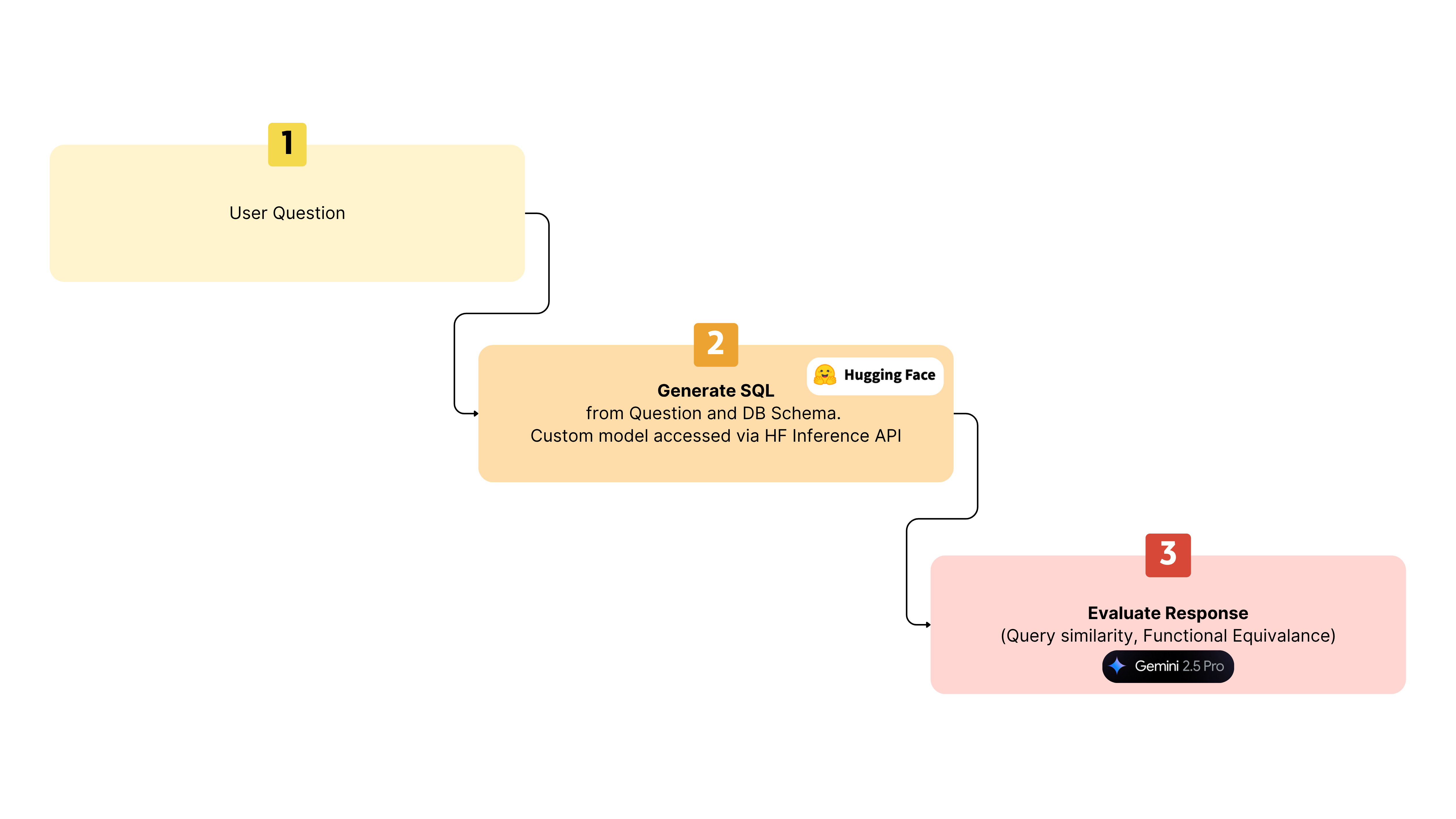
For each question in the benchmark dataset, the XiYanSQL model was used to generate an SQL query, via a custom deployment on Hugging face. The resulting SQL query was then evaluated using Gemini 2.5 pro. Additionally, I compared this against the vanilla Open AI models to evaluate relative accuracy.
Evaluation Results
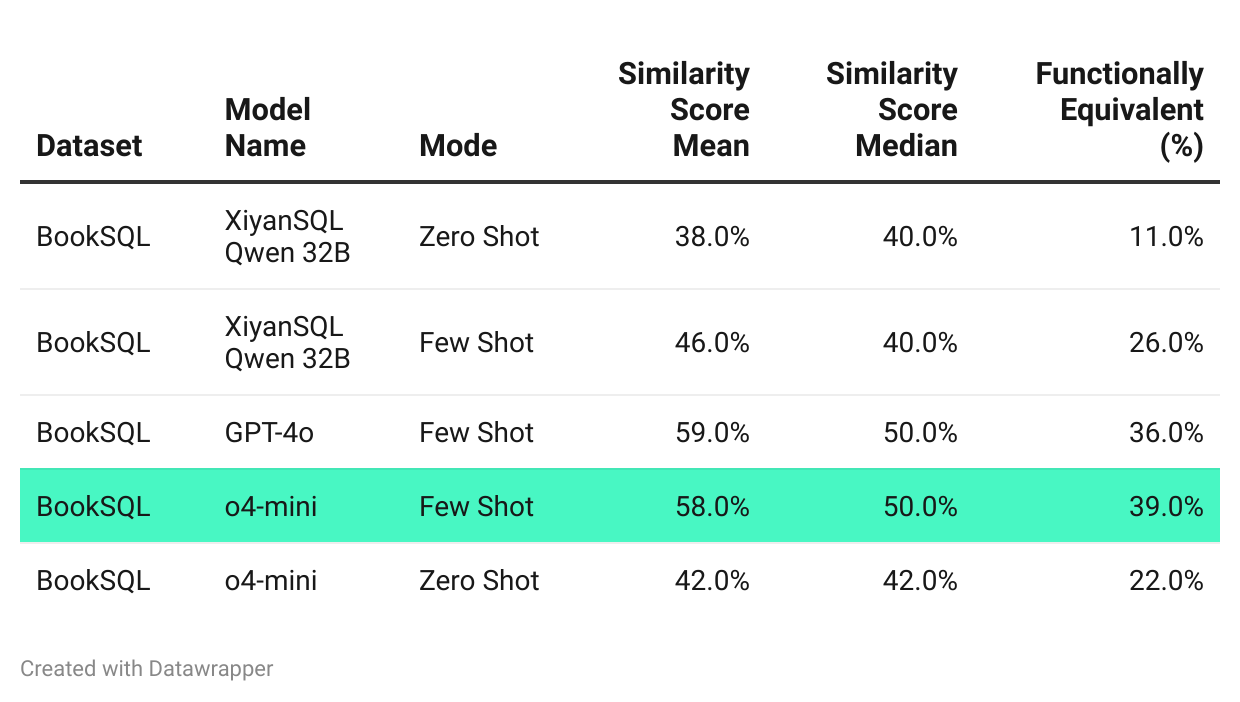
These results fall well short of the 90%+ benchmarks reported on Spider.
Open AI’s o4-mini did significantly better than the rest with few-shot prompting
Despite XiYanSQL’s strong performance on general-purpose benchmarks, it struggled with BookSQL. The likely reasons:
Domain overfitting: The model may be tuned for Spider’s schemas and question styles.
Financial data complexity: Temporal logic, custom KPIs, and account hierarchies are infrequent in general SQL datasets.
Semantic mismatch: Terms like "income", "balance sheet", or "retained earnings" carry domain-specific logic not captured in training.
Text-to-SQL Eval 2: Oklahoma State Ledger, with OpenAI Models
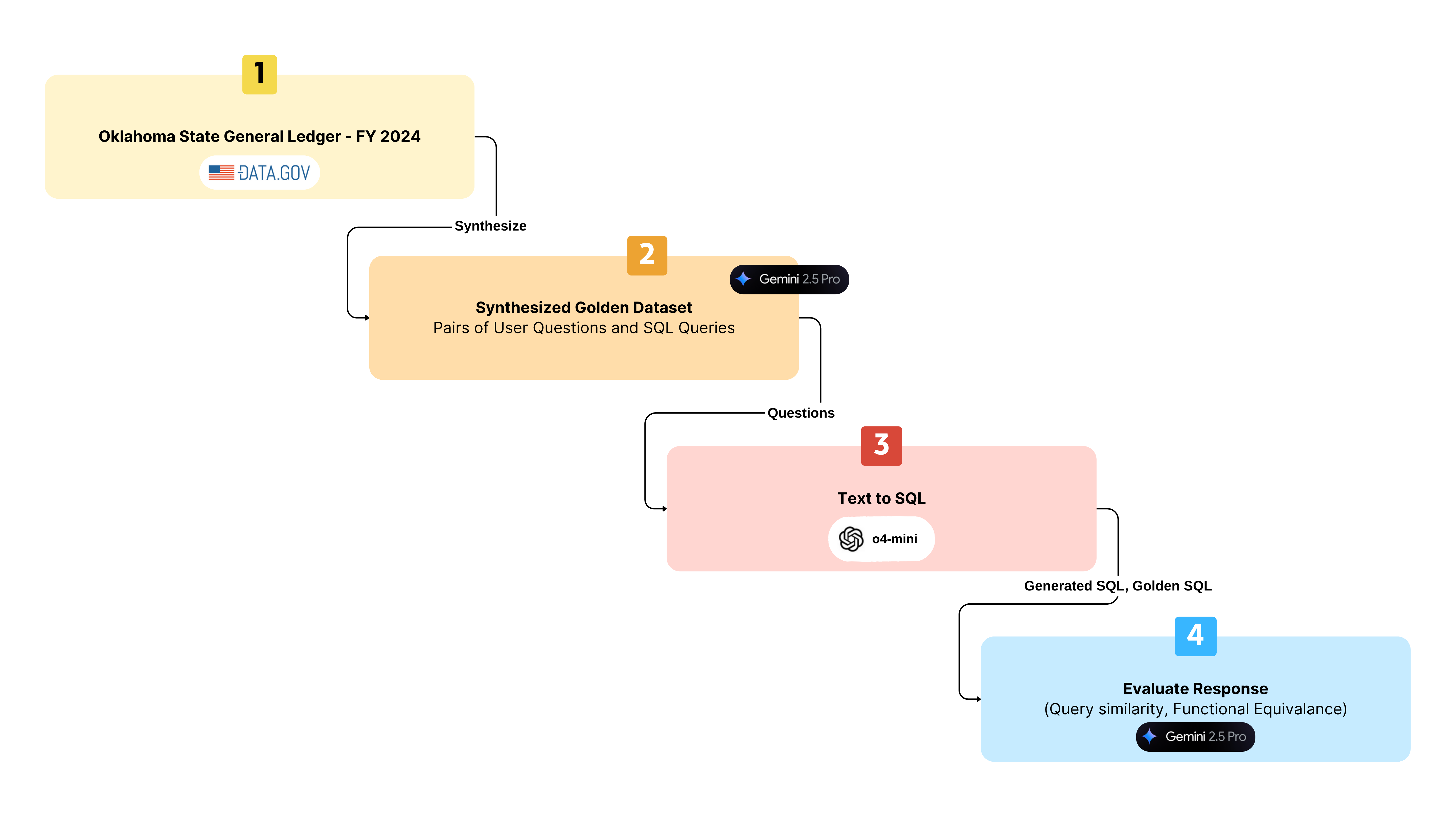
For the second evaluation, I synthesized my own golden dataset, based on the Oklahoma state ledger.
Dataset: State of Oklahoma’s general ledger - FY‘24
~1.3M rows spanning multiple quarters
A real-world schema that mirrors enterprise-grade accounting systems
Synthesized a 300-query golden dataset
Model: OpenAI GPT-4o and o4-mini
Modes:
Zero shot
Few Shot
Fine tuned with 500 records
Evaluation Results
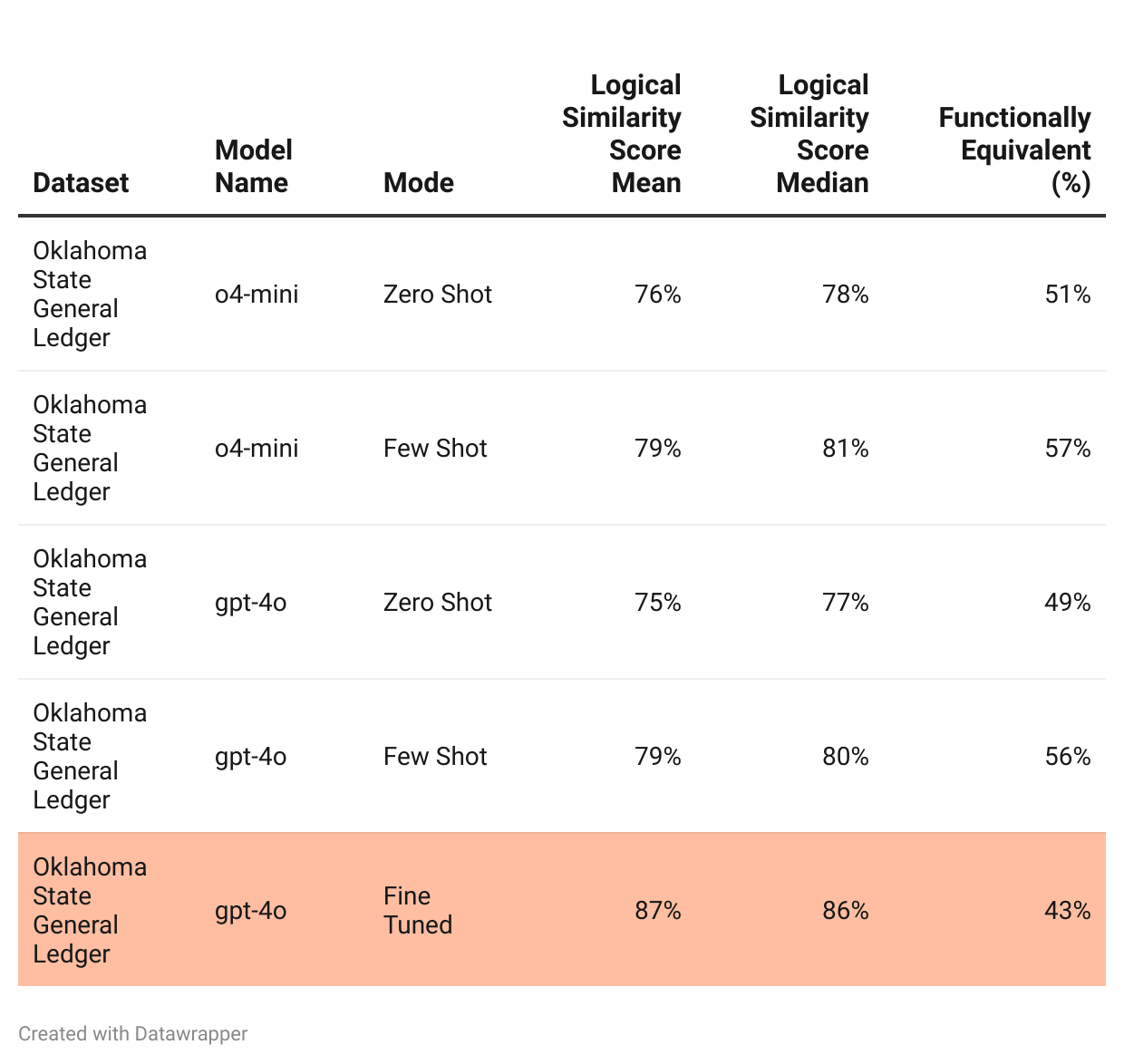
Few-shot prompting offered a significant improvement over zero-shot.
Fine-tuning showed a very curious behavior
It yielded better logical similarity compared to zero shot and few shot tests
But the functional equivalence dropped significantly
This evaluation also reinforces the need for task-specific, domain-tuned training.
My fine tuning dataset of 500 records was likely inadequate in size and quality
Text-to-SQL Takeaways
1. Leaderboards Are Subject to Interpretation. Domain Reality Is Diffferent
XiYanSQL crushed Spider, but crumbled on BookSQL. Why? Leaderboard supremacy doesn’t equal real-world robustness. Models fine-tuned on synthetic academic datasets can’t handle the semantic messiness of domains like finance.
2. Financial SQL Is a Different Species - Not Just Bigger, But Smarter
BookSQL broke the model not because it’s large - but because it's layered. KPIs, hierarchies, temporal joins, and accounting nuance - That’s beyond what most open-source SQL models ever see.
3. Fine-Tuning Is a Strong Option, But Requires Precision Work
The Oklahoma Ledger experiment shows the fine-tuned GPT-4o improved logical similarity but hurt actual correctness. Why? The 500-record dataset likely taught the model to “think like the data,” but not “answer like the truth.” This is a critical insight: fine-tuning without golden supervision can build confident wrongness.
4. Error-Aware Prompting Is the Sleeper Agent of SQL Gen
Prompting with execution errors (and recovering intelligently) gave real-world lift. That’s a feedback loop the benchmarks ignore. Academic evals don’t test how models self-correct, but production systems must. This is the silent frontier of practical LLM orchestration.
5. Standardized Benchmarks Reward Recall, Business Needs Precision
Spider and BIRD reward semantic intent alignment. But real enterprises want correct queries that run and reconcile. Your results highlight a mismatch: what research calls a win isn’t what finance calls working SQL.
Problem 2 - LLM-Driven Data Analysis
While writing SQL isn’t the finish line. In real-world workflows, the goal is insight, not just a table of results.
Once data is retrieved, the next step is interpreting it. This is where LLMs can completely fall apart.
Hallucinations and Hand-Waving
When asked to “analyze the results,” LLMs fall into one of three traps - as was seen in the case with Pandas AI:
Fluff: Generic summaries that repeat column names without value
Hallucination: Making up patterns or trends not present in the data
Inconsistency: Interpreting different samples of the data during each run, yielding different outputs
Overreach: Trying to interpret raw tables without precise math
In domains like finance, this is worse than useless - it can be misleading, even dangerous.
Use the LLM as a semantic orchestrator, not a calculator.
Sample Architecture for Data Analysis
To make LLMs truly effective in structured, high-stakes business domains like finance, we need to go beyond toy examples. Agentic orchestration is required to get a truly useful and accurate output. Query decomposition, SQL generation, computation, validation, and insight synthesis.
The architecture below outlines some of the key pieces in this approach. Each layer is designed to mitigate the core weaknesses of LLMs - context limitations, probabilistic reasoning, and weak numeracy - by delegating critical tasks to deterministic tools or structured prompts.
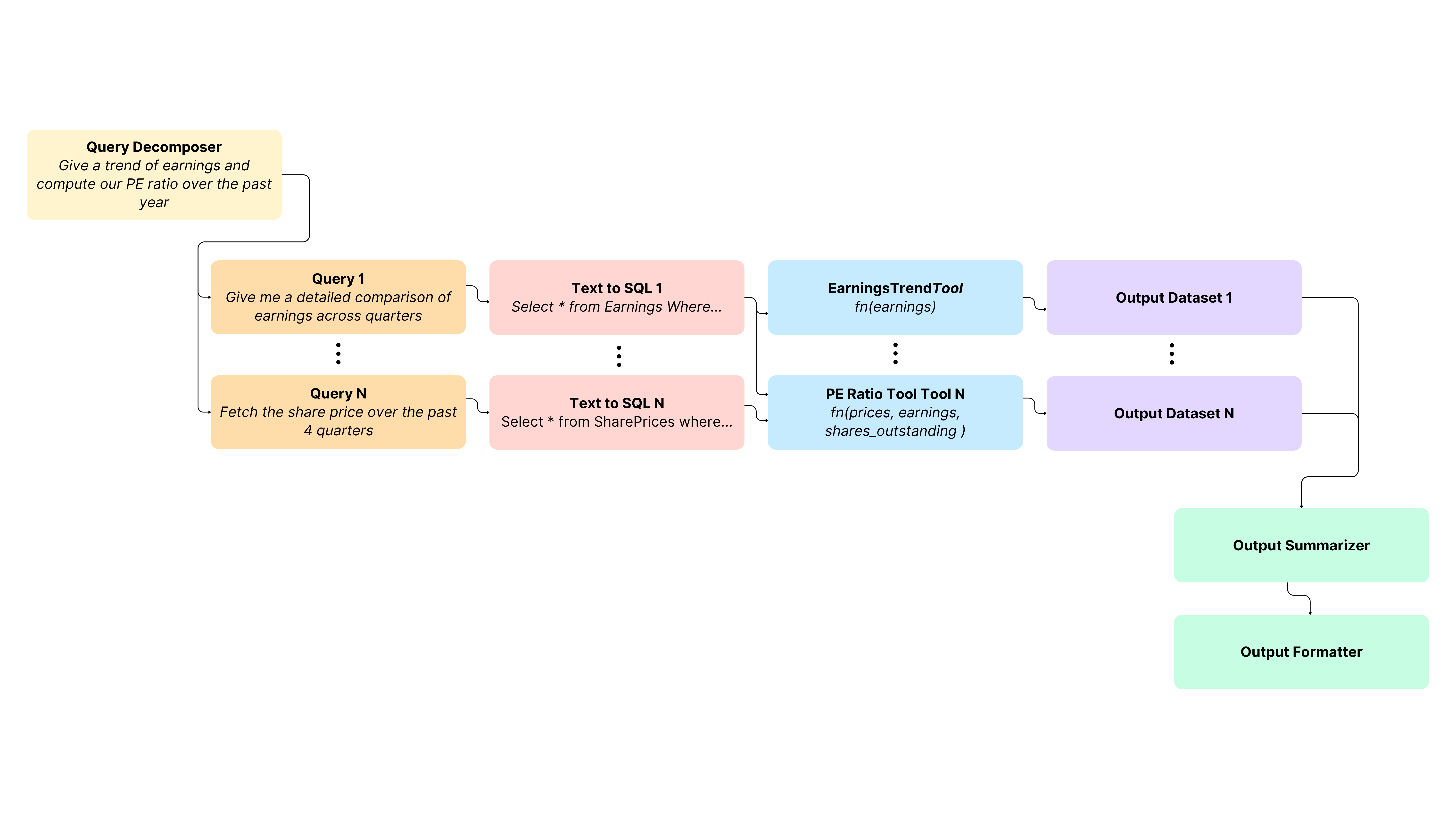
1. Query Decomposer
Function: Breaks the abstract user question into multiple concrete sub-queries.
Example Decompositions:
Query 1: "Give me a detailed comparison of earnings across quarters"
Query N: "Fetch the share price over the past 4 quarters"
2. Text-to-SQL Translator (for each sub-query)
Role: Converts each natural language sub-query into SQL.
Example Output:
"SELECT * FROM Earnings WHERE quarter IN (...)""SELECT * FROM SharePrices WHERE date BETWEEN (...)"
These are schema-aware and context-sensitive, possibly enhanced by few-shot or retrieval-augmented techniques.
3. Tool Execution Layer
Each SQL query feeds into specialized computation tools:
EarningsTrendTool: Analyzes time series earnings to detect trends (e.g., growth, decline).
PE Ratio Tool: Computes price-to-earnings ratio using fetched prices, earnings, and share count.
4. Output Datasets
Result: Each tool produces structured datasets (e.g., quarterly earnings trends, PE ratio breakdowns).
These outputs are modular and could be reused or chained downstream.
5. Output Summarizer
Function: Synthesizes insights from multiple output datasets into a coherent narrative or analytic summary.
Example: “Earnings have increased 12% YoY; PE ratio peaked in Q2 due to share price surge.”
6. Output Formatter
Final step: Translates the summarized analysis into the desired output format: a report, chart, dashboard, or structured response depending on the interface.
A Quick Note on Data Pre-Processing
A recurring question: “Can I just throw raw data into an LLM and skip the cleaning step?” That’s a hard no.
However, LLMs are good at semantic standardization. They can:
Normalize labels (e.g.
"U.S.A."→"United States")Suggest corrections for typos
Propose date or currency format conversions
Generate imputation strategies based on other columns
Create cleaning reports: “Column C has 3 inconsistent date formats and 2 outliers”
✅ You can prompt:
“Standardize these country values to their ISO common name: [‘USA’, ‘U.S.A.’, ‘America’, ‘United States’]”
Preprocess Your Data
Despite these tools, LLMs aren’t replacements for:
Deterministic data validation
Schema enforcement
Reproducible cleaning pipelines
LLMs are assistants, not substitutes, for preprocessing. They help detect, describe, and suggest - but human-in-the-loop review is still essential.
Conclusions: Making LLMs Work for Big, Structured, Financial Data
LLMs can be powerful collaborators, but only when used deliberately.
✅ What Works:
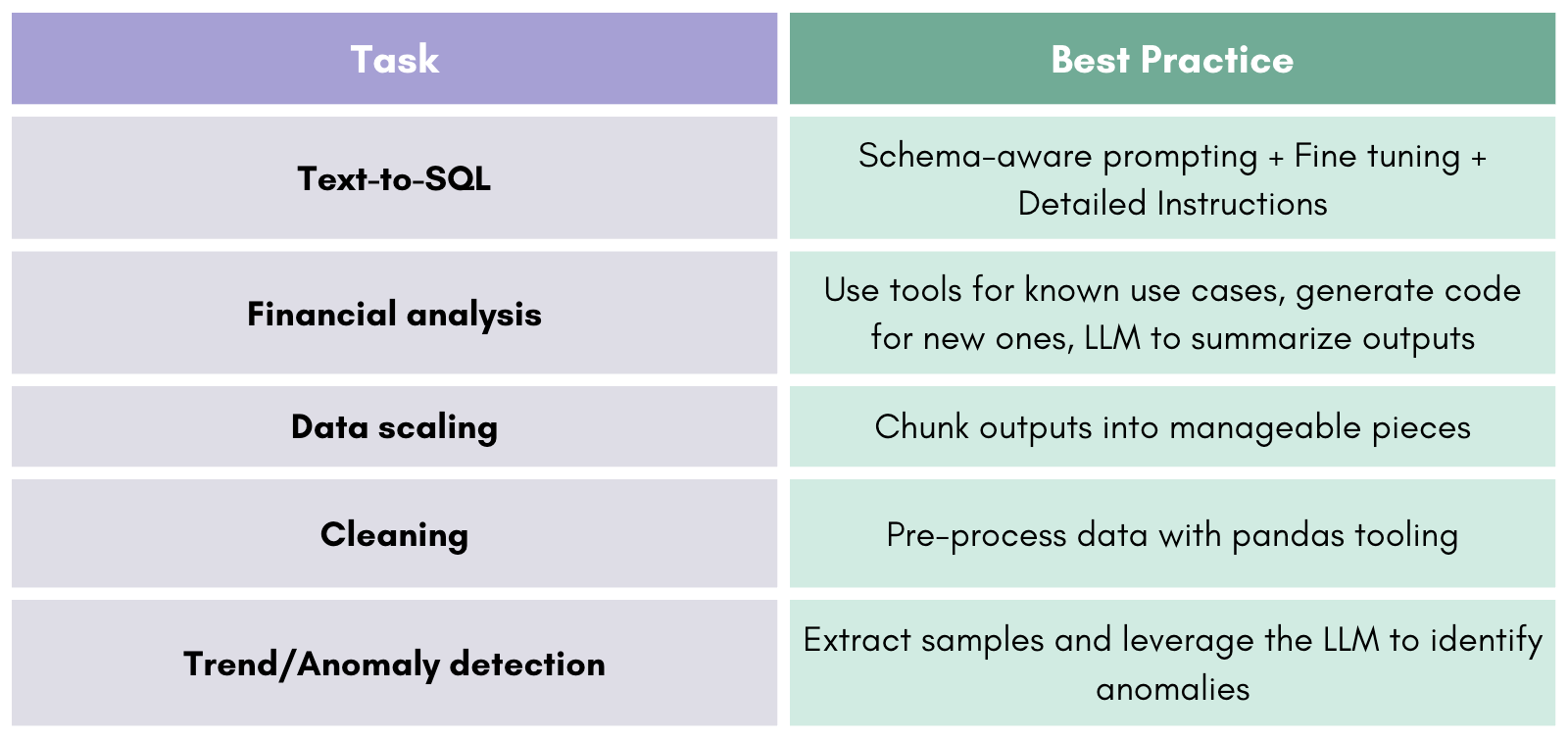
Query Translation
LLMs are effective at turning natural language into SQL—when schema-aware, prompt-tuned, or paired with retrieval/fine-tuning.Insight Summarization
LLMs can explain outputs, identify trends, and craft readable narratives—if fed structured, validated results.Error Detection & Recovery
Prompting with model feedback (e.g., SQL error traces) enhances performance beyond what benchmarks test.Semantic Assistance in Preprocessing
LLMs are helpful for cleaning tasks like label normalization, typo correction, and formatting suggestions—not replacements for ETL.
⚠️ What Doesn’t Work:
End-to-End Analysis in One Prompt
Raw data in, insights out = hallucination risk and low reproducibility.Generic Prompting
Without schema awareness or contextual examples, SQL output is often wrong or incomplete.Financial Domain Blind Spots
Open-source models often fail on business logic, KPIs, and temporal joins not seen in training data.Small-Scale Fine-Tuning
Tiny datasets may teach partial logic without teaching correctness—leading to confident but wrong outputs.
Final Takeaway:
Treat the LLM as an orchestrator, not the engine.
Build modular, schema-aware systems where LLMs drive query generation, assist in interpretation, and summarize cleanly - but let validated tools handle the math, filtering, and computation. That’s the only path to reliable, auditable, and insightful use of LLMs in financial analytics.
One of your best deep dives yet. I love how you laid out the difference between leaderboard wins and real-world SQL robustness—so relatable for anyone actually deploying this stuff!